Wednesday, 15th May 2024
The MacBook Airs are Apple’s best-selling laptops; the iPad Pros are Apple’s least-selling iPads. I think it’s as simple as this: the current MacBook Airs have the M3, not the M4, because there isn’t yet sufficient supply of M4 chips to satisfy demand for MacBook Airs.
But unlike the phone system, we can’t separate an LLM’s data from its commands. One of the enormously powerful features of an LLM is that the data affects the code. We want the system to modify its operation when it gets new training data. We want it to change the way it works based on the commands we give it. The fact that LLMs self-modify based on their input data is a feature, not a bug. And it’s the very thing that enables prompt injection.
How to PyCon (via) Glyph’s tips on making the most out of PyCon. I particularly like his suggestion that “dinners are for old friends, but lunches are for new ones”.
I’m heading out to Pittsburgh tonight, and giving a keynote (!) on Saturday. If you see me there please come and say hi!
If we want LLMs to be less hype and more of a building block for creating useful everyday tools for people, AI companies' shift away from scaling and AGI dreams to acting like regular product companies that focus on cost and customer value proposition is a welcome development.
ChatGPT in “4o” mode is not running the new features yet
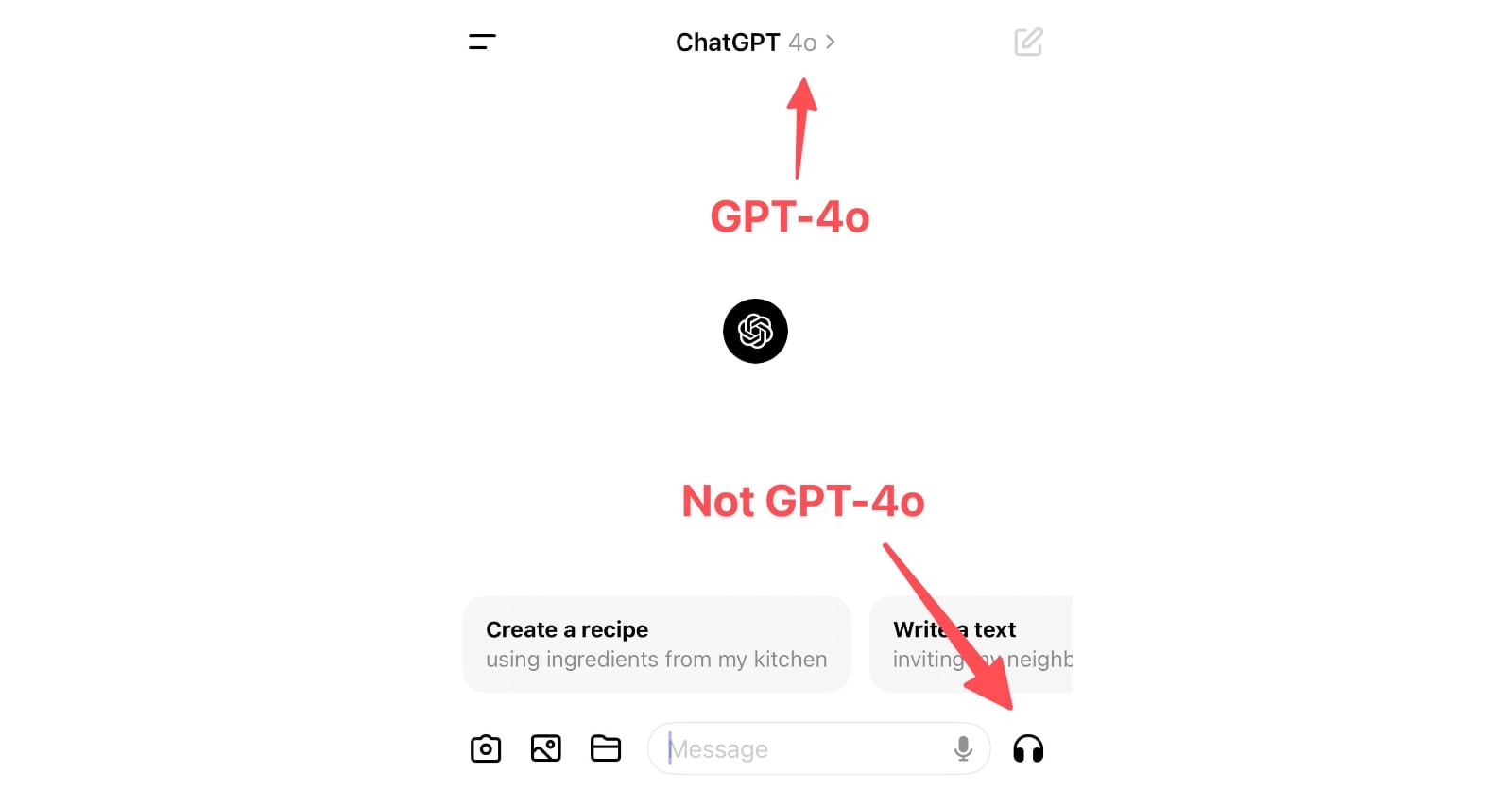
Monday’s OpenAI announcement of their new GPT-4o model included some intriguing new features:
[... 898 words]OpenAI: Managing your work in the API platform with Projects (via) New OpenAI API feature: you can now create API keys for "projects" that can have a monthly spending cap. The UI for that limit says:
If the project's usage exceeds this amount in a given calendar month (UTC), subsequent API requests will be rejected
You can also set custom token-per-minute and request-per-minute rate limits for individual models.
I've been wanting this for ages: this means it's finally safe to ship a weird public demo on top of their various APIs without risk of accidental bankruptcy if the demo goes viral!
PaliGemma model README (via) One of the more over-looked announcements from Google I/O yesterday was PaliGemma, an openly licensed VLM (Vision Language Model) in the Gemma family of models.
The model accepts an image and a text prompt. It outputs text, but that text can include special tokens representing regions on the image. This means it can return both bounding boxes and fuzzier segment outlines of detected objects, behavior that can be triggered using a prompt such as "segment puffins".
From the README:
PaliGemma uses the Gemma tokenizer with 256,000 tokens, but we further extend its vocabulary with 1024 entries that represent coordinates in normalized image-space (
<loc0000>...<loc1023>), and another with 128 entries (<seg000>...<seg127>) that are codewords used by a lightweight referring-expression segmentation vector-quantized variational auto-encoder (VQ-VAE) [...]
You can try it out on Hugging Face.
It's a 3B model, making it feasible to run on consumer hardware.
But where the company once limited itself to gathering low-hanging fruit along the lines of “what time is the super bowl,” on Tuesday executives showcased generative AI tools that will someday plan an entire anniversary dinner, or cross-country-move, or trip abroad. A quarter-century into its existence, a company that once proudly served as an entry point to a web that it nourished with traffic and advertising revenue has begun to abstract that all away into an input for its large language models.