27th January 2025 - Link Blog
Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL! Hot on the heels of yesterday's Qwen2.5-1M, here's Qwen2.5 VL (with an excitable announcement title) - the latest in Qwen's series of vision LLMs.
They're releasing multiple versions: base models and instruction tuned models at 3B, 7B and 72B. There's a lot of additional information in their README.
The 72B model can be selected on Qwen's Qwen Chat interface. I gave it this image of our dog Cleo joy rolling on the beach:

And prompted:
Describe this image in detail, be flowery
(Since the Qwen team tends to use flowery language in their announcements.)
Here's what I got back:
In this enchanting tableau, a canine companion finds solace in the embrace of nature's softest bed. The sandy expanse stretches out like an endless canvas, its surface etched with the delicate imprints of countless wanderers who have come and gone, leaving behind a tapestry of footprints that whisper tales of joyous romps and serene strolls.
The dog, a vision of contentment, lies sprawled upon the sand, its dark fur gleaming under the gentle caress of the sun. Its body is relaxed, limbs splayed in abandon, as if it has surrendered to the soothing rhythm of the beach. A vibrant red collar adorns its neck, a splash of color against the muted tones of the surroundings, hinting at the care and love bestowed upon this cherished pet.
The sand itself is a work of art, its grains shimmering with a silvery sheen that catches the light. Here and there, small tufts of seaweed peek through, remnants of the ocean's bounty, adding a touch of wild beauty to the scene. The shadows cast by unseen objects dance across the sand, creating a play of light and dark that lends an air of mystery to the tranquil setting.
This moment, frozen in time, speaks of peace and harmony, where man's best friend finds respite in the simple pleasures of life. It is a scene that invites one to pause, breathe deeply, and revel in the serenity of nature's embrace.
I'm looking forward to trying out their smaller models - the 3B model in particular should be small enough to run comfortably even on an iPhone, so hopefully someone will wire up an example of that soon (maybe using MLX).
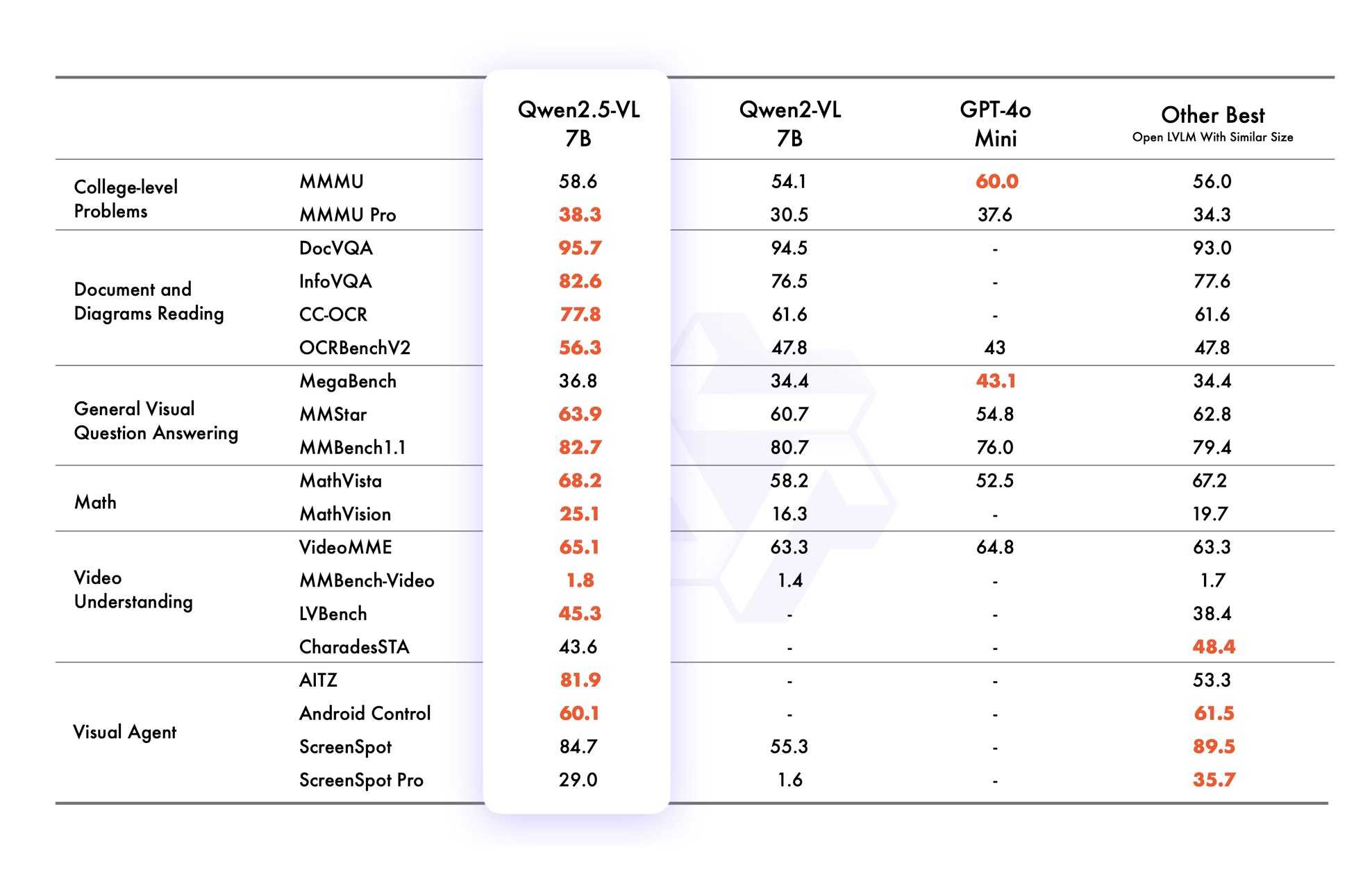
VB points out that the vision benchmarks for Qwen 2.5 VL 7B show it out-performing GPT-4o mini!
Qwen2.5 VL cookbooks
Qwen also just published a set of cookbook recipes:
- universal_recognition.ipynb demonstrates basic visual Q&A, including prompts like
Who are these in this picture? Please give their names in Chinese and Englishagainst photos of celebrities, an ability other models have deliberately suppressed. - spatial_understanding.ipynb demonstrates bounding box support, with prompts like
Locate the top right brown cake, output its bbox coordinates using JSON format. - video_understanding.ipynb breaks a video into individual frames and asks questions like
Could you go into detail about the content of this long video? - ocr.ipynb shows
Qwen2.5-VL-7B-Instructperforming OCR in multiple different languages. - document_parsing.ipynb uses Qwen to convert images of documents to HTML and other formats, and notes that "we introduce a unique Qwenvl HTML format that includes positional information for each component, enabling precise document reconstruction and manipulation."
- mobile_agent.ipynb runs Qwen with tool use against tools for controlling a mobile phone, similar to ChatGPT Operator or Claude Computer Use.
- computer_use.ipynb showcases "GUI grounding" - feeding in screenshots of a user's desktop and running tools for things like left clicking on a specific coordinate.
Running it with mlx-vlm
Update 30th January 2025: I got it working on my Mac using uv and mlx-vlm, with some hints from this issue. Here's the recipe that worked (downloading a 9GB model from mlx-community/Qwen2.5-VL-7B-Instruct-8bit):
uv run --with 'numpy<2' --with 'git+https://github.com/huggingface/transformers' \
--with mlx-vlm \
python -m mlx_vlm.generate \
--model mlx-community/Qwen2.5-VL-7B-Instruct-8bit \
--max-tokens 100 \
--temp 0.0 \
--prompt "Describe this image." \
--image path-to-image.pngI ran that against this image:
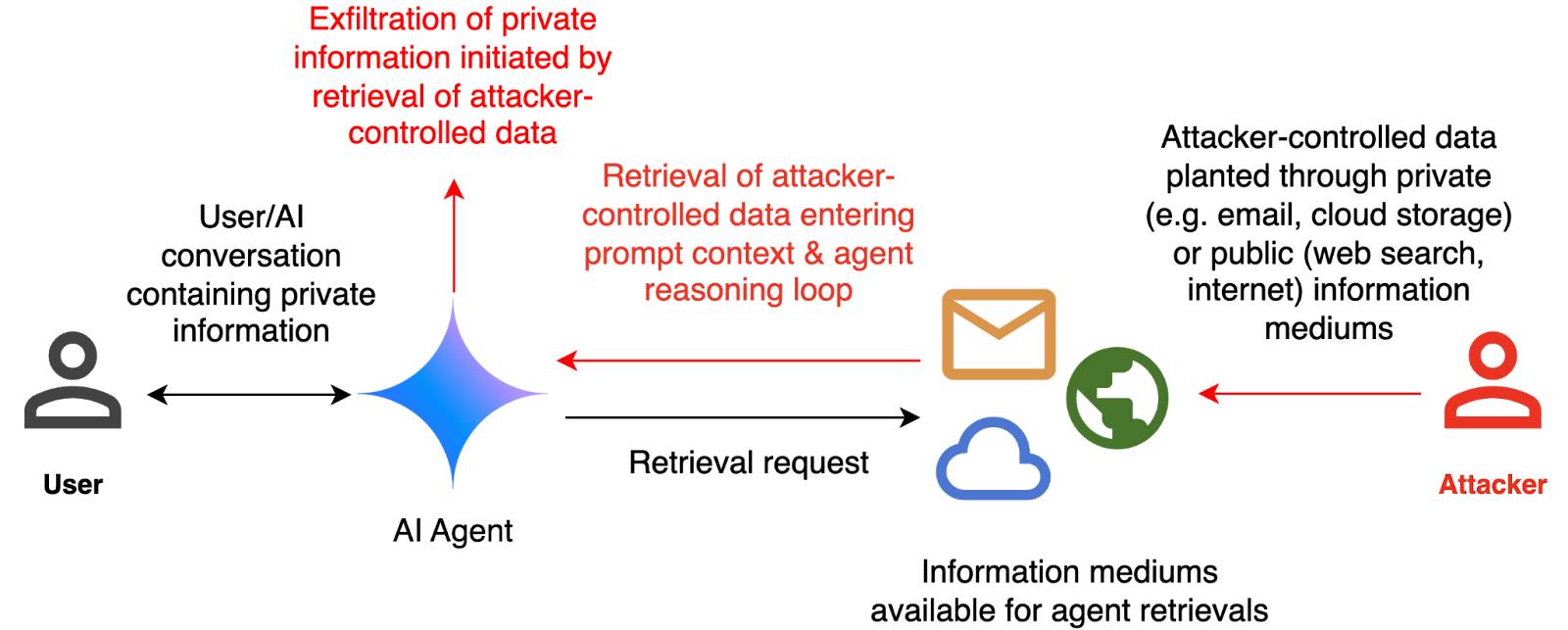
And got back this result:
The image appears to illustrate a flowchart or diagram related to a cybersecurity scenario. Here's a breakdown of the elements:
- User: Represented by a simple icon of a person.
- AI Agent: Represented by a blue diamond shape.
- Attacker: Represented by a red icon of a person.
- Cloud and Email Icons: Represented by a cloud and an envelope, indicating data or information being transferred.
- Text: The text
Recent articles
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026
- Thoughts on OpenAI acquiring Astral and uv/ruff/ty - 19th March 2026