Weeknotes: datasette-socrata, and the last 10%...
19th June 2022
... takes 90% of the work. I continue to work towards a preview of the new Datasette Cloud, and keep finding new “just one more things” to delay inviting in users.
Aside from continuing to work on that, my big project in the last week was a blog entry: Twenty years of my blog, in which I celebrated twenty years since starting this site by pulling together a selection of highlights from over the years.
I’ve actually updated that entry a few times over the past few days as I remembered new highlights I forgot to include—the Twitter thread that accompanies the entry has those updates, starting here.
datasette-socrata
I’ve been thinking a lot about the Datasette Cloud onboarding experience: how can I help new users understand what Datasette can be used for as quickly as possible?
I want to get them to a point where they are interacting with a freshly created table of data. I can provide some examples, but I’ve always thought that one of the biggest opportunities for Datasette lies in working with the kind of data released by governments through their Open Data portals. This is especially true for its usage in the field of data journalism.
Many open data portals—including the one for San Francisco—are powered by a piece of software called Socrata. And it offers a pretty comprehensive API.
datasette-socrata is a new Datasette plugin which can import data from Socrata instances. Give it the URL to a Socrata dataset (like this one, my perennial favourite, listing all 195,000+ trees managed by the city of San Francisco) and it will import that data and its associated metadata into a brand new table.
It’s pretty neat! It even shows you a progress bar, since some of these datasets can get pretty large:
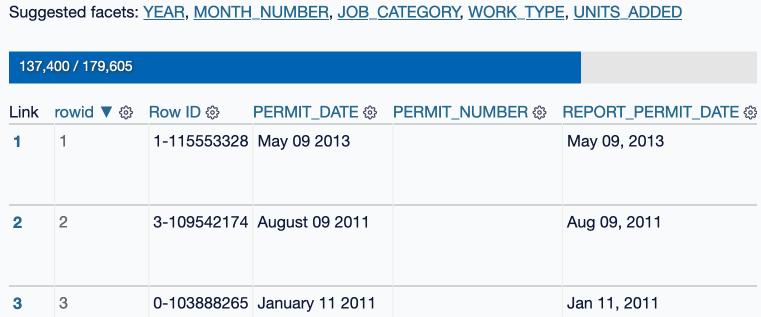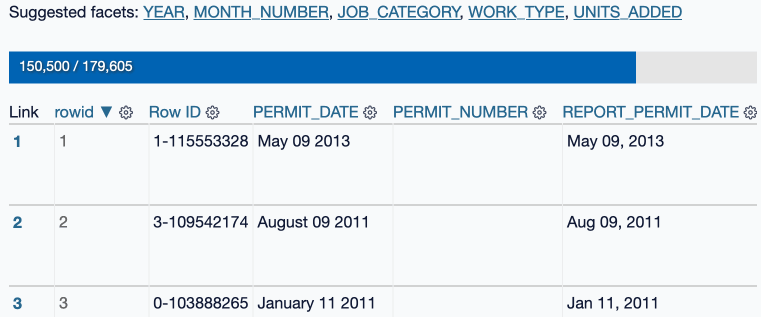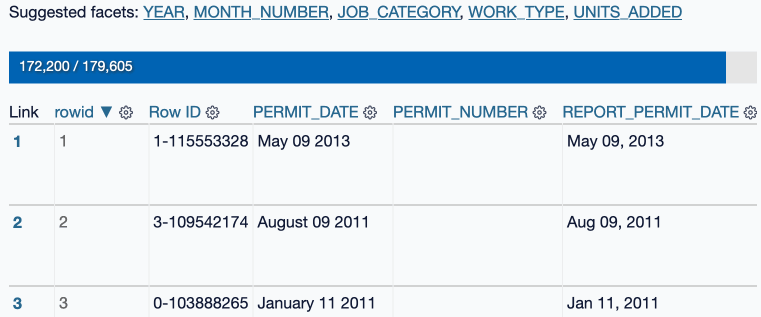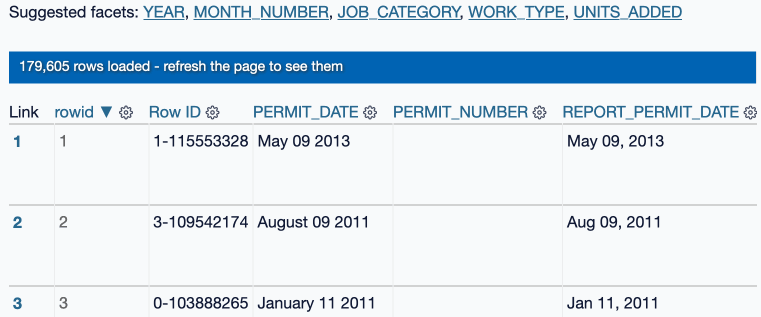
As part of building this I ran into the interesting question of what a plugin like this should do if the system it is running on runs out of disk space?
I’m still working through that, but I’m experimenting with a new type of Datasette plugin for it: datasette-low-disk-space-hook, which introduces a new plugin hook (low_disk_space(datasette)) which other plugins can use to report a situation where disk space is running out.
I wrote a TIL about that here: Registering new Datasette plugin hooks by defining them in other plugins.
I may use this same trick for a future upgrade to datasette-graphql, to allow additional plugins to register custom GraphQL mutations.
sqlite-utils 3.27
In working on datasette-socrata I was inspired to push out a new release of sqlite-utils. Here are the annotated release notes:
I wrote about this a few weeks ago—the new documentation theme is now live for the stable documentation.
- Code examples in documentation now have a “copy to clipboard” button. (#436)
I made this change to Datasette first—the sphinx-copybutton plugin adds a neat “copy” button next to every code example.
I also like how this encourages ensuring that every example will work if people directly copy and paste it.
sqlite_utils.utils.utils.rows_from_file()is now a documented API, see Reading rows from a file. (#443)
Francesco Frassinelli filed an issue about this utility function, which wasn’t actually part of the documented stable API, but I saw no reason not to promote it.
The function incorporates the logic that the sqlite-utils CLI tool uses to automatically detect if a provided file is CSV, TSV or JSON and detect the CSV delimeter and other settings.
rows_from_file()has two new parameters to help handle CSV files with rows that contain more values than are listed in that CSV file’s headings:ignore_extras=Trueandextras_key="name-of-key". (#440)
It turns out csv.DictReader in the Python standard library has a mechanism for handling CSV rows that contain too many commas.
In working on this I found a bug in mypy which I reported here, but it turned out to be a dupe of an already fixed issue.
sqlite_utils.utils.maximize_csv_field_size_limit()helper function for increasing the field size limit for reading CSV files to its maximum, see Setting the maximum CSV field size limit. (#442)
This is a workaround for the following Python error:
_csv.Error: field larger than field limit (131072)
It’s an error that occurs when a field in a CSV file is longer than a default length.
Saying “yeah, I want to be able to handle the maximum length possible” is surprisingly hard—Python doesn’t let you set a maximum, and can throw errors depending on the platform if you set a number too high. Here’s the idiom that works, which is encapsulated by the new utility function:
field_size_limit = sys.maxsize while True: try: csv_std.field_size_limit(field_size_limit) break except OverflowError: field_size_limit = int(field_size_limit / 10)
table.search(where=, where_args=)parameters for adding additionalWHEREclauses to a search query. Thewhere=parameter is available ontable.search_sql(...)as well. See Searching with table.search(). (#441)
This was a feature suggestion from Tim Head.
- Fixed bug where
table.detect_fts()and other search-related functions could fail if two FTS-enabled tables had names that were prefixes of each other. (#434)
This was quite a gnarly bug. sqlite-utils attempts to detect if a table has an associated full-text search table by looking through the schema for another table that has a definition like this one:
CREATE VIRTUAL TABLE "searchable_fts"
USING FTS4 (
text1,
text2,
[name with . and spaces],
content="searchable"
)I was checking for content="searchable" using a LIKE query:
SELECT name FROM sqlite_master
WHERE rootpage = 0
AND
sql LIKE '%VIRTUAL TABLE%USING FTS%content=%searchable%'But this would incorrectly match strings such as content="searchable2" as well!
Releases this week
-
datasette-socrata: 0.3—(4 releases total)—2022-06-17
Import data from Socrata into Datasette -
datasette-low-disk-space-hook: 0.1—(2 releases total)—2022-06-17
Datasette plugin providing the low_disk_space hook for other plugins to check for low disk space -
sqlite-utils: 3.27—(101 releases total)—2022-06-15
Python CLI utility and library for manipulating SQLite databases -
datasette-ics: 0.5.1—(4 releases total)—2022-06-10
Datasette plugin for outputting iCalendar files -
datasette-upload-csvs: 0.7.1—(9 releases total)—2022-06-09
Datasette plugin for uploading CSV files and converting them to database tables
TIL this week
More recent articles
- Datasette Apps: Host custom HTML applications inside Datasette - 18th June 2026
- GLM-5.2 is probably the most powerful text-only open weights LLM - 17th June 2026
- Publishing WASM wheels to PyPI for use with Pyodide - 13th June 2026