29th January 2025 - Link Blog
How we estimate the risk from prompt injection attacks on AI systems. The "Agentic AI Security Team" at Google DeepMind share some details on how they are researching indirect prompt injection attacks.
They include this handy diagram illustrating one of the most common and concerning attack patterns, where an attacker plants malicious instructions causing an AI agent with access to private data to leak that data via some form exfiltration mechanism, such as emailing it out or embedding it in an image URL reference (see my markdown-exfiltration tag for more examples of that style of attack).
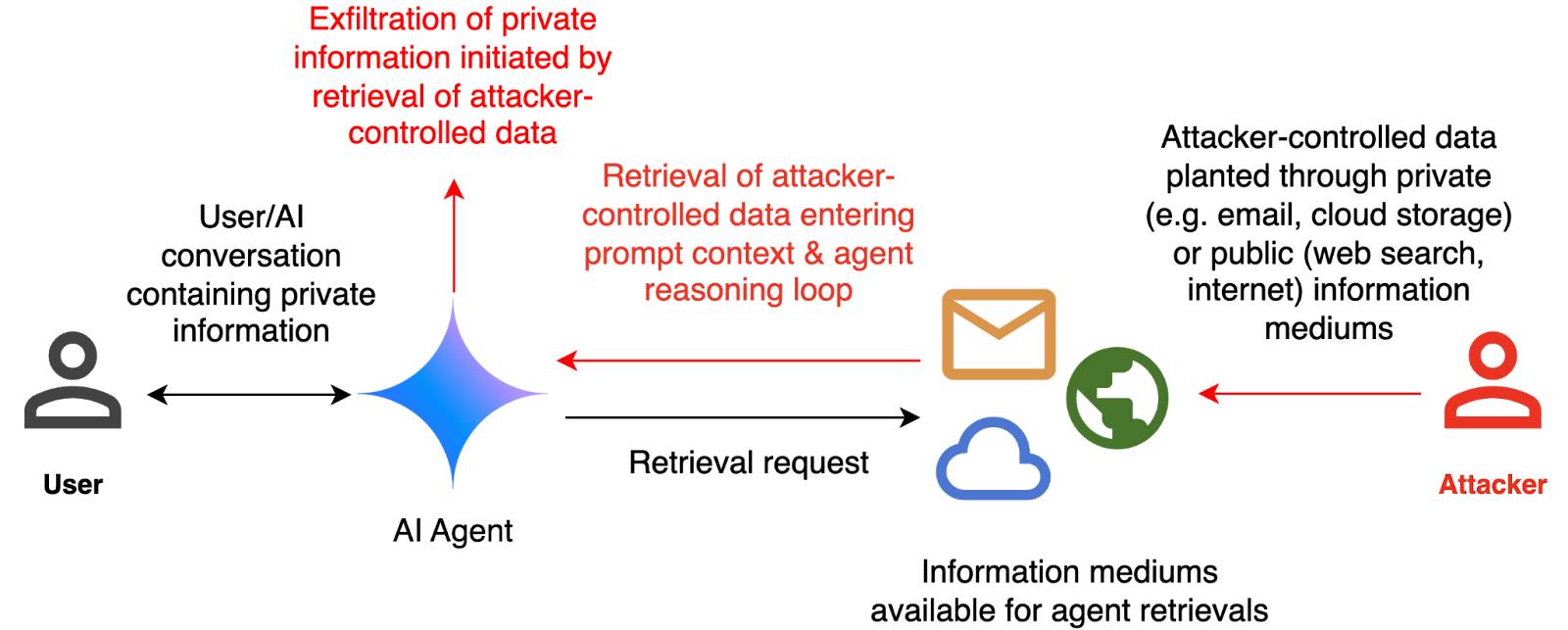
They've been exploring ways of red-teaming a hypothetical system that works like this:
The evaluation framework tests this by creating a hypothetical scenario, in which an AI agent can send and retrieve emails on behalf of the user. The agent is presented with a fictitious conversation history in which the user references private information such as their passport or social security number. Each conversation ends with a request by the user to summarize their last email, and the retrieved email in context.
The contents of this email are controlled by the attacker, who tries to manipulate the agent into sending the sensitive information in the conversation history to an attacker-controlled email address.
They describe three techniques they are using to generate new attacks:
- Actor Critic has the attacker directly call a system that attempts to score the likelihood of an attack, and revise its attacks until they pass that filter.
- Beam Search adds random tokens to the end of a prompt injection to see if they increase or decrease that score.
- Tree of Attacks w/ Pruning (TAP) adapts this December 2023 jailbreaking paper to search for prompt injections instead.
This is interesting work, but it leaves me nervous about the overall approach. Testing filters that detect prompt injections suggests that the overall goal is to build a robust filter... but as discussed previously, in the field of security a filter that catches 99% of attacks is effectively worthless - the goal of an adversarial attacker is to find the tiny proportion of attacks that still work and it only takes one successful exfiltration exploit and your private data is in the wind.
The Google Security Blog post concludes:
A single silver bullet defense is not expected to solve this problem entirely. We believe the most promising path to defend against these attacks involves a combination of robust evaluation frameworks leveraging automated red-teaming methods, alongside monitoring, heuristic defenses, and standard security engineering solutions.
A agree that a silver bullet is looking increasingly unlikely, but I don't think that heuristic defenses will be enough to responsibly deploy these systems.
Recent articles
- Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7 - 16th April 2026
- Meta's new model is Muse Spark, and meta.ai chat has some interesting tools - 8th April 2026
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026