How to Instantly Publish Data to the Internet with Datasette
I presented a session about Datasette at the PyBay 2018 conference in San Francisco. I talked about the project itself and demonstrated ways of creating and publishing databases using csvs-to-sqlite, Datasette Publish and my new sqlite-utils library.

Slides and notes from my presentation on Datasette given at PyBay 2018 on 19th August 2018.

I designed Datasette based on my experence working as a data journalist at the Guardian newspaper in London.
One of the projects I was involved with at the Guardian was the Guardian Data Blog.
Simon Rogers was the journalist most responsible for gathering the data used for infographics in the newspaper. We decided to start publishing the raw data on a blog.
After some consideration of our options, we ended up chosing Google Spreadsheets as a publishing tool.
This worked really well: it was easy to publish data, and a community of readers grew up around the data that was being published who built their own analyses and visualizations on top of the data that was shared.
We even had a Flickr group where people shared their work.

But was Google Sheets really the best way to publish this kind of data? I wanted something better. Last year I realized that the pieces were now available to solve this problem in a much more elegant way.

GitHub: simonw/datasette
Documentation: datasette.readthedocs.io
Updates on my blog: simonwillison.net/tags/datasette/
Let’s start with an example. FiveThirtyEight publish a large number of high quality data journalism articles.
Recent example: We Researched Hundreds Of Races. Here’s Who Democrats Are Nominating.
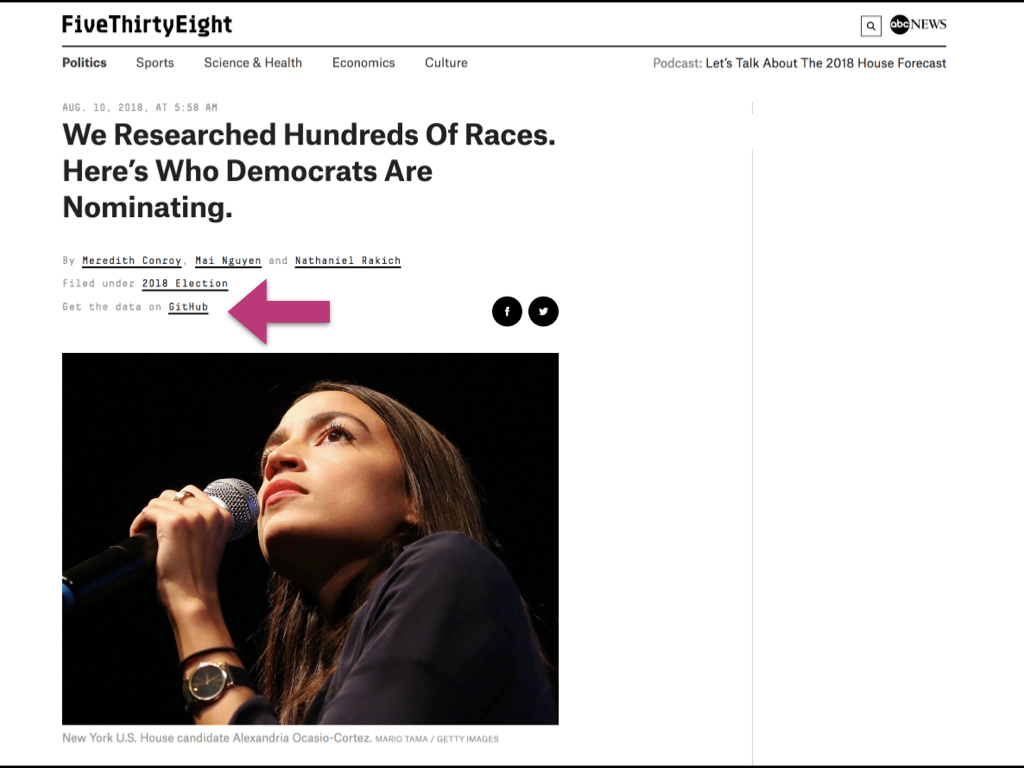
And they have a link... Get the data on GitHub
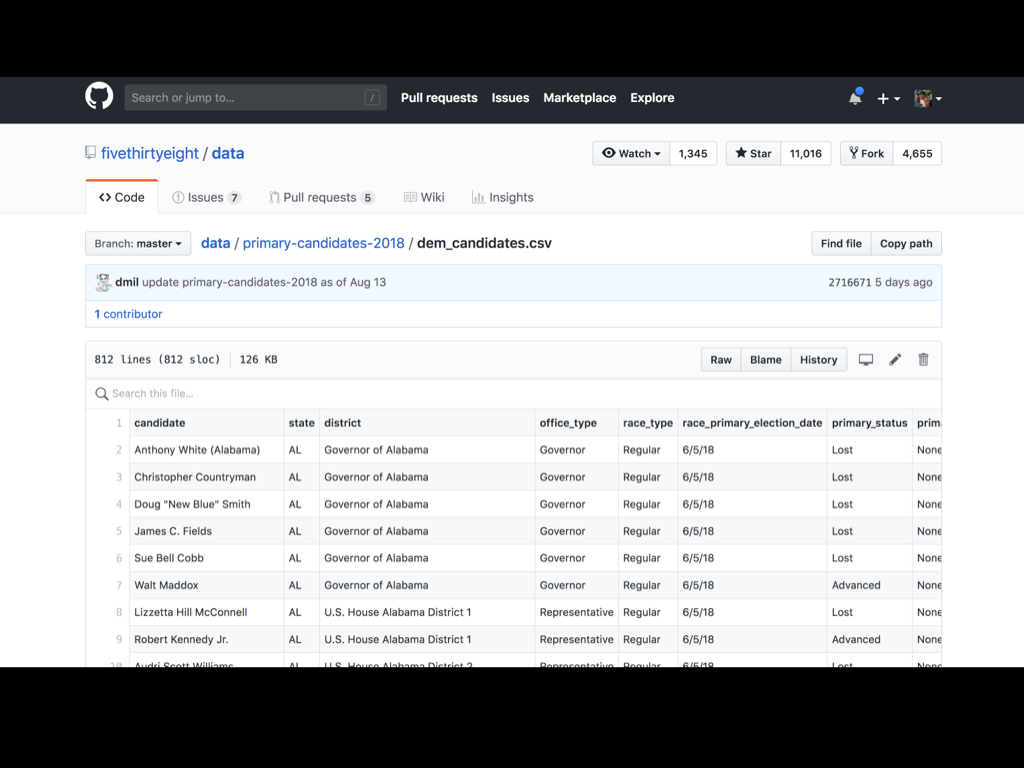
The fivethirtyeight/data repository on GitHub is an incredible collection of over 400 CSV files containing the data behind their stories.
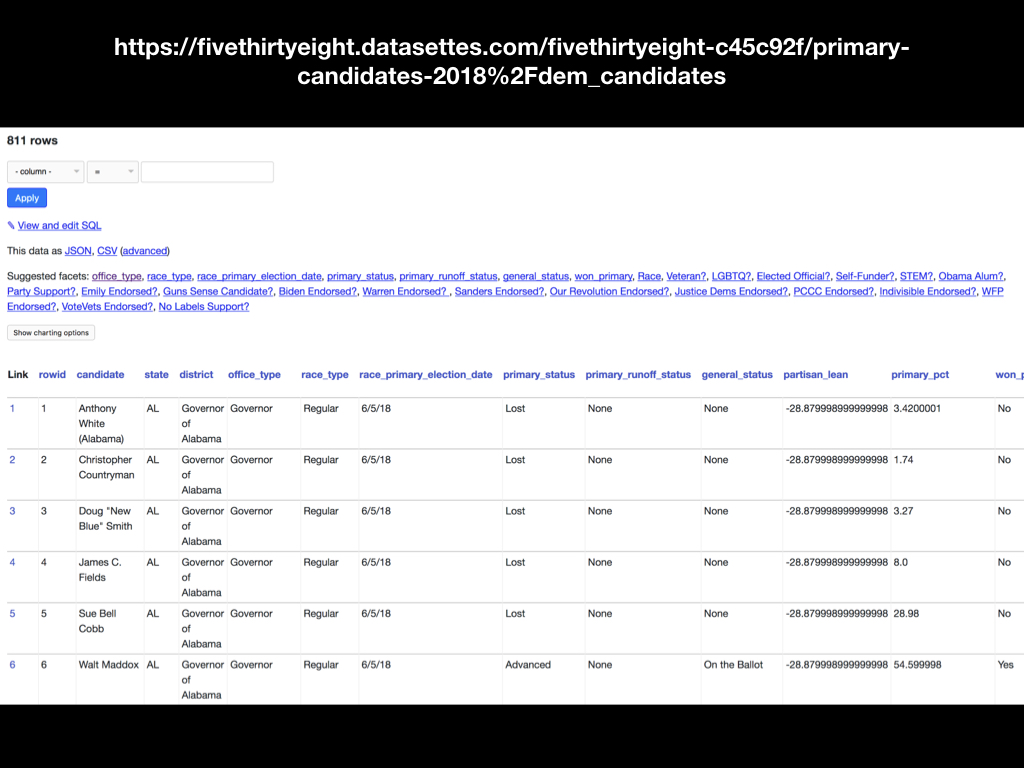
I have a daily Travis CI job which grabs their repository, converts the CSV files to SQLite and deploys them to a Datasette instance running at fivethirtyeight.datasettes.com.
Here’s the data from that story.

One of the most interesting features of Datasette is its ability to add faceted browse to any table.
Here I’m faceting the candidates by state, office_type, won_primary, primary_status and Race

I also demonstrated the ability to apply fiters, export the data as JSON or CSV and execute custom SQL queries (the results of which can also be exported).

SQLite is an incredibly embedded database library.
It runs basically everywhere. It’s in my watch, on my phone, on my laptop, embedded in a huge variety of applications.
It has a bunch of interesting characteristics which Datasette takes full advantage of.

You can install the Datasette command-line utility from PyPI.

I said SQLite was ubiquitous: let’s prove it.
Run find ~/Library -iname ’*.sqlite*’ to see some of the SQLite databases that applications have created on your OS X laptop.
I get several hundred! Firefox, Chrome and Safari all use SQLite for bookmarks and history, and applications that use it include Evernote, 1Password and many others.

find ~/Library -iname ’*.sqlite*’ -type f -exec du -h {} + | sort -r -h
This command sorts those database files by the largest first. On my machine, the largest SQLite database is:
49M /Users/simonw/Library/Containers/com.apple.photoanalysisd/Data/Library/Caches/CLSBusinessCategoryCache.sqlite

I ran datasette against this file and showed how it allowed me to explore it via https://127.0.0.1:8001/
datasette /Users/simonw/Library/Containers/com.apple.photoanalysisd/Data/Library/Caches/CLSBusinessCategoryCache.sqlite
Since I had the datasette-cluster-map plugin installed I could run the custom SQL query select *, zlatitude as latitude, zlongitude as longitude from ZENTRY to see everywhere I have been in the past few years rendered on a map.

So that’s how to explore an existing SQLite database... but how can we go about creating them?

csvs-to-sqlite is a simple command-line tool I wrote which converts CSV files into a SQLite database (using Pandas under the hood).
But where can we get interesting CSV data?
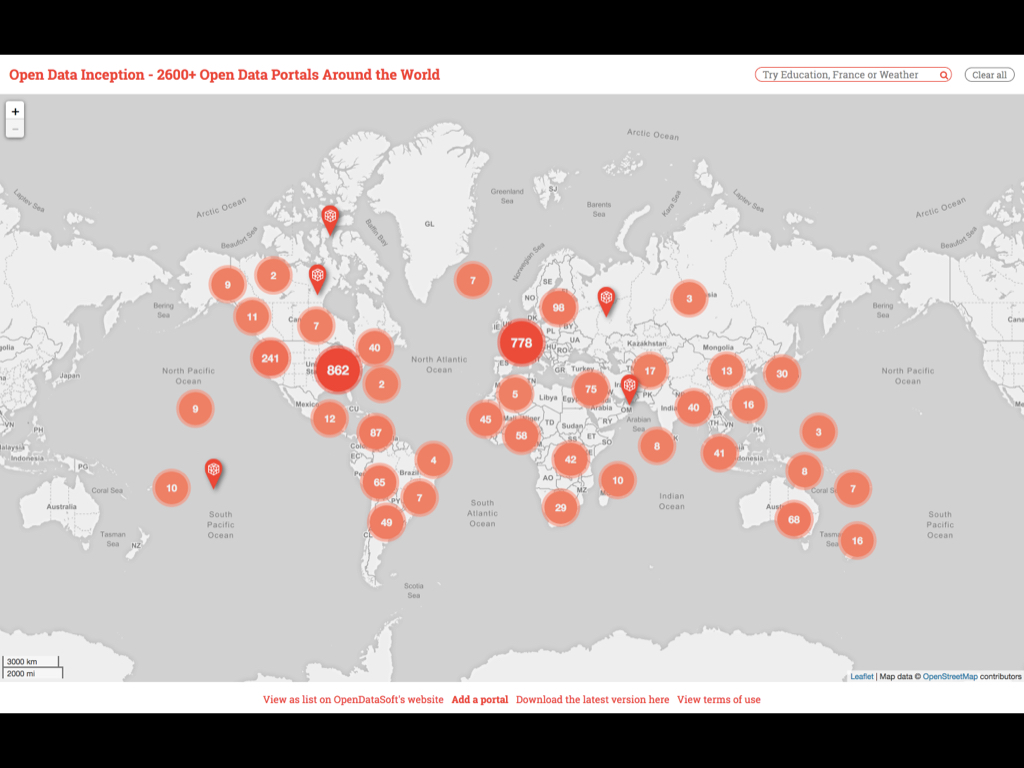
It turns out that the worldwide campaign for more open data and transparency in government has worked beyond our wildest dreams.
This website lists over 2,600 open data portals run by local governments around the world!
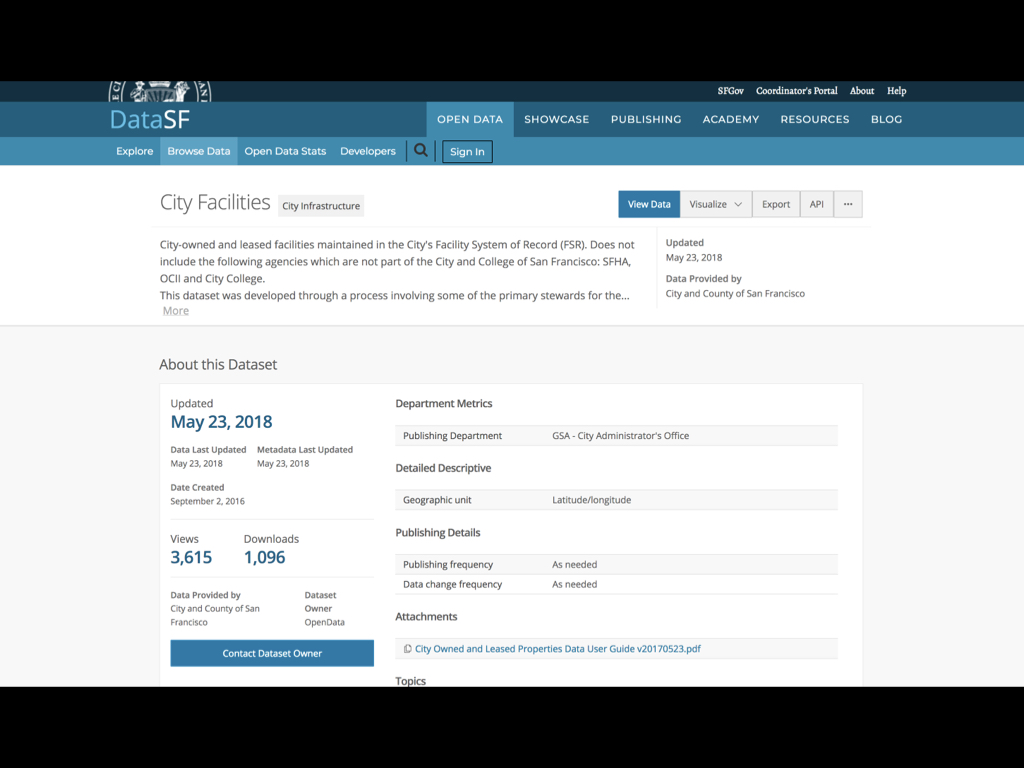
San Francisco’s open data portal is at datasf.org. It has 469 datasets!
Here’s a recent example (updated in May): it’s a list of all of the buildings and facilities owned by the city.

I exported the data as CSV and used csvs-to-sqlite to convert it into a SQLite database:
csvs-to-sqlite City_Facilities.csv facilities.db
Then I used Datasette to browse the file locally:
datasette facilities.db

How can we publish it to the internet?
The datasette publish subcommand (documented here) knows how to upload a database to a hosting platform and configure Datasette to run against that file.
It currently works with both Zeit Now and Heroku, and further publishers can be supported via a plugin hook.
datasette publish now facilities.db
This outputs the URL to the new deployment. A few minutes later the instance is available for anyone to browse or build against.

What if you don’t want to install any software?
Datasette Publish is a web application which lets you authenticate against your (free) Zeit Now hosting account, then upload CSVs and convert and deploy them using Datasette.
Crucially, the deployment happens to our own hosting account: I’m not responsible for hosting your data.
More about Datasette Publish on my blog.
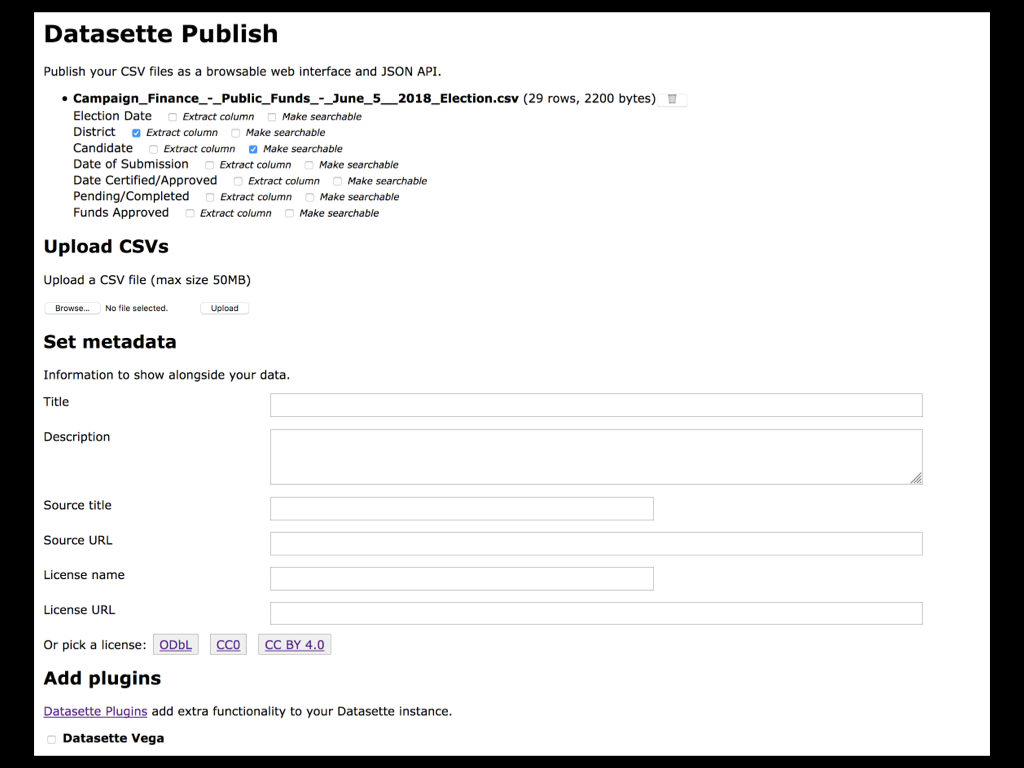
I used Datasette Publish to upload the City_Facilities.csv file and deploy it along with the datasette-cluster-map plugin.
Here’s the demo I deployed: san-francisco-facilities.now.sh.

What if your data isn’t a CSV?
Recently, I’ve been working on a new package called sqlite-utils (documentation here) which aims to make creating new SQLite databases as productive as possible.

It’s designed to work well in Jupyter notebooks.
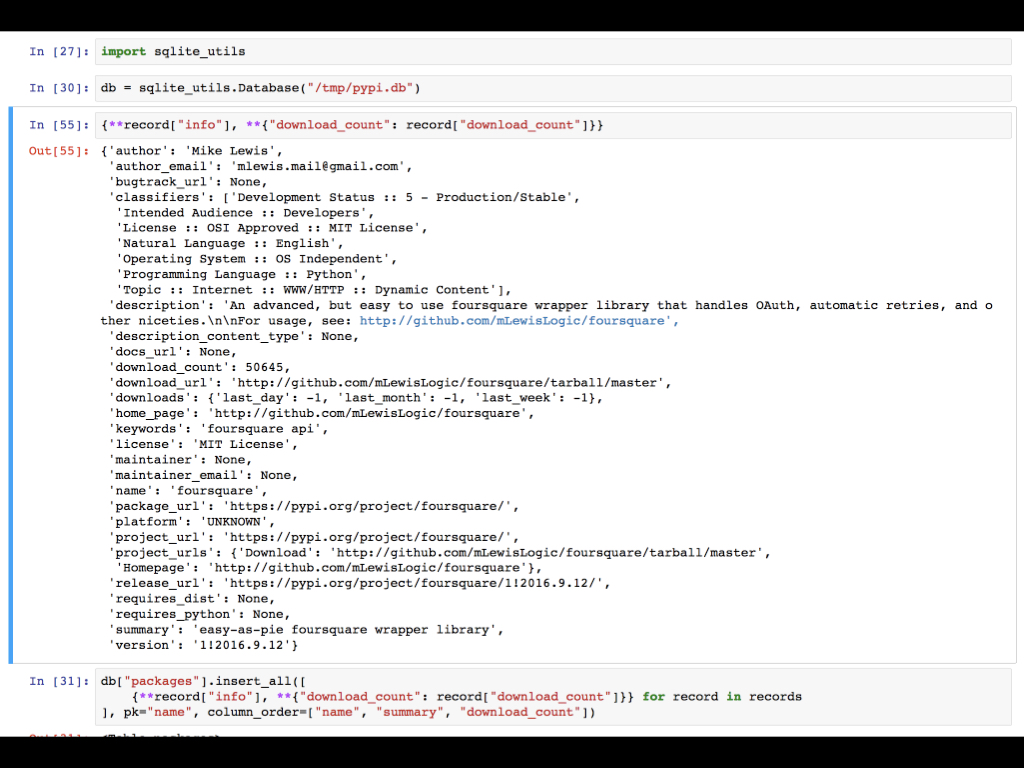
I demonstrated a notebook which pulls the list of the top downloaded PyPI packages from this site, then pulls package details from PyPI’s JSON API and creates a SQLite database combining data from the two sources.
Here’s the notebook I used.

Datasette supports plugins.
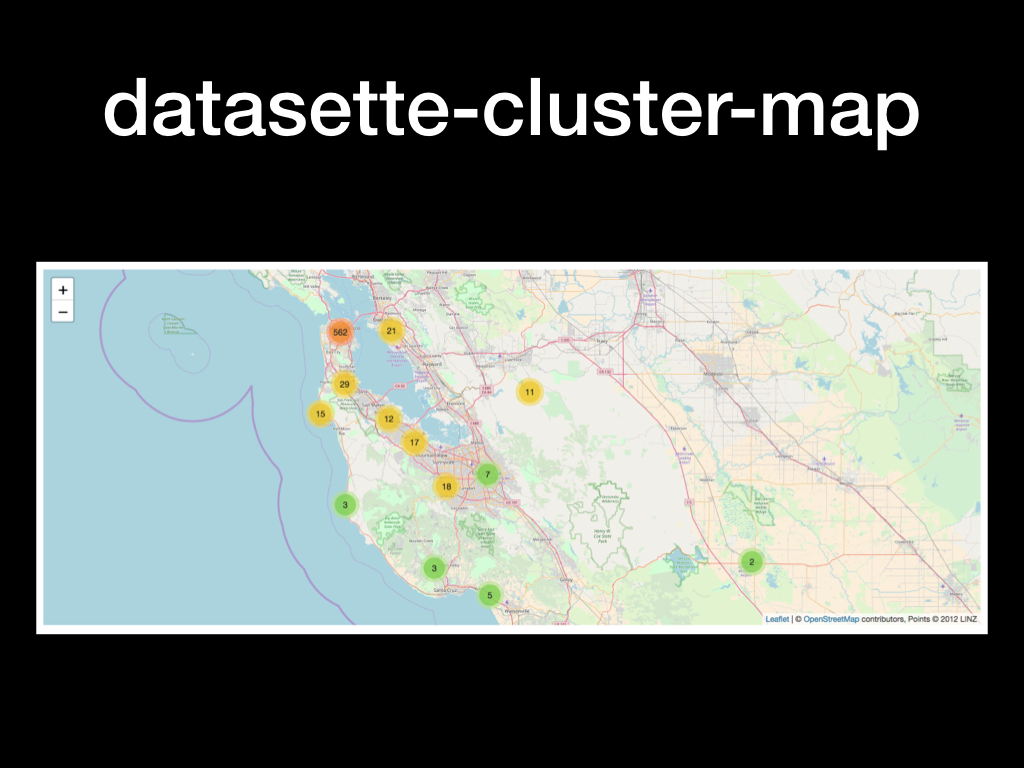
I’ve already demonstrated this plugin a couple of times.
It looks for any columns named latitude and longitude and, if it finds any, it renders those points on a map.

If you install the plugin globally (or into a virtual environment) it will load any time you run Datasette.

You can pass the name of a plugin to the datasette publish --install option to cause it to be installed with that deployment.
The Datasette Publish web app allows you to deploy specific plugins by clicking their checkbox.
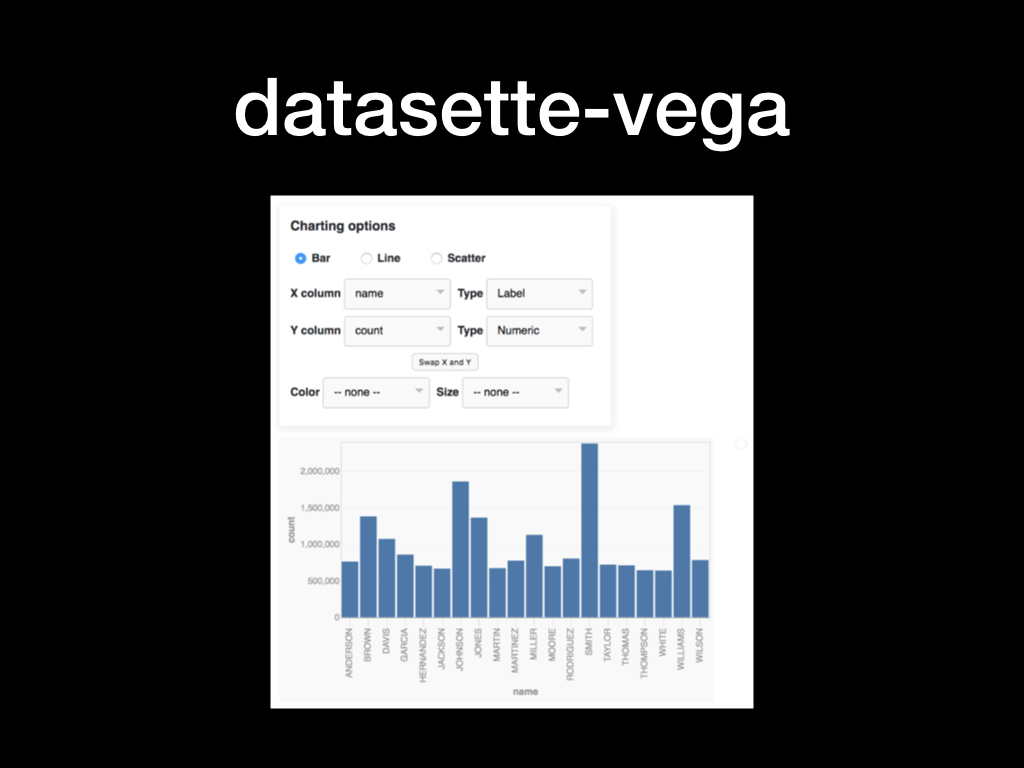
Datasette Vega is a plugin that uses the excellent Vega visualization library to enable charts against any Datasette table or query.

I have a whole load of plans for improvements to Datasette and the Datasette ecosystem.

The next feature I’m working on is better support for many-to-many relationships. You can track that here.

SpatiaLite is a powerful extension for SQLite that adds comprehensive support for GIS features such as polygon operations and spatial indexing.
I wrote more about it in Building a location to time zone API with SpatiaLite, OpenStreetMap and Datasette. I’m excited about using it to further extend Datasette’s geospatial abilities.

SQLite 3.25 is due out in September and will be adding support for window functions, a powerful set of tools for running complex analytical queries, especially against time series data.
I’m excited about exploring these further in Datasette. For the moment I have a demo running at pysqlite3-datasette.now.sh.

I don’t have a timeline for Datasette 1.0 yet, but it will represent the point at which I consider the Plugin mechanism to be stable enough that people can write plugins without fear of them breaking with future (non-2.0) updates.
So please, take a look at the plugin mechanism and let me know if it supports your needs!


The more people using Datasette and giving me feedback on how it can improve the better.

Recent articles
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026