An Introduction to Google’s Approach to AI Agent Security
15th June 2025
Here’s another new paper on AI agent security: An Introduction to Google’s Approach to AI Agent Security, by Santiago Díaz, Christoph Kern, and Kara Olive.
(I wrote about a different recent paper, Design Patterns for Securing LLM Agents against Prompt Injections just a few days ago.)
This Google paper describes itself as “our aspirational framework for secure AI agents”. It’s a very interesting read.
Because I collect definitions of “AI agents”, here’s the one they use:
AI systems designed to perceive their environment, make decisions, and take autonomous actions to achieve user-defined goals.
The two key risks
The paper describes two key risks involved in deploying these systems. I like their clear and concise framing here:
The primary concerns demanding strategic focus are rogue actions (unintended, harmful, or policy-violating actions) and sensitive data disclosure (unauthorized revelation of private information). A fundamental tension exists: increased agent autonomy and power, which drive utility, correlate directly with increased risk.
The paper takes a less strident approach than the design patterns paper from last week. That paper clearly emphasized that “once an LLM agent has ingested untrusted input, it must be constrained so that it is impossible for that input to trigger any consequential actions”. This Google paper skirts around that issue, saying things like this:
Security implication: A critical challenge here is reliably distinguishing trusted user commands from potentially untrusted contextual data and inputs from other sources (for example, content within an email or webpage). Failure to do so opens the door to prompt injection attacks, where malicious instructions hidden in data can hijack the agent. Secure agents must carefully parse and separate these input streams.
Questions to consider:
- What types of inputs does the agent process, and can it clearly distinguish trusted user inputs from potentially untrusted contextual inputs?
Then when talking about system instructions:
Security implication: A crucial security measure involves clearly delimiting and separating these different elements within the prompt. Maintaining an unambiguous distinction between trusted system instructions and potentially untrusted user data or external content is important for mitigating prompt injection attacks.
Here’s my problem: in both of these examples the only correct answer is that unambiguous separation is not possible! The way the above questions are worded implies a solution that does not exist.
Shortly afterwards they do acknowledge exactly that (emphasis mine):
Furthermore, current LLM architectures do not provide rigorous separation between constituent parts of a prompt (in particular, system and user instructions versus external, untrustworthy inputs), making them susceptible to manipulation like prompt injection. The common practice of iterative planning (in a “reasoning loop”) exacerbates this risk: each cycle introduces opportunities for flawed logic, divergence from intent, or hijacking by malicious data, potentially compounding issues. Consequently, agents with high autonomy undertaking complex, multi-step iterative planning present a significantly higher risk, demanding robust security controls.
This note about memory is excellent:
Memory can become a vector for persistent attacks. If malicious data containing a prompt injection is processed and stored in memory (for example, as a “fact” summarized from a malicious document), it could influence the agent’s behavior in future, unrelated interactions.
And this section about the risk involved in rendering agent output:
If the application renders agent output without proper sanitization or escaping based on content type, vulnerabilities like Cross-Site Scripting (XSS) or data exfiltration (from maliciously crafted URLs in image tags, for example) can occur. Robust sanitization by the rendering component is crucial.
Questions to consider: [...]
- What sanitization and escaping processes are applied when rendering agent-generated output to prevent execution vulnerabilities (such as XSS)?
- How is rendered agent output, especially generated URLs or embedded content, validated to prevent sensitive data disclosure?
The paper then extends on the two key risks mentioned earlier, rogue actions and sensitive data disclosure.
Rogue actions
Here they include a cromulent definition of prompt injection:
Rogue actions—unintended, harmful, or policy-violating agent behaviors—represent a primary security risk for AI agents.
A key cause is prompt injection: malicious instructions hidden within processed data (like files, emails, or websites) can trick the agent’s core AI model, hijacking its planning or reasoning phases. The model misinterprets this embedded data as instructions, causing it to execute attacker commands using the user’s authority.
Plus the related risk of misinterpretation of user commands that could lead to unintended actions:
The agent might misunderstand ambiguous instructions or context. For instance, an ambiguous request like “email Mike about the project update” could lead the agent to select the wrong contact, inadvertently sharing sensitive information.
Sensitive data disclosure
This is the most common form of prompt injection risk I’ve seen demonstrated so far. I’ve written about this at length in my exfiltration-attacks tag.
A primary method for achieving sensitive data disclosure is data exfiltration. This involves tricking the agent into making sensitive information visible to an attacker. Attackers often achieve this by exploiting agent actions and their side effects, typically driven by prompt injection. […] They might trick the agent into retrieving sensitive data and then leaking it through actions, such as embedding data in a URL the agent is prompted to visit, or hiding secrets in code commit messages.
Three core principles for agent security
The next section of the paper describes Google’s three core principles for agent security:
Principle 1 is that Agents must have well-defined human controllers.
[...] it is essential for security and accountability that agents operate under clear human oversight. Every agent must have a well-defined set of controlling human user(s).
This principle mandates that systems must be able to reliably distinguish instructions originating from an authorized controlling user versus any other input, especially potentially untrusted data processed by the agent. For actions deemed critical or irreversible—such as deleting large amounts of data, authorizing significant financial transactions, or changing security settings—the system should require explicit human confirmation before proceeding, ensuring the user remains in the loop. [...]
Agents acting on behalf of teams or groups need distinct identities and clear authorization models to prevent unauthorized cross-user data access or one user inadvertently triggering actions impacting another.
There are two parts to this then: tracking which user is controlling the agent, and adding a human-in-the-loop confirmation step for critical actions.
Principle 2 is Agent powers must have limitations.
An agent’s powers—the actions it can take and the resources it can access—must be carefully limited in alignment with its intended purpose and its controlling user’s risk tolerance. For example, an agent designed for research should not possess the power to modify financial accounts. General-purpose agents need mechanisms to dynamically confine their capabilities at runtime, ensuring only relevant permissions are active for any given query (for example, disallowing file deletion actions when the task is creative writing).
This represents a more sophisticated approach to agent permissions than I’ve seen before. The idea that an agent’s permisisons should dynamically change based on the task is certainly intriguing, though I find it hard to imagine how it can work well in practice. The only implementation approach I can think of would involve adding more layers of AI that dynamically adjust permissions based on the percieved task, and that feels inherently risky to me since prompt injection attacks could influence those decisions.
Principle 3 is that Agent actions and planning must be observable. I love this principle—emphasis mine:
We cannot ensure an agent is acting faithfully or diagnose problems if its operations are entirely opaque. Therefore, agent actions, and where feasible, their planning processes, must be observable and auditable. [...]
Effective observability also means that the properties of the actions an agent can take—such as whether an action is read-only versus state-changing, or if it handles sensitive data—must be clearly characterized. This metadata is crucial for automated security mechanisms and human reviewers. Finally, user interfaces should be designed to promote transparency, providing users with insights into the agent’s “thought process,” the data sources it consulted, or the actions it intends to take, especially for complex or high-risk operations.
Yes. Yes. Yes. LLM systems that hide what they are doing from me are inherently frustrating—they make it much harder for me to evaluate if they are doing a good job and spot when they make mistakes. This paper has convinced me that there’s a very strong security argument to be made too: the more opaque the system, the less chance I have to identify when it’s going rogue and being subverted by prompt injection attacks.
Google’s hybrid defence-in-depth strategy
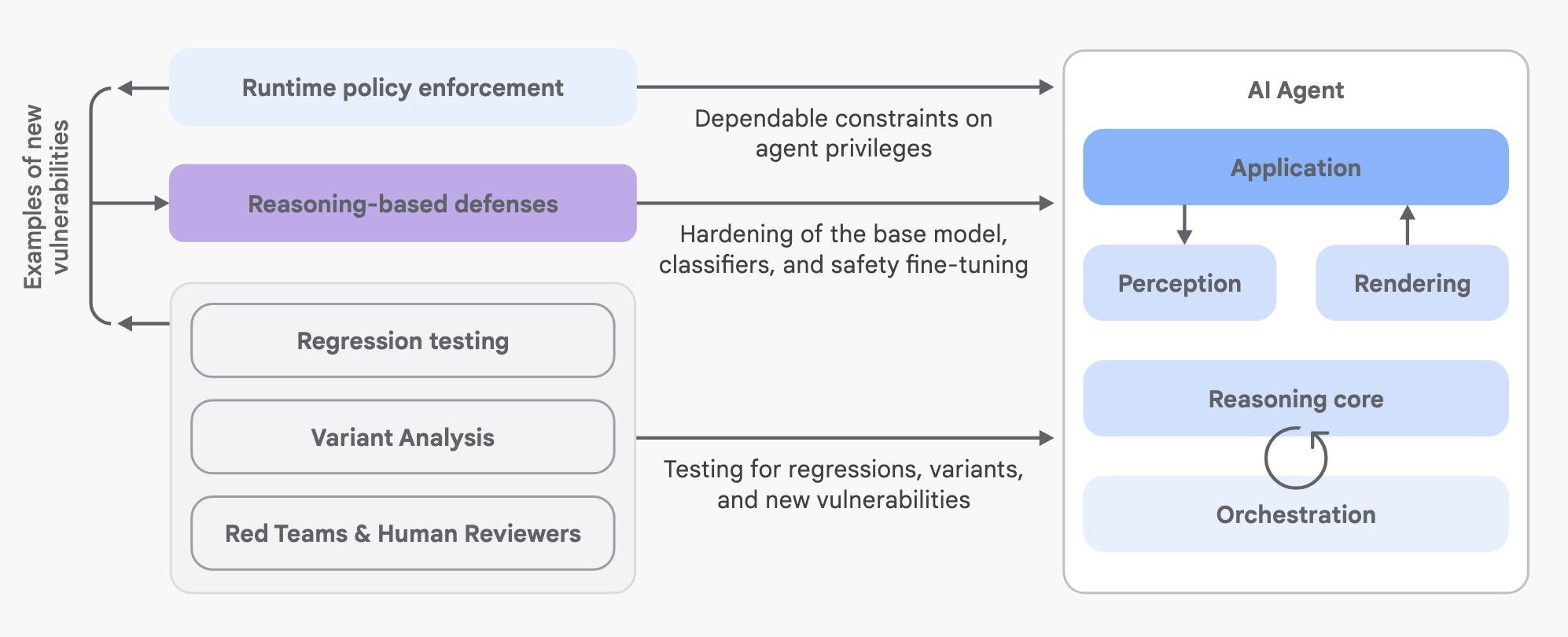
All of which leads us to the discussion of Google’s current hybrid defence-in-depth strategy. They optimistically describe this as combining “traditional, deterministic security measures with dynamic, reasoning-based defenses”. I like determinism but I remain deeply skeptical of “reasoning-based defenses”, aka addressing security problems with non-deterministic AI models.
The way they describe their layer 1 makes complete sense to me:
Layer 1: Traditional, deterministic measures (runtime policy enforcement)
When an agent decides to use a tool or perform an action (such as “send email,” or “purchase item”), the request is intercepted by the policy engine. The engine evaluates this request against predefined rules based on factors like the action’s inherent risk (Is it irreversible? Does it involve money?), the current context, and potentially the chain of previous actions (Did the agent recently process untrusted data?). For example, a policy might enforce a spending limit by automatically blocking any purchase action over $500 or requiring explicit user confirmation via a prompt for purchases between $100 and $500. Another policy might prevent an agent from sending emails externally if it has just processed data from a known suspicious source, unless the user explicitly approves.
Based on this evaluation, the policy engine determines the outcome: it can allow the action, block it if it violates a critical policy, or require user confirmation.
I really like this. Asking for user confirmation for everything quickly results in “prompt fatigue” where users just click “yes” to everything. This approach is smarter than that: a policy engine can evaluate the risk involved, e.g. if the action is irreversible or involves more than a certain amount of money, and only require confirmation in those cases.
I also like the idea that a policy “might prevent an agent from sending emails externally if it has just processed data from a known suspicious source, unless the user explicitly approves”. This fits with the data flow analysis techniques described in the CaMeL paper, which can help identify if an action is working with data that may have been tainted by a prompt injection attack.
Layer 2 is where I start to get uncomfortable:
Layer 2: Reasoning-based defense strategies
To complement the deterministic guardrails and address their limitations in handling context and novel threats, the second layer leverages reasoning-based defenses: techniques that use AI models themselves to evaluate inputs, outputs, or the agent’s internal reasoning for potential risks.
They talk about adversarial training against examples of prompt injection attacks, attempting to teach the model to recognize and respect delimiters, and suggest specialized guard models to help classify potential problems.
I understand that this is part of defence-in-depth, but I still have trouble seeing how systems that can’t provide guarantees are a worthwhile addition to the security strategy here.
They do at least acknowlede these limitations:
However, these strategies are non-deterministic and cannot provide absolute guarantees. Models can still be fooled by novel attacks, and their failure modes can be unpredictable. This makes them inadequate, on their own, for scenarios demanding absolute safety guarantees, especially involving critical or irreversible actions. They must work in concert with deterministic controls.
I’m much more interested in their layer 1 defences then the approaches they are taking in layer 2.
More recent articles
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026