Understanding the recent criticism of the Chatbot Arena
30th April 2025
The Chatbot Arena has become the go-to place for vibes-based evaluation of LLMs over the past two years. The project, originating at UC Berkeley, is home to a large community of model enthusiasts who submit prompts to two randomly selected anonymous models and pick their favorite response. This produces an Elo score leaderboard of the “best” models, similar to how chess rankings work.
{kind=link}
It’s become one of the most influential leaderboards in the LLM world, which means that billions of dollars of investment are now being evaluated based on those scores.
The Leaderboard Illusion
A new paper, The Leaderboard Illusion, by authors from Cohere Labs, AI2, Princeton, Stanford, University of Waterloo and University of Washington spends 68 pages dissecting and criticizing how the arena works.

Even prior to this paper there have been rumbles of dissatisfaction with the arena for a while, based on intuitions that the best models were not necessarily bubbling to the top. I’ve personally been suspicious of the fact that my preferred daily driver, Claude 3.7 Sonnet, rarely breaks the top 10 (it’s sat at 20th right now).
This all came to a head a few weeks ago when the Llama 4 launch was mired by a leaderboard scandal: it turned out that their model which topped the leaderboard wasn’t the same model that they released to the public! The arena released a pseudo-apology for letting that happen.
This helped bring focus to the arena’s policy of allowing model providers to anonymously preview their models there, in order to earn a ranking prior to their official launch date. This is popular with their community, who enjoy trying out models before anyone else, but the scale of the preview testing revealed in this new paper surprised me.
From the new paper’s abstract (highlights mine):
We find that undisclosed private testing practices benefit a handful of providers who are able to test multiple variants before public release and retract scores if desired. We establish that the ability of these providers to choose the best score leads to biased Arena scores due to selective disclosure of performance results. At an extreme, we identify 27 private LLM variants tested by Meta in the lead-up to the Llama-4 release.
If proprietary model vendors can submit dozens of test models, and then selectively pick the ones that score highest it is not surprising that they end up hogging the top of the charts!
This feels like a classic example of gaming a leaderboard. There are model characteristics that resonate with evaluators there that may not directly relate to the quality of the underlying model. For example, bulleted lists and answers of a very specific length tend to do better.
It is worth noting that this is quite a salty paper (highlights mine):
It is important to acknowledge that a subset of the authors of this paper have submitted several open-weight models to Chatbot Arena: command-r (Cohere, 2024), command-r-plus (Cohere, 2024) in March 2024, aya-expanse (Dang et al., 2024b) in October 2024, aya-vision (Cohere, 2025) in March 2025, command-a (Cohere et al., 2025) in March 2025. We started this extensive study driven by this submission experience with the leaderboard.
While submitting Aya Expanse (Dang et al., 2024b) for testing, we observed that our open-weight model appeared to be notably under-sampled compared to proprietary models — a discrepancy that is further reflected in Figures 3, 4, and 5. In response, we contacted the Chatbot Arena organizers to inquire about these differences in November 2024. In the course of our discussions, we learned that some providers were testing multiple variants privately, a practice that appeared to be selectively disclosed and limited to only a few model providers. We believe that our initial inquiries partly prompted Chatbot Arena to release a public blog in December 2024 detailing their benchmarking policy which committed to a consistent sampling rate across models. However, subsequent anecdotal observations of continued sampling disparities and the presence of numerous models with private aliases motivated us to undertake a more systematic analysis.
To summarize the other key complaints from the paper:
- Unfair sampling rates: a small number of proprietary vendors (most notably Google and OpenAI) have their models randomly selected in a much higher number of contests.
- Transparency concerning the scale of proprietary model testing that’s going on.
- Unfair removal rates: “We find deprecation disproportionately impacts open-weight and open-source models, creating large asymmetries in data access over”—also “out of 243 public models, 205 have been silently deprecated.” The longer a model stays in the arena the more chance it has to win competitions and bubble to the top.
The Arena responded to the paper in a tweet. They emphasized:
We designed our policy to prevent model providers from just reporting the highest score they received during testing. We only publish the score for the model they release publicly.
I’m dissapointed by this response, because it skips over the point from the paper that I find most interesting. If commercial vendors are able to submit dozens of models to the arena and then cherry-pick for publication just the model that gets the highest score, quietly retracting the others with their scores unpublished, that means the arena is very actively incentivizing models to game the system. It’s also obscuring a valuable signal to help the community understand how well those vendors are doing at building useful models.
Here’s a second tweet where they take issue with “factual errors and misleading statements” in the paper, but still fail to address that core point. I’m hoping they’ll respond to my follow-up question asking for clarification around the cherry-picking loophole described by the paper.
I want more transparency
The thing I most want here is transparency.
If a model sits in top place, I’d like a footnote that resolves to additional information about how that vendor tested that model. I’m particularly interested in knowing how many variants of that model the vendor tested. If they ran 21 different models over a 2 month period before selecting the “winning” model, I’d like to know that—and know what the scores were for all of those others that they didn’t ship.
This knowledge will help me personally evaluate how credible I find their score. Were they mainly gaming the benchmark or did they produce a new model family that universally scores highly even as they tweaked it to best fit the taste of the voters in the arena?
OpenRouter as an alternative?
If the arena isn’t giving us a good enough impression of who is winning the race for best LLM at the moment, what else can we look to?
Andrej Karpathy discussed the new paper on Twitter this morning and proposed an alternative source of rankings instead:
It’s quite likely that LM Arena (and LLM providers) can continue to iterate and improve within this paradigm, but in addition I also have a new candidate in mind to potentially join the ranks of “top tier eval”. It is the OpenRouterAI LLM rankings.
Basically, OpenRouter allows people/companies to quickly switch APIs between LLM providers. All of them have real use cases (not toy problems or puzzles), they have their own private evals, and all of them have an incentive to get their choices right, so by choosing one LLM over another they are directly voting for some combo of capability+cost.
I don’t think OpenRouter is there just yet in both the quantity and diversity of use, but something of this kind I think has great potential to grow into a very nice, very difficult to game eval.
I only recently learned about these rankings but I agree with Andrej: they reveal some interesting patterns that look to match my own intuitions about which models are the most useful (and economical) on which to build software. Here’s a snapshot of their current “Top this month” table:
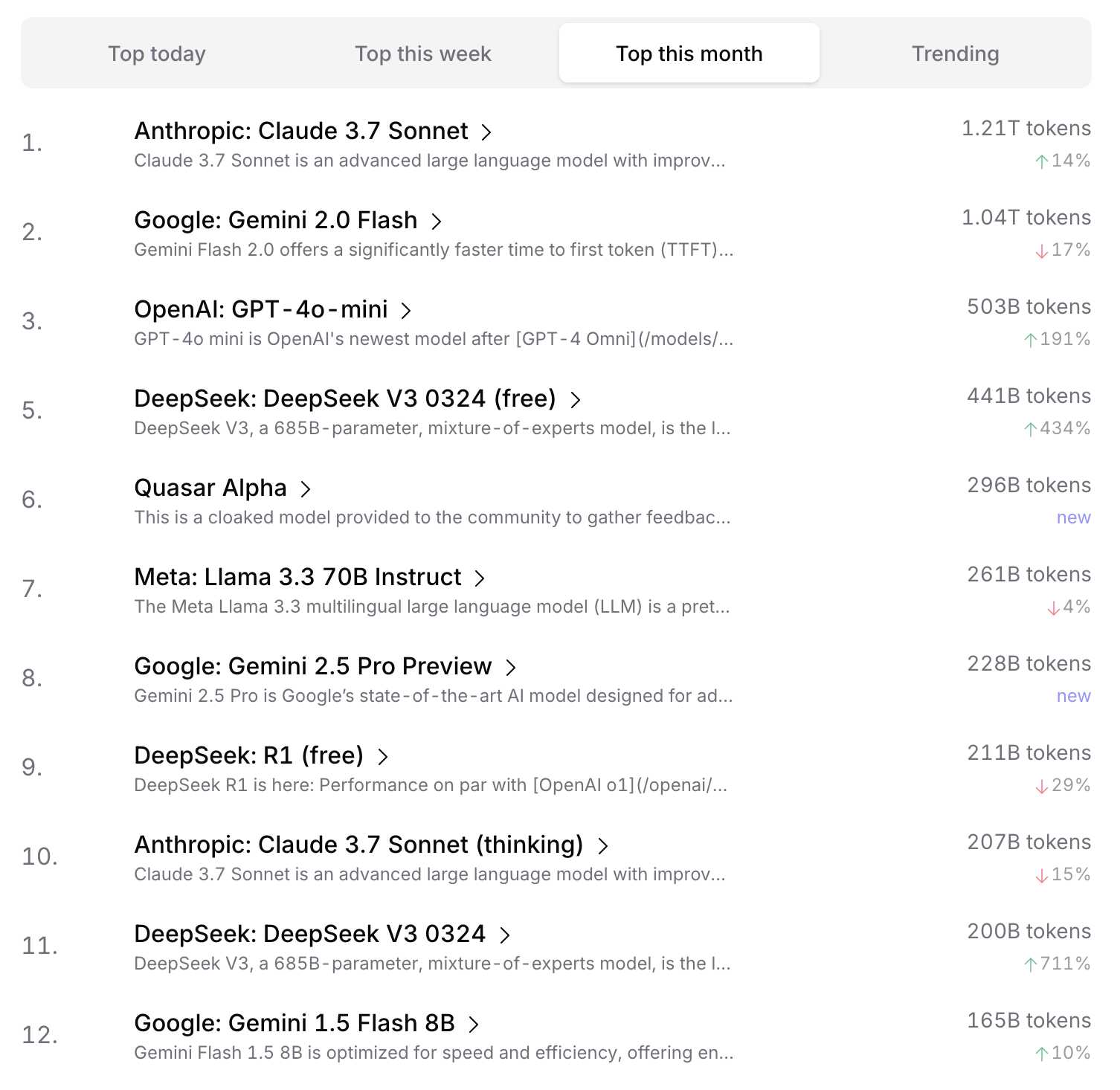
The one big weakness of this ranking system is that a single, high volume OpenRouter customer could have an outsized effect on the rankings should they decide to switch models. It will be interesting to see if OpenRouter can design their own statistical mechanisms to help reduce that effect.
More recent articles
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026