Vibe scraping and vibe coding a schedule app for Open Sauce 2025 entirely on my phone
17th July 2025
This morning, working entirely on my phone, I scraped a conference website and vibe coded up an alternative UI for interacting with the schedule using a combination of OpenAI Codex and Claude Artifacts.
This weekend is Open Sauce 2025, the third edition of the Bay Area conference for YouTube creators in the science and engineering space. I have a couple of friends going and they were complaining that the official schedule was difficult to navigate on a phone—it’s not even linked from the homepage on mobile, and once you do find the agenda it isn’t particularly mobile-friendly.
We were out for coffee this morning so I only had my phone, but I decided to see if I could fix it anyway.
TLDR: Working entirely on my iPhone, using a combination of OpenAI Codex in the ChatGPT mobile app and Claude Artifacts via the Claude app, I was able to scrape the full schedule and then build and deploy this: tools.simonwillison.net/open-sauce-2025
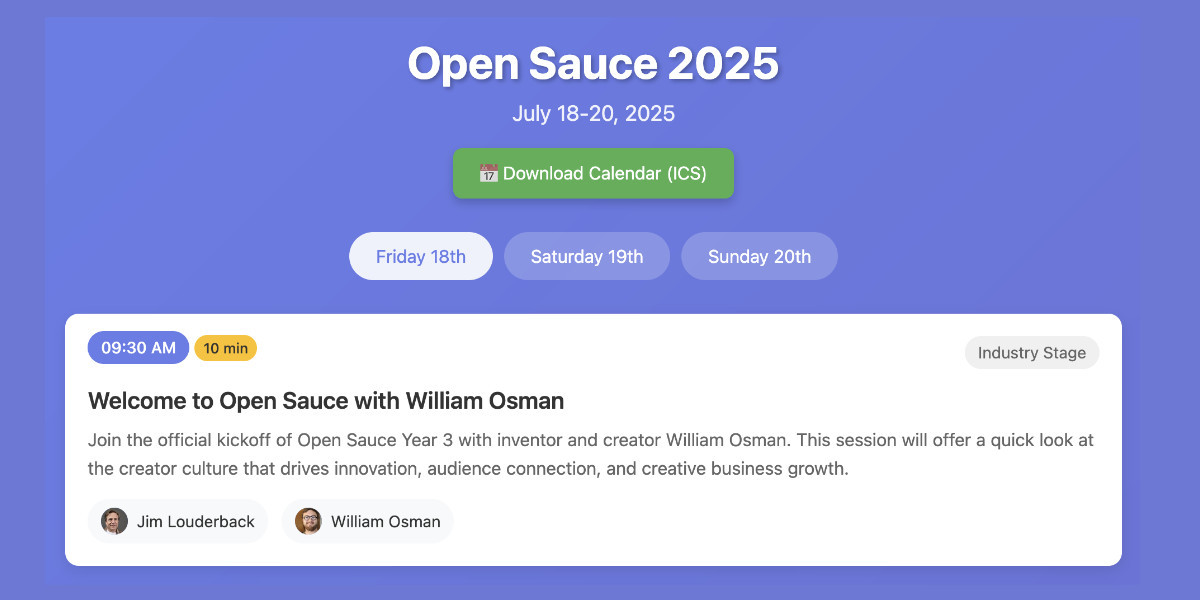
The site offers a faster loading and more useful agenda view, but more importantly it includes an option to “Download Calendar (ICS)” which allows mobile phone users (Android and iOS) to easily import the schedule events directly into their calendar app of choice.
Here are some detailed notes on how I built it.
Scraping the schedule
Step one was to get that schedule in a structured format. I don’t have good tools for viewing source on my iPhone, so I took a different approach to turning the schedule site into structured data.
My first thought was to screenshot the schedule on my phone and then dump the images into a vision LLM—but the schedule was long enough that I didn’t feel like scrolling through several different pages and stitching together dozens of images.
If I was working on a laptop I’d turn to scraping: I’d dig around in the site itself and figure out where the data came from, then write code to extract it out.
How could I do the same thing working on my phone?
I decided to use OpenAI Codex—the hosted tool, not the confusingly named CLI utility.
Codex recently grew the ability to interact with the internet while attempting to resolve a task. I have a dedicated Codex “environment” configured against a GitHub repository that doesn’t do anything else, purely so I can run internet-enabled sessions there that can execute arbitrary network-enabled commands.
I started a new task there (using the Codex interface inside the ChatGPT iPhone app) and prompted:
Install playwright and use it to visit https://opensauce.com/agenda/ and grab the full details of all three day schedules from the tabs - Friday and Saturday and Sunday - then save and on Data in as much detail as possible in a JSON file and submit that as a PR
Codex is frustrating in that you only get one shot: it can go away and work autonomously on a task for a long time, but while it’s working you can’t give it follow-up prompts. You can wait for it to finish entirely and then tell it to try again in a new session, but ideally the instructions you give it are enough for it to get to the finish state where it submits a pull request against your repo with the results.
I got lucky: my above prompt worked exactly as intended.
Codex churned for a 13 minutes! I was sat chatting in a coffee shop, occasionally checking the logs to see what it was up to.
It tried a whole bunch of approaches, all involving running the Playwright Python library to interact with the site. You can see the full transcript here. It includes notes like "Looks like xxd isn’t installed. I’ll grab “vim-common” or “xxd” to fix it.".
Eventually it downloaded an enormous obfuscated chunk of JavaScript called schedule-overview-main-1752724893152.js (316KB) and then ran a complex sequence of grep, grep, sed, strings, xxd and dd commands against it to figure out the location of the raw schedule data in order to extract it out.
Here’s the eventual extract_schedule.py Python script it wrote, which uses Playwright to save that schedule-overview-main-1752724893152.js file and then extracts the raw data using the following code (which calls Node.js inside Python, just so it can use the JavaScript eval() function):
node_script = ( "const fs=require('fs');" f"const d=fs.readFileSync('{tmp_path}','utf8');" "const m=d.match(/var oo=(\\{.*?\\});/s);" "if(!m){throw new Error('not found');}" "const obj=eval('(' + m[1] + ')');" f"fs.writeFileSync('{OUTPUT_FILE}', JSON.stringify(obj, null, 2));" ) subprocess.run(['node', '-e', node_script], check=True)
As instructed, it then filed a PR against my repo. It included the Python Playwright script, but more importantly it also included that full extracted schedule.json file. That meant I now had the schedule data, with a raw.githubusercontent.com URL with open CORS headers that could be fetched by a web app!
Building the web app
Now that I had the data, the next step was to build a web application to preview it and serve it up in a more useful format.
I decided I wanted two things: a nice mobile friendly interface for browsing the schedule, and mechanism for importing that schedule into a calendar application, such as Apple or Google Calendar.
It took me several false starts to get this to work. The biggest challenge was getting that 63KB of schedule JSON data into the app. I tried a few approaches here, all on my iPhone while sitting in coffee shop and later while driving with a friend to drop them off at the closest BART station.
- Using ChatGPT Canvas and o3, since unlike Claude Artifacts a Canvas can fetch data from remote URLs if you allow-list that domain. I later found out that this had worked when I viewed it on my laptop, but on my phone it threw errors so I gave up on it.
- Uploading the JSON to Claude and telling it to build an artifact that read the file directly—this failed with an error “undefined is not an object (evaluating ’window.fs.readFile’)”. The Claude 4 system prompt had lead me to expect this to work, I’m not sure why it didn’t.
- Having Claude copy the full JSON into the artifact. This took too long—typing out 63KB of JSON is not a sensible use of LLM tokens, and it flaked out on me when my connection went intermittent driving through a tunnel.
- Telling Claude to fetch from the URL to that schedule JSON instead. This was my last resort because the Claude Artifacts UI blocks access to external URLs, so you have to copy and paste the code out to a separate interface (on an iPhone, which still lacks a “select all” button) making for a frustrating process.
That final option worked! Here’s the full sequence of prompts I used with Claude to get to a working implementation—full transcript here:
Use your analyst tool to read this JSON file and show me the top level keys
This was to prime Claude—I wanted to remind it about its window.fs.readFile function and have it read enough of the JSON to understand the structure.
Build an artifact with no react that turns the schedule into a nice mobile friendly webpage - there are three days Friday, Saturday and Sunday, which corresponded to the 25th and 26th and 27th of July 2025
Don’t copy the raw JSON over to the artifact - use your fs function to read it instead
Also include a button to download ICS at the top of the page which downloads a ICS version of the schedule
I had noticed that the schedule data had keys for “friday” and “saturday” and “sunday” but no indication of the dates, so I told it those. It turned out later I’d got these wrong!
This got me a version of the page that failed with an error, because that fs.readFile() couldn’t load the data from the artifact for some reason. So I fixed that with:
Change it so instead of using the readFile thing it fetches the same JSON from https://raw.githubusercontent.com/simonw/.github/f671bf57f7c20a4a7a5b0642837811e37c557499/schedule.json
... then copied the HTML out to a Gist and previewed it with gistpreview.github.io—here’s that preview.
Then we spot-checked it, since there are so many ways this could have gone wrong. Thankfully the schedule JSON itself never round-tripped through an LLM so we didn’t need to worry about hallucinated session details, but this was almost pure vibe coding so there was a big risk of a mistake sneaking through.
I’d set myself a deadline of “by the time we drop my friend at the BART station” and I hit that deadline with just seconds to spare. I pasted the resulting HTML into my simonw/tools GitHub repo using the GitHub mobile web interface which deployed it to that final tools.simonwillison.net/open-sauce-2025 URL.
... then we noticed that we had missed a bug: I had given it the dates of “25th and 26th and 27th of July 2025” but actually that was a week too late, the correct dates were July 18th-20th.
Thankfully I have Codex configured against my simonw/tools repo as well, so fixing that was a case of prompting a new Codex session with:
The open sauce schedule got the dates wrong - Friday is 18 July 2025 and Saturday is 19 and Sunday is 20 - fix it
Here’s that Codex transcript, which resulted in this PR which I landed and deployed, again using the GitHub mobile web interface.
What this all demonstrates
So, to recap: I was able to scrape a website (without even a view source too), turn the resulting JSON data into a mobile-friendly website, add an ICS export feature and deploy the results to a static hosting platform (GitHub Pages) working entirely on my phone.
If I’d had a laptop this project would have been faster, but honestly aside from a little bit more hands-on debugging I wouldn’t have gone about it in a particularly different way.
I was able to do other stuff at the same time—the Codex scraping project ran entirely autonomously, and the app build itself was more involved only because I had to work around the limitations of the tools I was using in terms of fetching data from external sources.
As usual with this stuff, my 25+ years of previous web development experience was critical to being able to execute the project. I knew about Codex, and Artifacts, and GitHub, and Playwright, and CORS headers, and Artifacts sandbox limitations, and the capabilities of ICS files on mobile phones.
This whole thing was so much fun! Being able to spin up multiple coding agents directly from my phone and have them solve quite complex problems while only paying partial attention to the details is a solid demonstration of why I continue to enjoying exploring the edges of AI-assisted programming.
Update: I removed the speaker avatars
Here’s a beautiful cautionary tale about the dangers of vibe-coding on a phone with no access to performance profiling tools. A commenter on Hacker News pointed out:
The web app makes 176 requests and downloads 130 megabytes.
And yeah, it did! Turns out those speaker avatar images weren’t optimized, and there were over 170 of them.
I told a fresh Codex instance “Remove the speaker avatar images from open-sauce-2025.html” and now the page weighs 93.58 KB—about 1,400 times smaller!
Update 2: Improved accessibility
That same commenter on Hacker News:
It’s also
<div>soup and largely inaccessible.
Yeah, this HTML isn’t great:
dayContainer.innerHTML = sessions.map(session => `
<div class="session-card">
<div class="session-header">
<div>
<span class="session-time">${session.time}</span>
<span class="length-badge">${session.length} min</span>
</div>
<div class="session-location">${session.where}</div>
</div>I opened an issue and had both Claude Code and Codex look at it. Claude Code failed to submit a PR for some reason, but Codex opened one with a fix that sounded good to me when I tried it with VoiceOver on iOS (using a Cloudflare Pages preview) so I landed that. Here’s the diff, which added a hidden “skip to content” link, some aria- attributes on buttons and upgraded the HTML to use <h3> for the session titles.
Next time I’ll remember to specify accessibility as a requirement in the initial prompt. I’m disappointed that Claude didn’t consider that without me having to ask.
More recent articles
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026