Monday, 5th September 2022
Exploring the training data behind Stable Diffusion
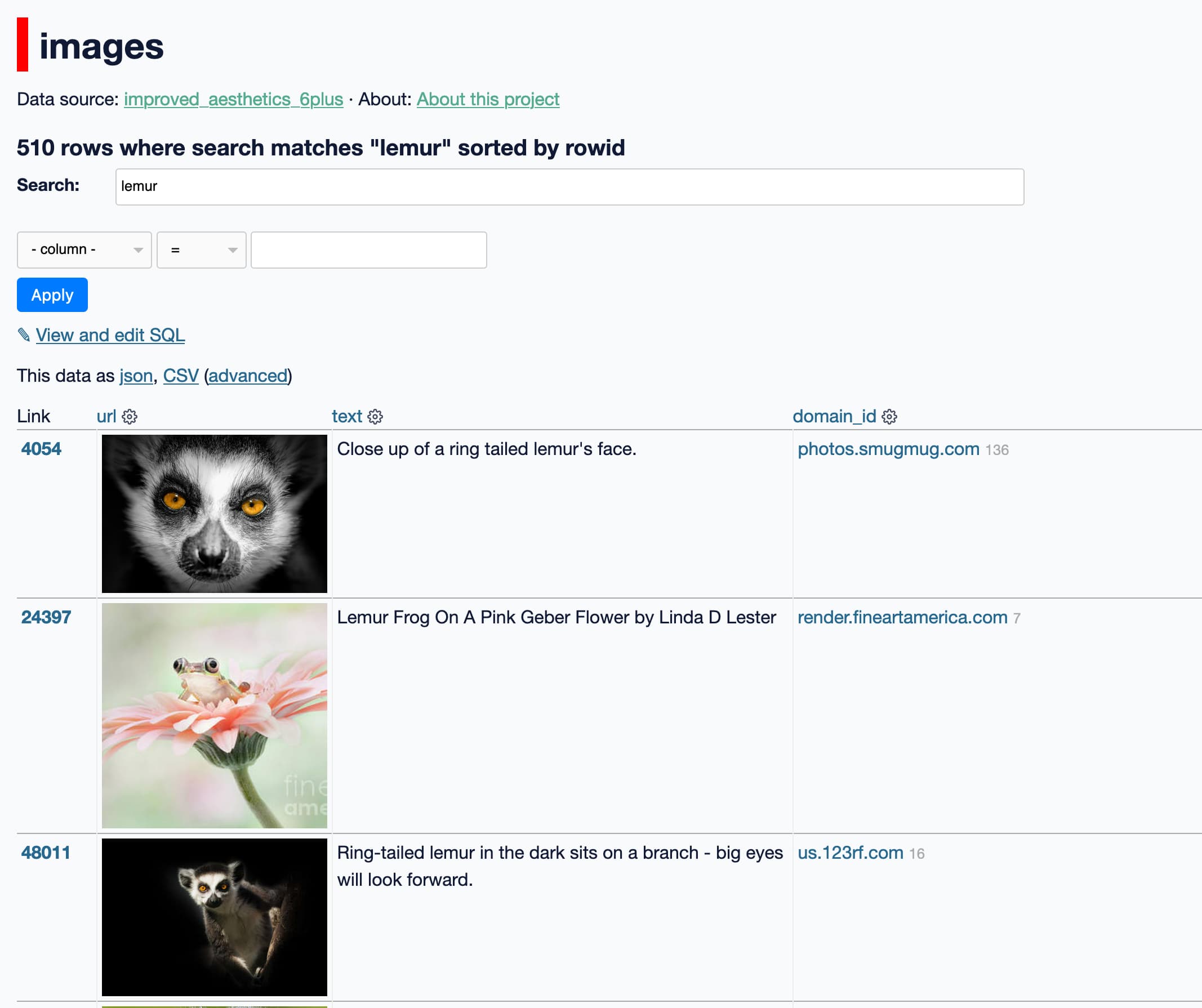
Two weeks ago, the Stable Diffusion image generation model was released to the public. I wrote about this last week, in Stable Diffusion is a really big deal—a post which has since become one of the top ten results for “stable diffusion” on Google and shown up in all sorts of different places online.
[... 2,897 words]Should You Use Upper Bound Version Constraints?
(via)
Should you pin your library's dependencies using "click>=7,<8" or "click~=7.0"? Henry Schreiner's short answer is no, and his long answer is an exhaustive essay covering every conceivable aspect of this thorny Python packaging problem.
r/MachineLearning: What is the SOTA explanation for why deep learning works? The thing I find fascinating about this Reddit conversation is that it makes it clear that the machine learning research community has very little agreement on WHY the state of the art techniques that are being used today actually work as well as they do.
The Amazon Builders’ Library (via) “How Amazon builds and operates software”—an extraordinarily valuable collection of detailed articles about how AWS works and operates under the hood.
Over the years, across multiple deployments, DynamoDB has learned that it’s not just the end state and the start state that matter; there could be times when the newly deployed software doesn’t work and needs a rollback. The rolled-back state might be different from the initial state of the software. The rollback procedure is often missed in testing and can lead to customer impact. DynamoDB runs a suite of upgrade and downgrade tests at a component level before every deployment. Then, the software is rolled back on purpose and tested by running functional tests. DynamoDB has found this process valuable for catching issues that otherwise would make it hard to rollback if needed.
— Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service
Spevktator: OSINT analysis tool for VK. This is a really cool project that came out of a recent Bellingcat hackathon. Spevktator takes 67,000 posts from five popular Russian news channels on VK (a popular Russian social media platform) and makes them available in Datasette, along with automated translations to English, post sharing metrics and sentiment analysis scores. This README includes some detailed analysis of the data, plus a link to an Observable notebook that implements custom visualizations against queries run directly against the Datasette instance.
Feeding AI systems on the world’s beauty, ugliness, and cruelty, but expecting it to reflect only the beauty is a fantasy
