Saturday, 18th October 2025
Andrej Karpathy — AGI is still a decade away (via) Extremely high signal 2 hour 25 minute (!) conversation between Andrej Karpathy and Dwarkesh Patel.
It starts with Andrej's claim that "the year of agents" is actually more likely to take a decade. Seeing as I accepted 2025 as the year of agents just yesterday this instantly caught my attention!
It turns out Andrej is using a different definition of agents to the one that I prefer - emphasis mine:
When you’re talking about an agent, or what the labs have in mind and maybe what I have in mind as well, you should think of it almost like an employee or an intern that you would hire to work with you. For example, you work with some employees here. When would you prefer to have an agent like Claude or Codex do that work?
Currently, of course they can’t. What would it take for them to be able to do that? Why don’t you do it today? The reason you don’t do it today is because they just don’t work. They don’t have enough intelligence, they’re not multimodal enough, they can’t do computer use and all this stuff.
They don’t do a lot of the things you’ve alluded to earlier. They don’t have continual learning. You can’t just tell them something and they’ll remember it. They’re cognitively lacking and it’s just not working. It will take about a decade to work through all of those issues.
Yeah, continual learning human-replacement agents definitely isn't happening in 2025! Coding agents that are really good at running tools in the loop on the other hand are here already.
I loved this bit introducing an analogy of LLMs as ghosts or spirits, as opposed to having brains like animals or humans:
Brains just came from a very different process, and I’m very hesitant to take inspiration from it because we’re not actually running that process. In my post, I said we’re not building animals. We’re building ghosts or spirits or whatever people want to call it, because we’re not doing training by evolution. We’re doing training by imitation of humans and the data that they’ve put on the Internet.
You end up with these ethereal spirit entities because they’re fully digital and they’re mimicking humans. It’s a different kind of intelligence. If you imagine a space of intelligences, we’re starting off at a different point almost. We’re not really building animals. But it’s also possible to make them a bit more animal-like over time, and I think we should be doing that.
The post Andrej mentions is Animals vs Ghosts on his blog.
Dwarkesh asked Andrej about this tweet where he said that Claude Code and Codex CLI "didn't work well enough at all and net unhelpful" for his nanochat project. Andrej responded:
[...] So the agents are pretty good, for example, if you’re doing boilerplate stuff. Boilerplate code that’s just copy-paste stuff, they’re very good at that. They’re very good at stuff that occurs very often on the Internet because there are lots of examples of it in the training sets of these models. There are features of things where the models will do very well.
I would say nanochat is not an example of those because it’s a fairly unique repository. There’s not that much code in the way that I’ve structured it. It’s not boilerplate code. It’s intellectually intense code almost, and everything has to be very precisely arranged. The models have so many cognitive deficits. One example, they kept misunderstanding the code because they have too much memory from all the typical ways of doing things on the Internet that I just wasn’t adopting.
Update: Here's an essay length tweet from Andrej clarifying a whole bunch of the things he talked about on the podcast.
The AI water issue is fake. Andy Masley (previously):
All U.S. data centers (which mostly support the internet, not AI) used 200--250 million gallons of freshwater daily in 2023. The U.S. consumes approximately 132 billion gallons of freshwater daily. The U.S. circulates a lot more water day to day, but to be extra conservative I'll stick to this measure of its consumptive use, see here for a breakdown of how the U.S. uses water. So data centers in the U.S. consumed approximately 0.2% of the nation's freshwater in 2023. [...]
The average American’s consumptive lifestyle freshwater footprint is 422 gallons per day. This means that in 2023, AI data centers used as much water as the lifestyles of 25,000 Americans, 0.007% of the population. By 2030, they might use as much as the lifestyles of 250,000 Americans, 0.07% of the population.
Andy also points out that manufacturing a t-shirt uses the same amount of water as 1,300,000 prompts.
See also this TikTok by MyLifeIsAnRPG, who points out that the beef industry and fashion and textiles industries use an order of magnitude more water (~90x upwards) than data centers used for AI.
TIL: Exploring OpenAI’s deep research API model o4-mini-deep-research. I landed a PR by Manuel Solorzano adding pricing information to llm-prices.com for OpenAI's o4-mini-deep-research and o3-deep-research models, which they released in June and document here.
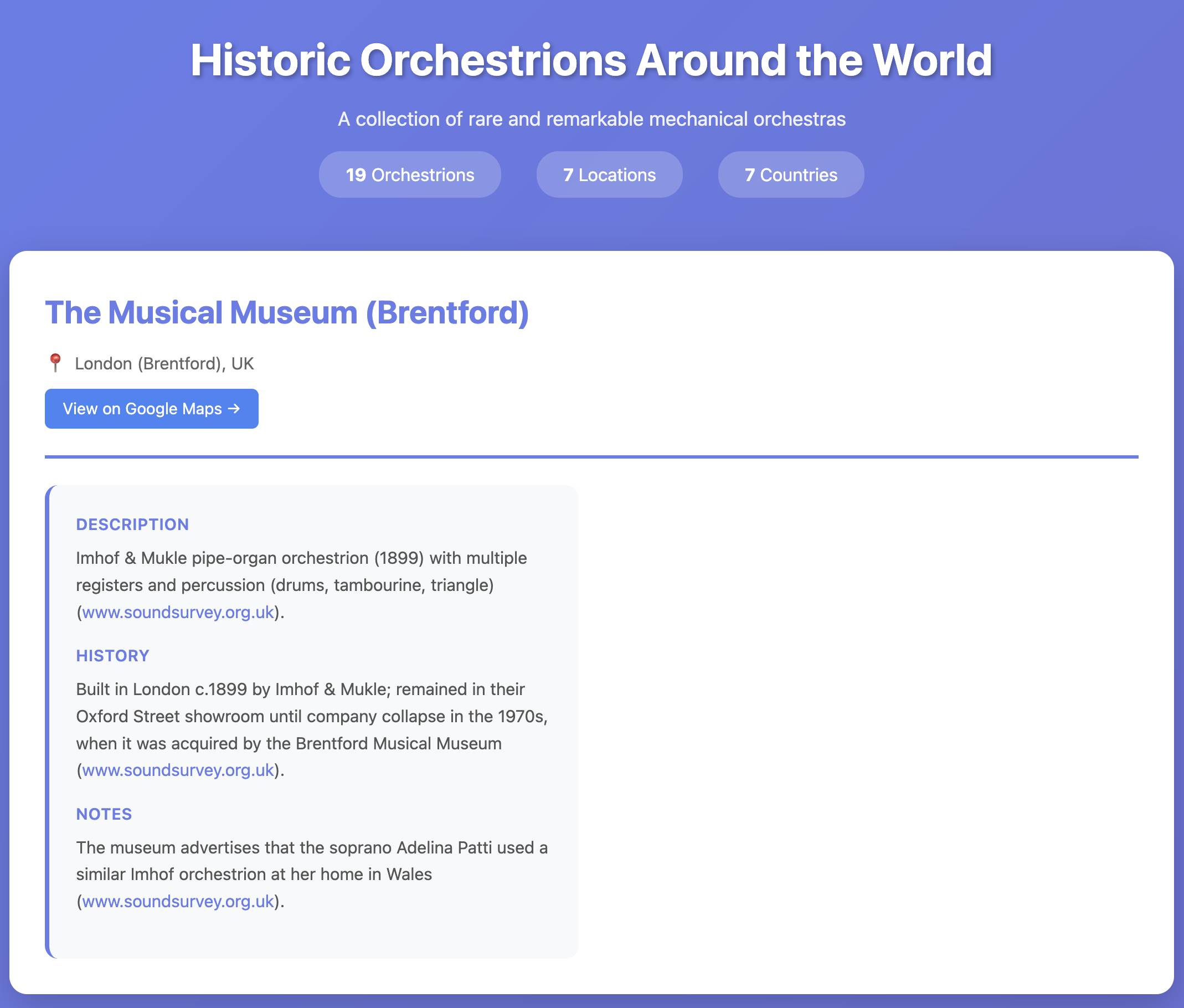
I realized I'd never tried these before, so I put o4-mini-deep-research through its paces researching locations of surviving orchestrions for me (I really like orchestrions).
The API cost me $1.10 and triggered a small flurry of extra vibe-coded tools, including this new tool for visualizing Responses API traces from deep research models and this mocked up page listing the 19 orchestrions it found (only one of which I have fact-checked myself).