Weeknotes: Parallel SQL queries for Datasette, plus some middleware tricks
27th April 2022
A promising new performance optimization for Datasette, plus new datasette-gzip and datasette-total-page-time plugins.
Parallel SQL queries in Datasette
From the start of the project, Datasette has been built on top of Python’s asyncio capabilities—mainly to benefit things like streaming enormous CSV files.
This week I started experimenting with a new way to take advantage of them, by exploring the potential to run multiple SQL queries in parallel.
Consider this Datasette table page:
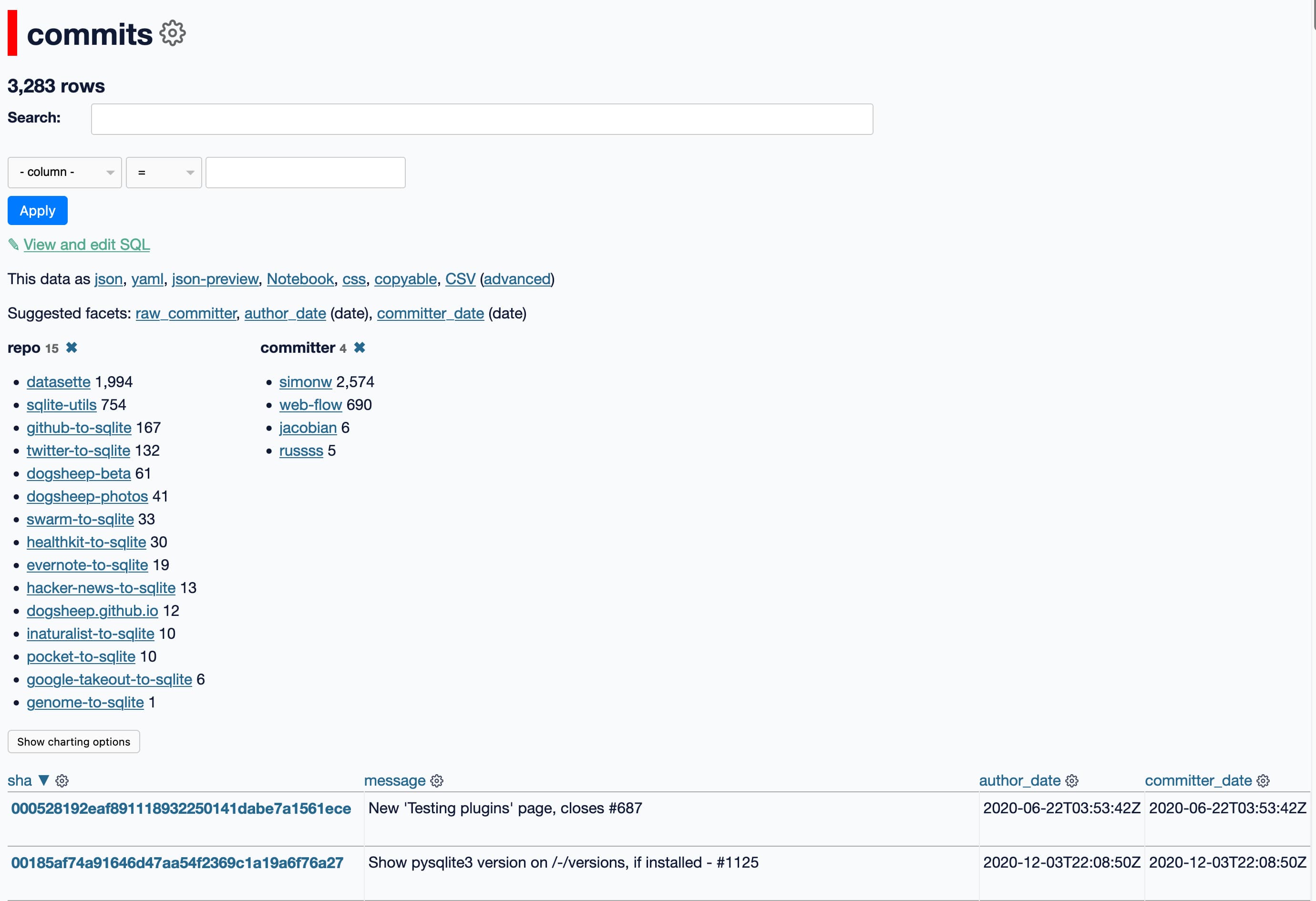
That page has to execute quite a few SQL queries:
- A
select count(*) ...to populate the 3,283 rows heading at the top - Queries against each column to decide what the “suggested facets” should be (details here)
- For each of the selected facets (in this case
reposandcommitter) aselect name, count(*) from ... group by name order by count(*) descquery - The actual
select * from ... limit 101query used to display the actual table
It ends up executing more than 30 queries! Which may seem like a lot, but Many Small Queries Are Efficient In SQLite.
One thing that’s interesting about the above list of queries though is that they don’t actually have any dependencies on each other. There’s no reason not to run all of them in parallel—later queries don’t depend on the results from earlier queries.
I’ve been exploring a fancy way of executing parallel code using pytest-style dependency injection in my asyncinject library. But I decided to do a quick prototype to see what this would look like using asyncio.gather().
It turns out that simpler approach worked surprisingly well!
You can follow my research in this issue, but the short version is that as-of a few days ago the Datasette main branch runs many of the above queries in parallel.
This trace (using the datasette-pretty-traces plugin) illustrates my initial results:
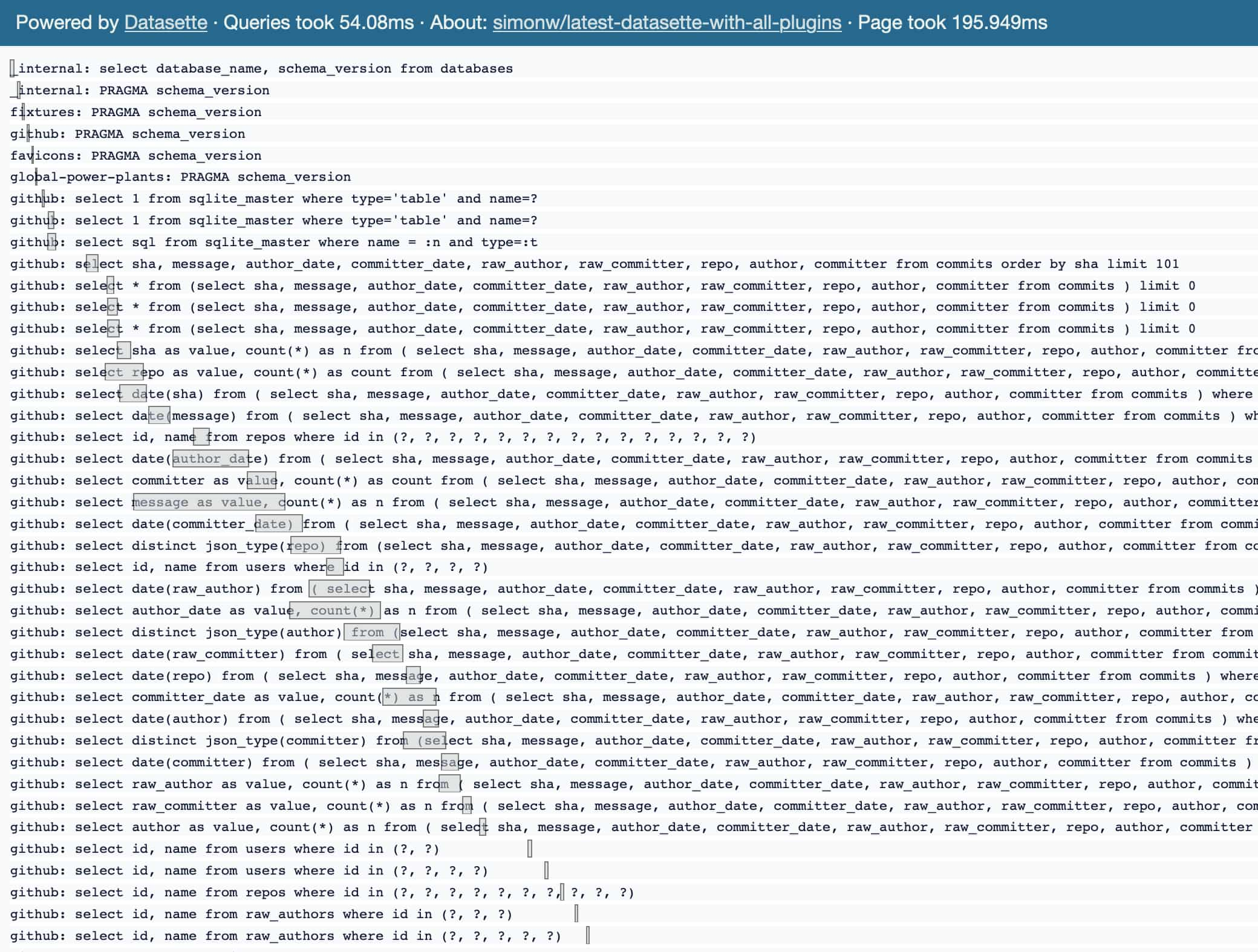
As you can see, the grey lines for many of those SQL queries are now overlapping.
You can add the undocumented ?_noparallel=1 query string parameter to disable parallel execution to compare the difference:
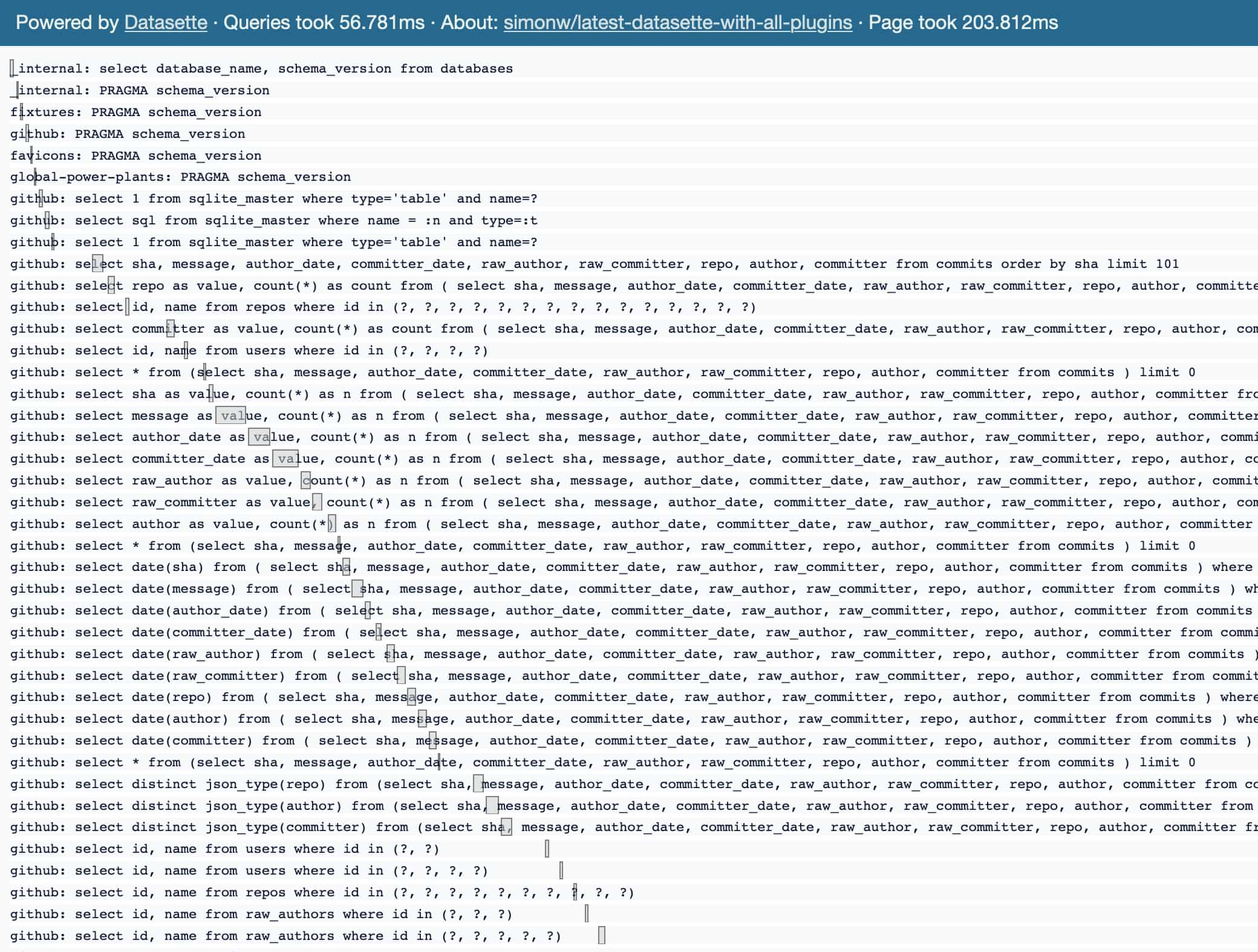
One thing that gives me pause: for this particular Datasette deployment (on the cheapest available Cloud Run instance) the overall performance difference between the two is very small.
I need to dig into this deeper: on my laptop I feel like I’m seeing slightly better results, but definitely not conclusively. It may be that multiple cores are not being used effectively here.
Datasette runs SQL queries in a pool of threads. You might expect Python’s infamous GIL (Global Interpreter Lock) to prevent these from executing across multiple cores—but I checked, and the GIL is released in Python’s C code the moment control transfers to SQLite. And since SQLite can happily run multiple threads, my hunch is that this means parallel queries should be able to take advantage of multiple cores. Theoretically at least!
I haven’t yet figured out how to prove this though, and I’m not currently convinced that parallel queries are providing any overall benefit at all. If you have any ideas I’d love to hear them—I have a research issue open, comments welcome!
Update 28th April 2022: Research continues, but it looks like there’s little performance benefit from this. Current leading theory is that this is because of the GIL—while the SQLite C code releases the GIL, much of the activity involved in things like assembling Row objects returned by a query still uses Python—so parallel queries still end up mostly blocked on a single core. Follow the issue for more details. I started a discussion on the SQLite Forum which has some interesting clues in it as well.
Further update: It’s definitely the GIL. I know because I tried running it against Sam Gross’s nogil Python fork and the parallel version soundly beat the non-parallel version! Details in this comment.
datasette-gzip
I’ve been putting off investigating gzip support for Datasette for a long time, because it’s easy to add as a separate layer. If you run Datasette behind Cloudflare or an Apache or Nginx proxy configuring gzip can happen there, with very little effort and fantastic performance.
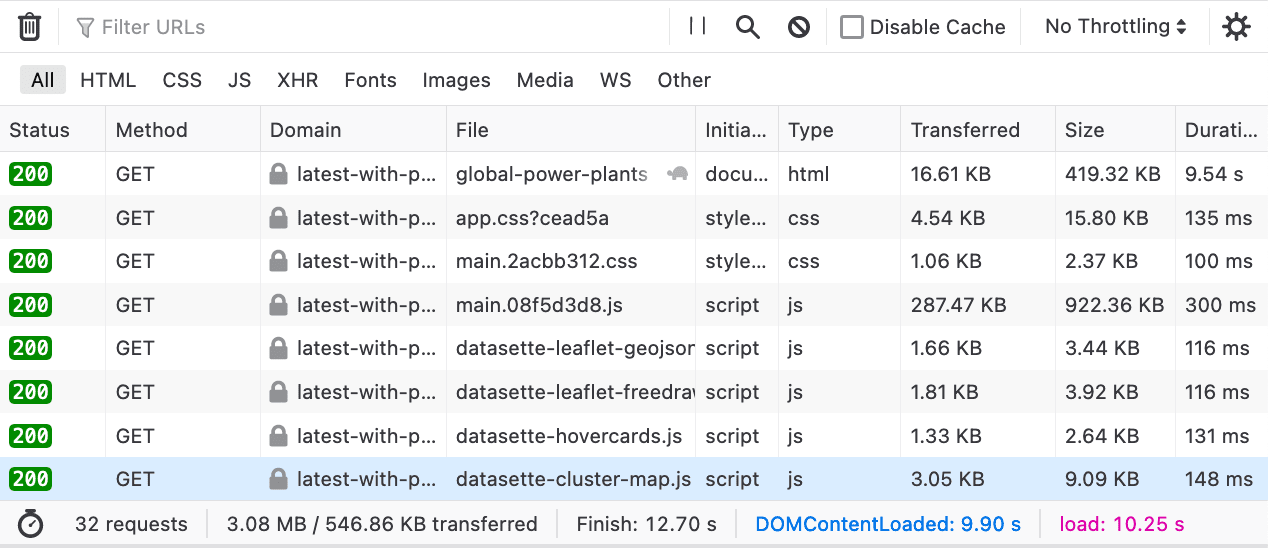
Then I noticed that my Global Power Plants demo returned an HTML table page that weighed in at 420KB... but gzipped was just 16.61KB. Turns out HTML tables have a ton of repeated markup and compress REALLY well!
More importantly: Google Cloud Run doesn’t gzip for you. So all of my Datasette instances that were running on Cloud Run without also using Cloudflare were really suffering.
So this morning I released datasette-gzip, a plugin that gzips content if the browser sends an Accept-Encoding: gzip header.
The plugin is an incredibly thin wrapper around the thorougly proven-in-production GZipMiddleware. So thin that this is the full implementation:
from datasette import hookimpl from starlette.middleware.gzip import GZipMiddleware @hookimpl(trylast=True) def asgi_wrapper(datasette): return GZipMiddleware
This kind of thing is exactly why I ported Datasette to ASGI back in 2019—and why I continue to think that the burgeoning ASGI ecosystem is the most under-rated piece of today’s Python web development environment.
The plugin’s tests are a lot more interesting.
That @hookimpl(trylast=True) line is there to ensure that this plugin runs last, after ever other plugin has executed.
This is necessary because there are existing ASGI plugins for Datasette (such as the new datasette-total-page-time) which modify the generated request.
If the gzip plugin runs before they do, they’ll get back a blob of gzipped data rather than the HTML that they were expecting. This is likely to break them.
I wanted to prove to myself that trylast=True would prevent these errors—so I ended up writing a test that demonstrated that the plugin registered with trylast=True was compatible with a transforming content plugin (in the test it just converts everything to uppercase) whereas tryfirst=True would instead result in an error.
Thankfully I have an older TIL on Registering temporary pluggy plugins inside tests that I could lean on to help figure out how to do this.
The plugin is now running on my latest-with-plugins demo instance. Since that instance loads dozens of different plugins it ends up serving a bunch of extra JavaScript and CSS, all of which benefits from gzip:
datasette-total-page-time
To help understand the performance improvements introduced by parallel SQL queries I decided I wanted the Datasette footer to be able to show how long it took for the entire page to load.
This is a tricky thing to do: how do you measure the total time for a page and then include it on that page if the page itself hasn’t finished loading when you render that template?
I came up with a pretty devious middleware trick to solve this, released as the datasette-total-page-time plugin.
The trick is to start a timer when the page load begins, and then end that timer at the very last possible moment as the page is being served back to the user.
Then, inject the following HTML directly after the closing </html> tag (which works fine, even though it’s technically invalid):
<script>
let footer = document.querySelector("footer");
if (footer) {
let ms = 37.224;
let s = ` · Page took ${ms.toFixed(3)}ms`;
footer.innerHTML += s;
}
</script>This adds the timing information to the page’s <footer> element, if one exists.
You can see this running on this latest-with-plugins page.
Releases this week
-
datasette-gzip: 0.1—2022-04-27
Add gzip compression to Datasette -
datasette-total-page-time: 0.1—2022-04-26
Add a note to the Datasette footer measuring the total page load time -
asyncinject: 0.5—(7 releases total)—2022-04-22
Run async workflows using pytest-fixtures-style dependency injection -
django-sql-dashboard: 1.1—(35 releases total)—2022-04-20
Django app for building dashboards using raw SQL queries -
shot-scraper: 0.13—(14 releases total)—2022-04-18
Tools for taking automated screenshots of websites
TIL this week
More recent articles
- Meta's new model is Muse Spark, and meta.ai chat has some interesting tools - 8th April 2026
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026