Monday, 21st April 2025
AI assisted search-based research actually works now
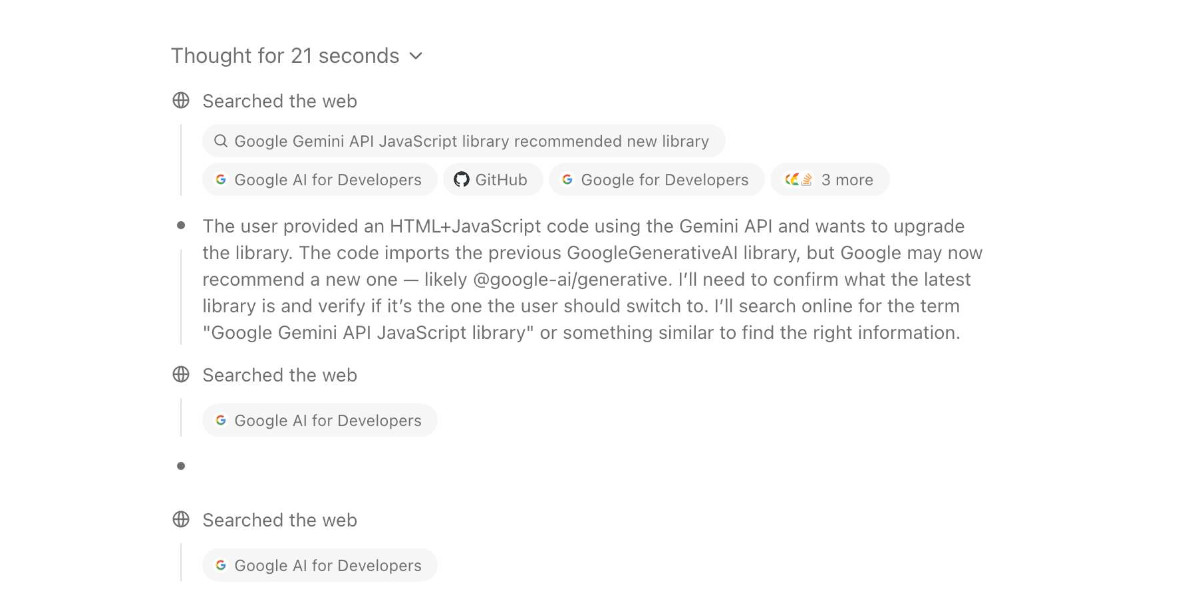
For the past two and a half years the feature I’ve most wanted from LLMs is the ability to take on search-based research tasks on my behalf. We saw the first glimpses of this back in early 2023, with Perplexity (first launched December 2022, first prompt leak in January 2023) and then the GPT-4 powered Microsoft Bing (which launched/cratered spectacularly in February 2023). Since then a whole bunch of people have taken a swing at this problem, most notably Google Gemini and ChatGPT Search.
[... 1,618 words]Decentralizing Schemes. Tim Bray discusses the challenges faced by decentralized Mastodon in that shared URLs to posts don't take into account people accessing Mastodon via their own instances, which breaks replies/likes/shares etc unless you further copy and paste URLs around yourself.
Tim proposes that the answer is URIs: a registered fedi://mastodon.cloud/@timbray/109508984818551909 scheme could allow Fediverse-aware software to step in and handle those URIs, similar to how mailto: works.
Bluesky have registered at: already, and there's also a web+ap: prefix registered with the intent of covering ActivityPub, the protocol used by Mastodon.
OpenAI o3 and o4-mini System Card. I'm surprised to see a combined System Card for o3 and o4-mini in the same document - I'd expect to see these covered separately.
The opening paragraph calls out the most interesting new ability of these models (see also my notes here). Tool usage isn't new, but using tools in the chain of thought appears to result in some very significant improvements:
The models use tools in their chains of thought to augment their capabilities; for example, cropping or transforming images, searching the web, or using Python to analyze data during their thought process.
Section 3.3 on hallucinations has been gaining a lot of attention. Emphasis mine:
We tested OpenAI o3 and o4-mini against PersonQA, an evaluation that aims to elicit hallucinations. PersonQA is a dataset of questions and publicly available facts that measures the model's accuracy on attempted answers.
We consider two metrics: accuracy (did the model answer the question correctly) and hallucination rate (checking how often the model hallucinated).
The o4-mini model underperforms o1 and o3 on our PersonQA evaluation. This is expected, as smaller models have less world knowledge and tend to hallucinate more. However, we also observed some performance differences comparing o1 and o3. Specifically, o3 tends to make more claims overall, leading to more accurate claims as well as more inaccurate/hallucinated claims. More research is needed to understand the cause of this result.
Table 4: PersonQA evaluation Metric o3 o4-mini o1 accuracy (higher is better) 0.59 0.36 0.47 hallucination rate (lower is better) 0.33 0.48 0.16
The benchmark score on OpenAI's internal PersonQA benchmark (as far as I can tell no further details of that evaluation have been shared) going from 0.16 for o1 to 0.33 for o3 is interesting, but I don't know if it it's interesting enough to produce dozens of headlines along the lines of "OpenAI's o3 and o4-mini hallucinate way higher than previous models".
The paper also talks at some length about "sandbagging". I’d previously encountered sandbagging defined as meaning “where models are more likely to endorse common misconceptions when their user appears to be less educated”. The o3/o4-mini system card uses a different definition: “the model concealing its full capabilities in order to better achieve some goal” - and links to the recent Anthropic paper Automated Researchers Can Subtly Sandbag.
As far as I can tell this definition relates to the American English use of “sandbagging” to mean “to hide the truth about oneself so as to gain an advantage over another” - as practiced by poker or pool sharks.
(Wouldn't it be nice if we could have just one piece of AI terminology that didn't attract multiple competing definitions?)
o3 and o4-mini both showed some limited capability to sandbag - to attempt to hide their true capabilities in safety testing scenarios that weren't fully described. This relates to the idea of "scheming", which I wrote about with respect to the GPT-4o model card last year.