Datasette on Codespaces, sqlite-utils API reference documentation and other weeknotes
14th August 2021
This week I broke my streak of not sending out the Datasette newsletter, figured out how to use Sphinx for Python class documentation, worked out how to run Datasette on GitHub Codespaces, implemented Datasette column metadata and got tantalizingly close to a solution for an elusive Datasette feature.
API reference documentation for sqlite-utils using Sphinx
I’ve never been a big fan of Javadoc-style API documentation: I usually find that documentation structured around classes and methods fails to show me how to actually use those classes to solve real-world problems. I’ve tended to avoid it for my own projects.
My sqlite-utils Python library has a ton of functionality, but it mainly boils down to two classes: Database and Table. Since it already has pretty comprehesive narrative documentation explaining the different problems it can solve, I decided to try experimenting with the Sphinx autodoc module to produce some classic API reference documentation for it:

Since autodoc works from docstrings, this was also a great excuse to add more comprehensive docstrings and type hints to the library. This helps tools like Jupyter notebooks and VS Code display more useful inline help.
This proved to be time well spent! Here’s what sqlite-utils looks like in VS Code now:
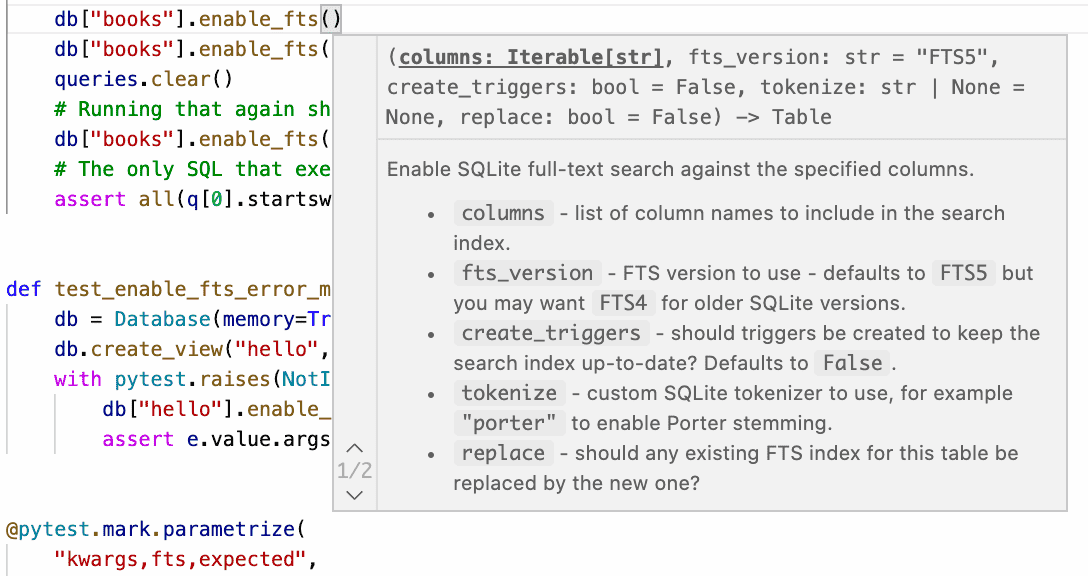
Running mypy against the type hints also helped me identify and fix a couple of obscure edge-case bugs in the existing methods, detailed in the 3.15.1 release notes. It’s taken me a few years but I’m finally starting to come round to Python’s optional typing as being worth the additional effort!
Figuring out how to use autodoc in Sphinx, and then how to get the documentation to build correctly on Read The Docs took some effort. I wrote up what I learned in this TIL.
Datasette on GitHub Codespaces
GitHub released their new Codespaces online development environments to general availability this week and I’m really excited about it. I ran a team at Eventbrite for a while resonsible for development environment tooling and it really was shocking how much time and money was lost to broken local development environments, even with a significant amount of engineering effort applied to the problem.
Codespaces promises a fresh, working development environment on-demand any time you need it. That’s a very exciting premise! Their detailed write-up of how they convinced GitHub’s own internal engineers to move to it is full of intriguing details—getting an existing application working with it is no small feat, but the pay-off looks very promising indeed.
So... I decided to try and get Datasette running on it. It works really well!
You can run Datasette in any Codespace environment using the following steps:
- Open the terminal. Three-bar-menu-icon, View, Terminal does the trick.
- In the terminal run
pip install datasette datasette-x-forwarded-host(more on this in a moment). - Run
datasette—Codespaces will automatically setup port forwarding and give you a link to “Open in Browser”—click the link and you’re done!
You can pip install sqlite-utils and then use sqlite-utils insert to create SQLite databases to use with Datasette.
There was one catch: the first time I ran Datasette, clicking on any of the internal links within the web application took me to http://localhost/ pages that broke with a 404.
It turns out the Codespaces proxy sends a host: localhost header—which Datasette then uses to incorrectly construct internal URLs.
So I wrote a tiny ASGI plugin, datasette-x-forwarded-host, which takes the incoming X-Forwarded-Host provided by Codespaces and uses that as the Host header within Datasette itself. After that everything worked fine.
sqlite-utils insert --flatten
Early this week I finally figured out Cloud Run logging. It’s actually really good! In doing so, I worked out a convoluted recipe for tailing the JSON logs locally and piping them into a SQLite database so that I could analyze them with Datasette.
Part of the reason it was convoluted is that Cloud Run logs feature nested JSON, but sqlite-utils insert only works against an array of flat JSON objects. I had to use this jq monstrosity to flatten the nested JSON into key/value pairs.
Since I’ve had to solve this problem a few times now I decided to improve sqlite-utils to have it do the work instead. You can now use the new --flatten option like so:
sqlite-utils insert logs.db logs log.json --flatten
To create a schema that flattens nested objects into a topkey_nextkey structure like so:
CREATE TABLE [logs] (
[httpRequest_latency] TEXT,
[httpRequest_requestMethod] TEXT,
[httpRequest_requestSize] TEXT,
[httpRequest_status] INTEGER,
[insertId] TEXT,
[labels_service] TEXT
);Full documentation for --flatten.
Datasette column metadata
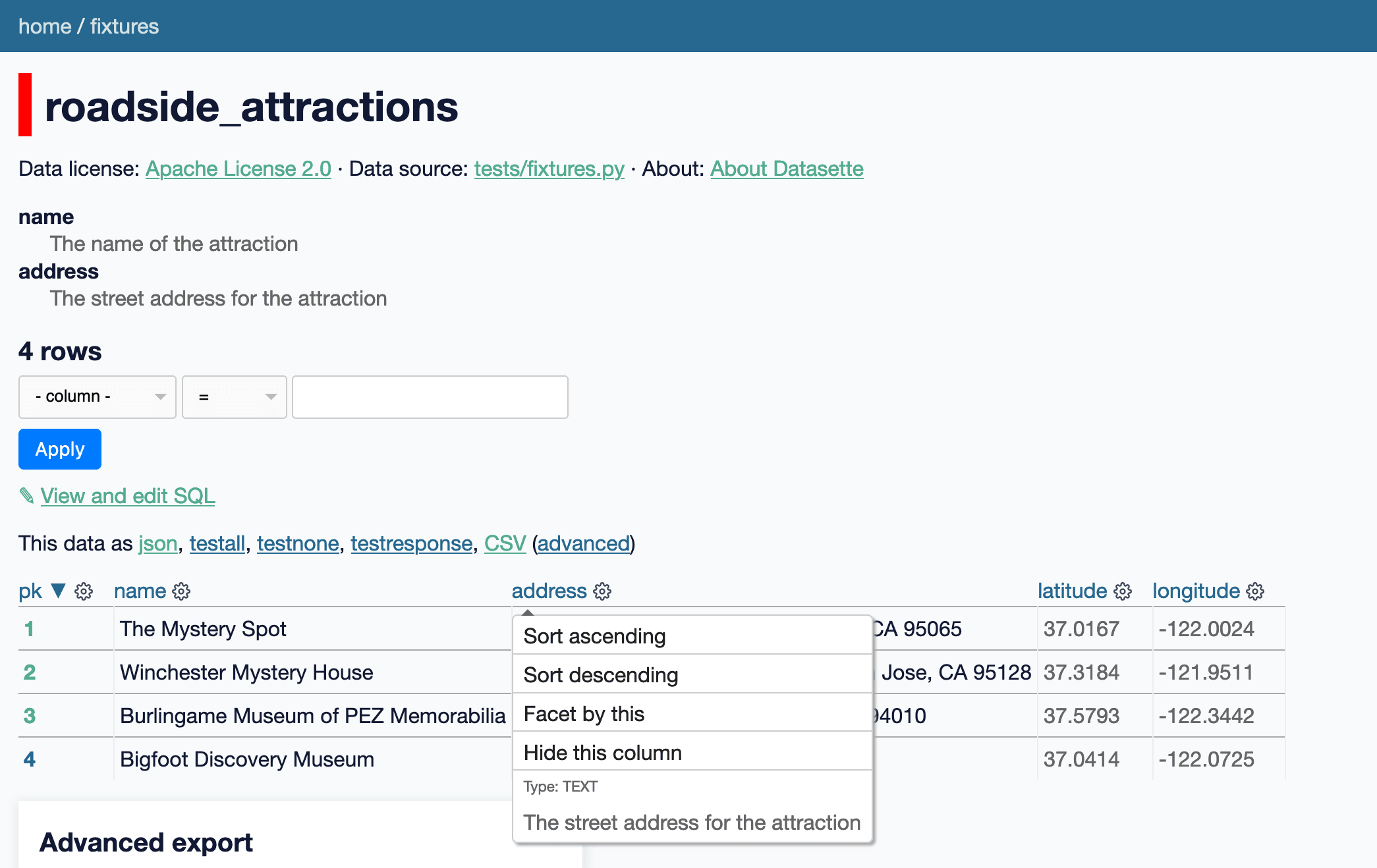
I’ve been wanting to add this for a while: Datasette’s main branch now includes an implementation of column descriptions metadata for Datasette tables. This is best illustrated by a screenshot (of this live demo):
You can add the following to metadata.yml (or .json) to specify descriptions for the columns of a given table:
databases:
fixtures:
roadside_attractions:
columns:
name: The name of the attraction
address: The street address for the attractionColumn descriptions will be shown in a <dl> at the top of the page, and will also be added to the menu that appears when you click on the cog icon at the top of a column.
Getting closer to query column metadata, too
Datasette lets you execute arbitrary SQL queries, like this one:
select
roadside_attractions.name,
roadside_attractions.address,
attraction_characteristic.name
from
roadside_attraction_characteristics
join roadside_attractions on roadside_attractions.pk = roadside_attraction_characteristics.attraction_id
join attraction_characteristic on attraction_characteristic.pk = roadside_attraction_characteristics.characteristic_idYou can try that here. It returns the following:
| name | address | name |
|---|---|---|
| The Mystery Spot | 465 Mystery Spot Road, Santa Cruz, CA 95065 | Paranormal |
| Winchester Mystery House | 525 South Winchester Boulevard, San Jose, CA 95128 | Paranormal |
| Bigfoot Discovery Museum | 5497 Highway 9, Felton, CA 95018 | Paranormal |
| Burlingame Museum of PEZ Memorabilia | 214 California Drive, Burlingame, CA 94010 | Museum |
| Bigfoot Discovery Museum | 5497 Highway 9, Felton, CA 95018 | Museum |
The columns it returns have names... but I’ve long wanted to do more with these results. If I could derive which source columns each of those output columns were, there are a bunch of interesting things I could do, most notably:
- If the output column is a known foreign key relationship, I could turn it into a hyperlink (as seen on this table page)
- If the original table column has the new column metadata, I could display that as additional documentation
The challenge is: given an abitrary SQL query, how can I figure out what the resulting columns are going to be and how to tie those back to the original tables?
Thanks to a hint from the SQLite forum I’m getting tantalizingly close to a solution.
The trick is to horribly abuse SQLite’s explain output. Here’s what it looks like for the example query above:
| addr | opcode | p1 | p2 | p3 | p4 | p5 | comment |
|---|---|---|---|---|---|---|---|
| 0 | Init | 0 | 15 | 0 | 0 | ||
| 1 | OpenRead | 0 | 47 | 0 | 2 | 0 | |
| 2 | OpenRead | 1 | 45 | 0 | 3 | 0 | |
| 3 | OpenRead | 2 | 46 | 0 | 2 | 0 | |
| 4 | Rewind | 0 | 14 | 0 | 0 | ||
| 5 | Column | 0 | 0 | 1 | 0 | ||
| 6 | SeekRowid | 1 | 13 | 1 | 0 | ||
| 7 | Column | 0 | 1 | 2 | 0 | ||
| 8 | SeekRowid | 2 | 13 | 2 | 0 | ||
| 9 | Column | 1 | 1 | 3 | 0 | ||
| 10 | Column | 1 | 2 | 4 | 0 | ||
| 11 | Column | 2 | 1 | 5 | 0 | ||
| 12 | ResultRow | 3 | 3 | 0 | 0 | ||
| 13 | Next | 0 | 5 | 0 | 1 | ||
| 14 | Halt | 0 | 0 | 0 | 0 | ||
| 15 | Transaction | 0 | 0 | 35 | 0 | 1 | |
| 16 | Goto | 0 | 1 | 0 | 0 |
The magic is on line 12: ResultRow 3 3 means “return a result that spans three columns, starting at register 3”—so that’s register 3, 4 and 5. Those three registers are populated by the Column operations on line 9, 10 and 11 (the register they write into is in the p3 column). Each Column operation specifies the table (as p1) and the column index within that table (p2). And those table references map back to the OpenRead lines at the start, where p1 is that table register (referered to by Column) and p1 is the root page of the table within the schema.
Running select rootpage, name from sqlite_master where rootpage in (45, 46, 47) produces the following:
| rootpage | name |
|---|---|
| 45 | roadside_attractions |
| 46 | attraction_characteristic |
| 47 | roadside_attraction_characteristics |
Tie all of this together, and it may be possible to use explain to derive the original tables and columns for each of the outputs of an arbitrary query!
I was almost ready to declare victory, until I tried running it against a query with an order by column at the end... and the results no longer matched up.
You can follow my ongoing investigation here—the short version is that I think I’m going to have to learn to decode a whole bunch more opcodes before I can get this to work.
This is also a very risk way of attacking this problem. The SQLite documentation for the bytecode engine includes the following warning:
This document describes SQLite internals. The information provided here is not needed for routine application development using SQLite. This document is intended for people who want to delve more deeply into the internal operation of SQLite.
The bytecode engine is not an API of SQLite. Details about the bytecode engine change from one release of SQLite to the next. Applications that use SQLite should not depend on any of the details found in this document.
So it’s pretty clear that this is a highly unsupported way of working with SQLite!
I’m still tempted to try it though. This feature is very much a nice-to-have: if it breaks and the additional column context stops displaying it’s not a critical bug—and hopefully I’ll be able to ship a Datasette update that takes into account those breaking SQLite changes relatively shortly afterwards.
If I can find another, more supported way to solve this I’ll jump on it!
In the meantime, I did use this technque to solve a simpler problem. Datasette extracts :named parameters from arbitrary SQL queries and turns them into form fields—but since it uses a simple regular expression for this it could be confused by things like a literal 00:04:05 time string contained in a SQL query.
The explain output for that query includes the following:
| addr | opcode | p1 | p2 | p3 | p4 | p5 | comment |
|---|---|---|---|---|---|---|---|
| ... | ... | ... | ... | ... | ... | ... | ... |
| 27 | Variable | 1 | 12 | 0 | :text | 0 |
So I wrote some code which uses explain to extract just the p4 operands from Variable columns and treats those as the extracted parameters! This feels a lot safer than the more complex ResultRow/Column logic—and it also falls back to the regular expression if it runs into any SQL errors. More in the issue.
TIL this week
- Tailing Google Cloud Run request logs and importing them into SQLite
- Find local variables in the traceback for an exception
- Adding Sphinx autodoc to a project, and configuring Read The Docs to build it
Releases this week
-
datasette-x-forwarded-host: 0.1—2021-08-12
Treat the X-Forwarded-Host header as the Host header -
sqlite-utils: 3.15.1—(84 releases total)—2021-08-10
Python CLI utility and library for manipulating SQLite databases -
datasette-query-links: 0.1.2—(3 releases total)—2021-08-09
Turn SELECT queries returned by a query into links to execute them -
datasette: 0.59a1—(96 releases total)—2021-08-09
An open source multi-tool for exploring and publishing data -
datasette-pyinstrument: 0.1—2021-08-08
Use pyinstrument to analyze Datasette page performance
More recent articles
- Meta's new model is Muse Spark, and meta.ai chat has some interesting tools - 8th April 2026
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026