Interesting ideas in Observable Framework
3rd March 2024
Mike Bostock, Announcing: Observable Framework:
Today we’re launching Observable 2.0 with a bold new vision: an open-source static site generator for building fast, beautiful data apps, dashboards, and reports.
Our mission is to help teams communicate more effectively with data. Effective presentation of data is critical for deep insight, nuanced understanding, and informed decisions. Observable notebooks are great for ephemeral, ad hoc data exploration. But notebooks aren’t well-suited for polished dashboards and apps.
Enter Observable Framework.
There are a lot of really interesting ideas in Observable Framework.
- A static site generator for data projects and dashboards
- JavaScript in Markdown
- Everything is still reactive
- Only include the code that you use
- Cache your data at build time
- Comparison to Observable Notebooks
- A change in strategy
A static site generator for data projects and dashboards
At its heart, Observable Framework is a static site generator. You give it a mixture of Markdown and JavaScript (and potentially other languages too) and it compiles them all together into fast loading interactive pages.
It ships with a full featured hot-reloading server, so you can edit those files in your editor, hit save and see the changes reflected instantly in your browser.
Once you’re happy with your work you can run a build command to turn it into a set of static files ready to deploy to a server—or you can use the npm run deploy command to deploy it directly to Observable’s own authenticated sharing platform.
JavaScript in Markdown
The key to the design of Observable Framework is the way it uses JavaScript in Markdown to create interactive documents.
Here’s what that looks like:
# This is a document
Markdown content goes here.
This will output 1870:
```js
34 * 55
```
And here's the current date and time, updating constantly:
```js
new Date(now)
```
The same thing as an inline string: ${new Date(now)}Any Markdown code block tagged js will be executed as JavaScript in the user’s browser. This is an incredibly powerful abstraction—anything you can do in JavaScript (which these days is effectively anything at all) can now be seamlessly integrated into your document.
In the above example the now value is interesting—it’s a special variable that provides the current time in milliseconds since the epoch, updating constantly. Because now updates constantly, the display value of the cell and that inline expression will update constantly as well.
If you’ve used Observable Notebooks before this will feel familiar—but notebooks involve code and markdown authored in separate cells. With Framework they are all now part of a single text document.
Aside: when I tried the above example I found that the ${new Date(now)} inline expression displayed as Mon Feb 19 2024 20:46:02 GMT-0800 (Pacific Standard Time) while the js block displayed as 2024-02-20T04:46:02.641Z. That’s because inline expressions use the JavaScript default string representation of the object, while the js block uses the Observable display() function which has its own rules for how to display different types of objects, visible in inspect/src/inspect.js.
Everything is still reactive
The best feature of Observable Notebooks is their reactivity—the way cells automatically refresh when other cells they depend on change. This is a big difference to Python’s popular Jupyter notebooks, and is the signature feature of marimo, a new Python notebook tool.
Observable Framework retains this feature in its new JavaScript Markdown documents.
This is particularly useful when working with form inputs. You can drop an input onto a page and refer its value throughout the rest of the document, adding realtime interactivity to documents incredibly easily.
Here’s an example. I ported one of my favourite notebooks to Framework, which provides a tool for viewing download statistics for my various Python packages.
The Observable Framework version can be found at https://simonw.github.io/observable-framework-experiments/package-downloads—source code here on GitHub.
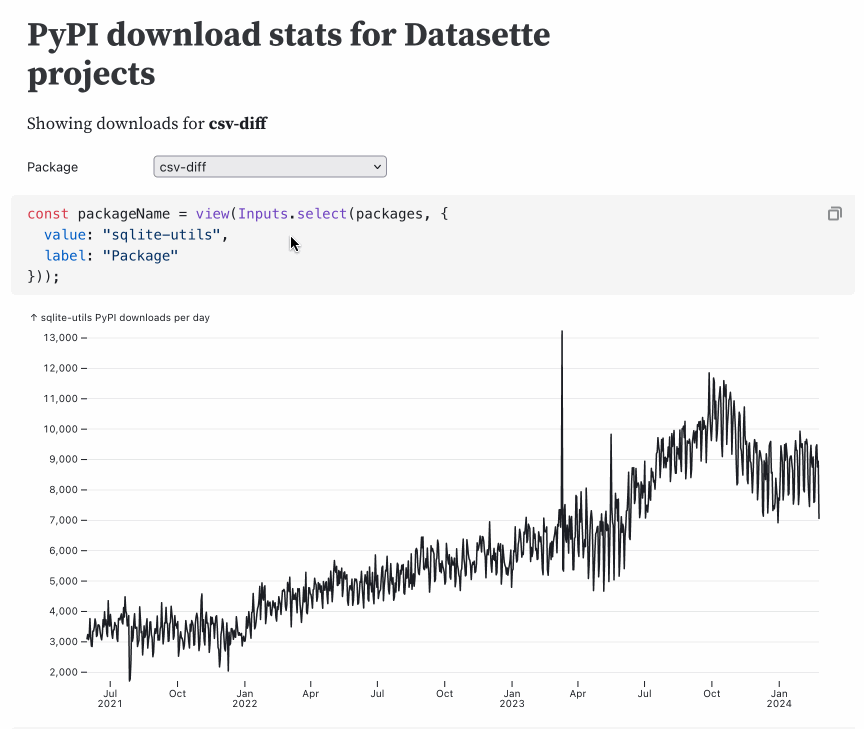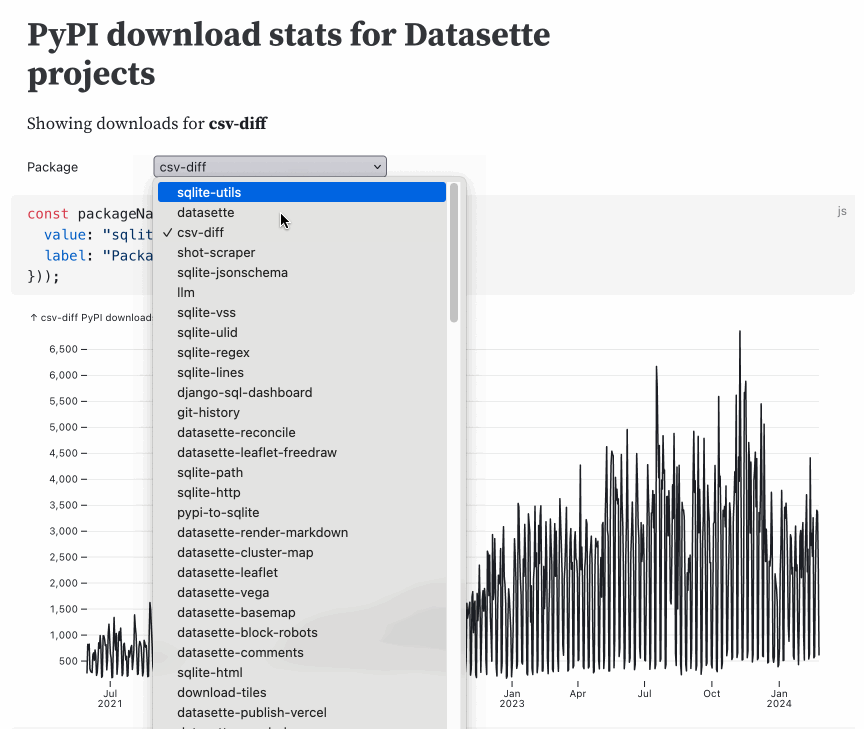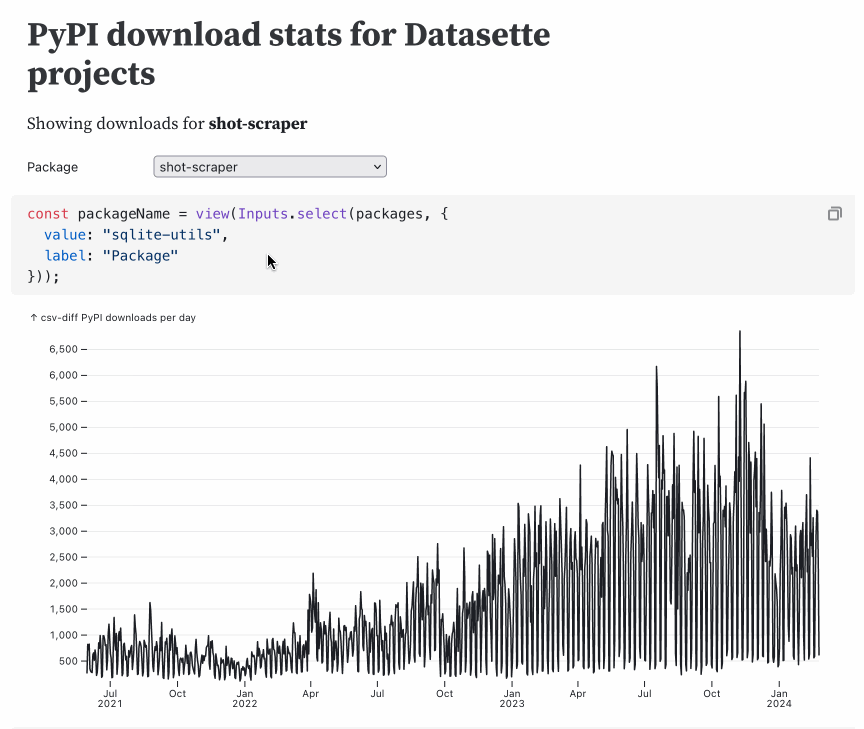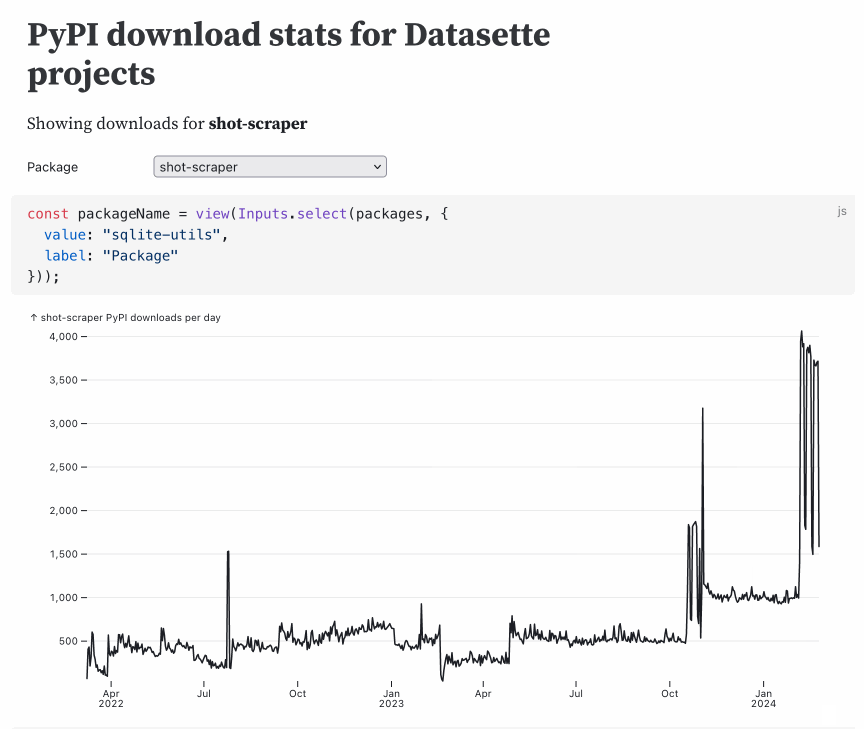
This entire thing is just 57 lines of Markdown. Here’s the code with additional comments (and presented in a slightly different order—the order of code blocks doesn’t matter in Observable thanks to reactivity).
# PyPI download stats for Datasette projects
Showing downloads for **${packageName}**It starts with a Markdown <h1> heading and text that shows the name of the selected package.
```js echo
const packageName = view(Inputs.select(packages, {
value: "sqlite-utils",
label: "Package"
}));
```This block displays the select widget allowing the user to pick one of the items from the packages array (defined later on).
Inputs.select() is a built-in method provided by Framework, described in the Observable Inputs documentation.
The view() function is new in Observable Framework—it’s the thing that enables the reactivity, ensuring that updates to the input selection are acted on by other code blocks in the document.
Because packageName is defined with const it becomes a variable that is visible to other js blocks on the page. It’s used by this next block:
```js echo
const data = d3.json(
`https://datasette.io/content/stats.json?_size=max&package=${packageName}&_sort_desc=date&_shape=array`
);Here we are fetching the data that we need for the chart. I’m using d3.json() (all of D3 is available in Framework) to fetch the data from a URL that includes the selected package name.
The data is coming from Datasette, using the Datasette JSON API. I have a SQLite table at datasette.io/content/stats that’s updated once a day with the latest PyPI package statistics via a convoluted series of GitHub Actions workflows, described previously.
Adding .json to that URL returns the JSON, then I ask for rows for that particular package, sorted descending by date and returning the maximum number of rows (1,000) as a JSON array of objects.
Now that we have data as a variable we can manipulate it slightly for use with Observable Plot—parsing the SQLite string dates into JavaScript Date objects:
```js echo
const data_with_dates = data.map(function(d) {
d.date = d3.timeParse("%Y-%m-%d")(d.date);
return d;
})
```This code is ready to render as a chart. I’m using Observable Plot—also packaged with Framework:
```js echo
Plot.plot({
y: {
grid: true,
label: `${packageName} PyPI downloads per day`
},
width: width,
marginLeft: 60,
marks: [
Plot.line(data_with_dates, {
x: "date",
y: "downloads",
title: "downloads",
tip: true
})
]
})
```
So we have one cell that lets the user pick the package they want, a cell that fetches that data, a cell that processes it and a cell that renders it as a chart.
There’s one more piece of the puzzle: where does that list of packages come from? I fetch that with another API call to Datasette. Here I’m using a SQL query executed against the /content database directly:
```js echo
const packages_sql = "select package from stats group by package order by max(downloads) desc"
```
```js echo
const packages = fetch(
`https://datasette.io/content.json?sql=${encodeURIComponent(
packages_sql
)}&_size=max&_shape=arrayfirst`
).then((r) => r.json());
```_shape=arrayfirst is a shortcut for getting back a JSON array of the first column of the resulting rows.
That’s all there is to it! It’s a pretty tiny amount of code for a full interactive dashboard.
Only include the code that you use
You may have noticed that my dashboard example uses several additional libraries—Inputs for the form element, d3 for the data fetching and Plot for the chart rendering.
Observable Framework is smart about these. It implements lazy loading in development mode, so code is only loaded the first time you attempt to use it in a cell.
When you build and deploy your application, Framework automatically loads just the referenced library code from the jsdelivr CDN.
Cache your data at build time
One of the most interesting features of Framework is its Data loader mechanism.
Dashboards built using Framework can load data at runtime from anywhere using fetch() requests (or wrappers around them). This is how Observable Notebooks work too, but it leaves the performance of your dashboard at the mercy of whatever backends you are talking to.
Dashboards benefit from fast loading times. Framework encourages a pattern where you build the data for the dashboard at deploy time, bundling it together into static files containing just the subset of the data needed for the dashboard. These can be served lightning fast from the same static hosting as the dashboard code itself.
The design of the data loaders is beautifully simple and powerful. A data loader is a script that can be written in any programming language. At build time, Framework executes that script and saves whatever is outputs to a file.
A data loader can be as simple as the following, saved as quakes.json.sh:
curl https://earthquake.usgs.gov/earthquakes/feed/v1.0/summary/all_day.geojsonWhen the application is built, that filename tells Framework the destination file (quakes.json) and the loader to execute (.sh).
This means you can load data from any source using any technology you like, provided it has the ability to output JSON or CSV or some other useful format to standard output.
Comparison to Observable Notebooks
Mike introduced Observable Framework as Observable 2.0. It’s worth reviewing how the this system compares to the original Observable Notebook platform.
I’ve been a huge fan of Observable Notebooks for years—38 blog posts and counting! The most obvious comparison is to Jupyter Notebooks, where they have some key differences:
- Observable notebooks use JavaScript, not Python.
- The notebook editor itself isn’t open source—it’s a hosted product provided on observablehq.com. You can export the notebooks as static files and run them anywhere you like, but the editor itself is a proprietary product.
- Observable cells are reactive. This is the key difference with Jupyter: any time you change a cell all other cells that depend on that cell are automatically re-evaluated, similar to Excel.
- The JavaScript syntax they use isn’t quite standard JavaScript—they had to invent a new
viewofkeyword to support their reactivity model. - Editable notebooks are a pretty complex proprietary file format. They don’t play well with tools like Git, to the point that Observable ended up implementing their own custom version control and collaboration systems.
Observable Framework reuses many of the ideas (and code) from Observable Notebooks, but with some crucial differences:
- Notebooks (really documents) are now single text files—Markdown files with embedded JavaScript blocks. It’s all still reactive, but the file format is much simpler and can be edited using any text editor, and checked into Git.
- It’s all open source. Everything is under an ISC license (OSI approved) and you can run the full editing stack on your own machine.
- It’s all just standard JavaScript now—no custom syntax.
A change in strategy
Reading the tea leaves a bit, this also looks to me like a strategic change of direction for Observable as a company. Their previous focus was on building great collaboration tools for data science and analytics teams, based around the proprietary Observable Notebook editor.
With Framework they appear to be leaning more into the developer tools space.
On Twitter @observablehq describes itself as “The end-to-end solution for developers who want to build and host dashboards that don’t suck”—the Internet Archive copy from October 3rd 2023 showed “Build data visualizations, dashboards, and data apps that impact your business — faster.”
I’m excited to see where this goes. I’ve limited my usage of Observable Notebooks a little in the past purely due to the proprietary nature of their platform and the limitations placed on free accounts (mainly the lack of free private notebooks), while still having enormous respect for the technology and enthusiastically adopting their open source libraries such as Observable Plot.
Observable Framework addresses basically all of my reservations. It’s a fantastic new expression of the ideas that made Observable Notebooks so compelling, and I expect to use it for all sorts of interesting projects in the future.
More recent articles
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026