Sunday, 7th September 2025
When I wrote about how good ChatGPT with GPT-5 is at search yesterday I nearly added a note about how comparatively disappointing Google's efforts around this are.
I'm glad I left that out, because it turns out Google's new "AI mode" is genuinely really good! It feels very similar to GPT-5 search but returns results much faster.
www.google.com/ai (not available in the EU, as I found out this morning since I'm staying in France for a few days.)
Here's what I got for the following question:
Anthropic but lots of physical books and cut them up and scan them for training data. Do any other AI labs do the same thing?
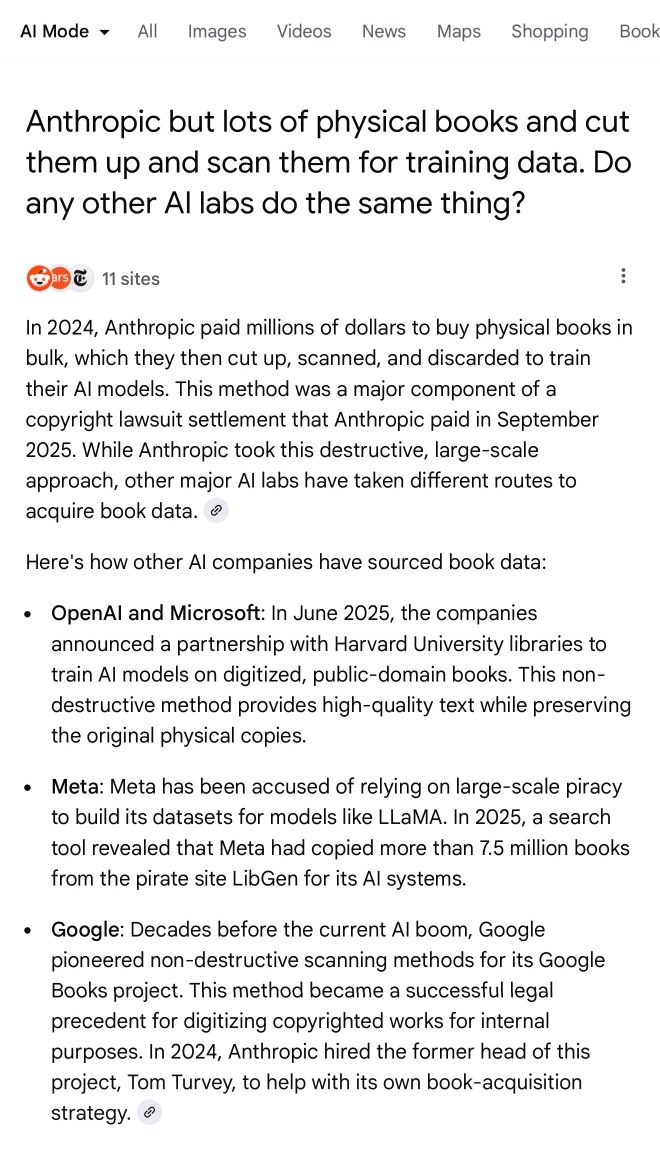
I'll be honest: I hadn't spent much time with AI mode for a couple of reasons:
- My expectations of "AI mode" were extremely low based on my terrible experience of "AI overviews"
- The name "AI mode" is so generic!
Based on some initial experiments I'm impressed - Google finally seem to be taking full advantage of their search infrastructure for building out truly great AI-assisted search.
I do have one disappointment: AI mode will tell you that it's "running 5 searches" but it won't tell you what those searches are! Seeing the searches that were run is really important for me in evaluating the likely quality of the end results. I've had the same problem with Google's Gemini app in the past - the lack of transparency as to what it's doing really damages my trust.
The SIFT method (via) The SIFT method is "an evaluation strategy developed by digital literacy expert, Mike Caulfield, to help determine whether online content can be trusted for credible or reliable sources of information."
This looks extremely useful as a framework for helping people more effectively consume information online (increasingly gathered with the help of LLMs).
- Stop. "Be aware of your emotional response to the headline or information in the article" to protect against clickbait, and don't read further or share until you've applied the other three steps.
- Investigate the Source. Apply lateral reading, checking what others say about the source rather than just trusting their "about" page.
- Find Better Coverage. "Use lateral reading to see if you can find other sources corroborating the same information or disputing it" and consult trusted fact checkers if necessary.
- Trace Claims, Quotes, and Media to their Original Context. Try to find the original report or referenced material to learn more and check it isn't being represented out of context.
This framework really resonates with me: it formally captures and improves on a bunch of informal techniques I've tried to apply in my own work.
I agree with the intellectual substance of virtually every common critique of AI. And it's very clear that turning those critiques into a competition about who can frame them in the most scathing way online has done zero to slow down adoption, even if much of that is due to default bundling.
At what point are folks going to try literally any other tactic than condescending rants? Does it matter that LLM apps are at the top of virtually every app store nearly every day because individual people are choosing to download them, and the criticism hasn't been effective in slowing that?
Is the LLM response wrong, or have you just failed to iterate it? (via) More from Mike Caulfield (see also the SIFT method). He starts with a fantastic example of Google's AI mode usually correctly handling a common piece of misinformation but occasionally falling for it (the curse of non-deterministic systems), then shows an example if what he calls a "sorting prompt" as a follow-up:
What is the evidence for and against this being a real photo of Shirley Slade?
The response starts with a non-committal "there is compelling evidence for and against...", then by the end has firmly convinced itself that the photo is indeed a fake. It reads like a fact-checking variant of "think step by step".
Mike neatly describes a problem I've also observed recently where "hallucination" is frequently mis-applied as meaning any time a model makes a mistake:
The term hallucination has become nearly worthless in the LLM discourse. It initially described a very weird, mostly non-humanlike behavior where LLMs would make up things out of whole cloth that did not seem to exist as claims referenced any known source material or claims inferable from any known source material. Hallucinations as stuff made up out of nothing. Subsequently people began calling any error or imperfect summary a hallucination, rendering the term worthless.
In this example is the initial incorrect answers were not hallucinations: they correctly summarized online content that contained misinformation. The trick then is to encourage the model to look further, using "sorting prompts" like these:
- Facts and misconceptions and hype about what I posted
- What is the evidence for and against the claim I posted
- Look at the most recent information on this issue, summarize how it shifts the analysis (if at all), and provide link to the latest info
I appreciated this closing footnote:
Should platforms have more features to nudge users to this sort of iteration? Yes. They should. Getting people to iterate investigation rather than argue with LLMs would be a good first step out of this mess that the chatbot model has created.