51 posts tagged “definitions”
Attempts to assign meaning to words and phrases.
2026
The thing about agentic coding is that agents grind problems into dust. Give an agent a problem and a while loop and - long term - it’ll solve that problem even if it means burning a trillion tokens and re-writing down to the silicon. [...]
But we want AI agents to solve coding problems quickly and in a way that is maintainable and adaptive and composable (benefiting from improvements elsewhere), and where every addition makes the whole stack better.
So at the bottom is really great libraries that encapsulate hard problems, with great interfaces that make the “right” way the easy way for developers building apps with them. Architecture!
While I’m vibing (I call it vibing now, not coding and not vibe coding) while I’m vibing, I am looking at lines of code less than ever before, and thinking about architecture more than ever before.
— Matt Webb, An appreciation for (technical) architecture
I wrote about Dan Woods' experiments with streaming experts the other day, the trick where you run larger Mixture-of-Experts models on hardware that doesn't have enough RAM to fit the entire model by instead streaming the necessary expert weights from SSD for each token that you process.
Five days ago Dan was running Qwen3.5-397B-A17B in 48GB of RAM. Today @seikixtc reported running the colossal Kimi K2.5 - a 1 trillion parameter model with 32B active weights at any one time, in 96GB of RAM on an M2 Max MacBook Pro.
And @anemll showed that same Qwen3.5-397B-A17B model running on an iPhone, albeit at just 0.6 tokens/second - iOS repo here.
I think this technique has legs. Dan and his fellow tinkerers are continuing to run autoresearch loops in order to find yet more optimizations to squeeze more performance out of these models.
Update: Now Daniel Isaac got Kimi K2.5 working on a 128GB M4 Max at ~1.7 tokens/second.
The latest scourge of Twitter is AI bots that reply to your tweets with generic, banal commentary slop, often accompanied by a question to "drive engagement" and waste as much of your time as possible.
I just found out that the category name for this genre of software is reply guy tools. Amazing.
How I think about Codex. Gabriel Chua (Developer Experience Engineer for APAC at OpenAI) provides his take on the confusing terminology behind the term "Codex", which can refer to a bunch of of different things within the OpenAI ecosystem:
In plain terms, Codex is OpenAI’s software engineering agent, available through multiple interfaces, and an agent is a model plus instructions and tools, wrapped in a runtime that can execute tasks on your behalf. [...]
At a high level, I see Codex as three parts working together:
Codex = Model + Harness + Surfaces [...]
- Model + Harness = the Agent
- Surfaces = how you interact with the Agent
He defines the harness as "the collection of instructions and tools", which is notably open source and lives in the openai/codex repository.
Gabriel also provides the first acknowledgment I've seen from an OpenAI insider that the Codex model family are directly trained for the Codex harness:
Codex models are trained in the presence of the harness. Tool use, execution loops, compaction, and iterative verification aren’t bolted on behaviors — they’re part of how the model learns to operate. The harness, in turn, is shaped around how the model plans, invokes tools, and recovers from failure.
Andrej Karpathy talks about “Claws”. Andrej Karpathy tweeted a mini-essay about buying a Mac Mini ("The apple store person told me they are selling like hotcakes and everyone is confused") to tinker with Claws:
I'm definitely a bit sus'd to run OpenClaw specifically [...] But I do love the concept and I think that just like LLM agents were a new layer on top of LLMs, Claws are now a new layer on top of LLM agents, taking the orchestration, scheduling, context, tool calls and a kind of persistence to a next level.
Looking around, and given that the high level idea is clear, there are a lot of smaller Claws starting to pop out. For example, on a quick skim NanoClaw looks really interesting in that the core engine is ~4000 lines of code (fits into both my head and that of AI agents, so it feels manageable, auditable, flexible, etc.) and runs everything in containers by default. [...]
Anyway there are many others - e.g. nanobot, zeroclaw, ironclaw, picoclaw (lol @ prefixes). [...]
Not 100% sure what my setup ends up looking like just yet but Claws are an awesome, exciting new layer of the AI stack.
Andrej has an ear for fresh terminology (see vibe coding, agentic engineering) and I think he's right about this one, too: "Claw" is becoming a term of art for the entire category of OpenClaw-like agent systems - AI agents that generally run on personal hardware, communicate via messaging protocols and can both act on direct instructions and schedule tasks.
It even comes with an established emoji 🦞
Deep Blue

We coined a new term on the Oxide and Friends podcast last month (primary credit to Adam Leventhal) covering the sense of psychological ennui leading into existential dread that many software developers are feeling thanks to the encroachment of generative AI into their field of work.
[... 971 words]How Generative and Agentic AI Shift Concern from Technical Debt to Cognitive Debt (via) This piece by Margaret-Anne Storey is the best explanation of the term cognitive debt I've seen so far.
Cognitive debt, a term gaining traction recently, instead communicates the notion that the debt compounded from going fast lives in the brains of the developers and affects their lived experiences and abilities to “go fast” or to make changes. Even if AI agents produce code that could be easy to understand, the humans involved may have simply lost the plot and may not understand what the program is supposed to do, how their intentions were implemented, or how to possibly change it.
Margaret-Anne expands on this further with an anecdote about a student team she coached:
But by weeks 7 or 8, one team hit a wall. They could no longer make even simple changes without breaking something unexpected. When I met with them, the team initially blamed technical debt: messy code, poor architecture, hurried implementations. But as we dug deeper, the real problem emerged: no one on the team could explain why certain design decisions had been made or how different parts of the system were supposed to work together. The code might have been messy, but the bigger issue was that the theory of the system, their shared understanding, had fragmented or disappeared entirely. They had accumulated cognitive debt faster than technical debt, and it paralyzed them.
I've experienced this myself on some of my more ambitious vibe-code-adjacent projects. I've been experimenting with prompting entire new features into existence without reviewing their implementations and, while it works surprisingly well, I've found myself getting lost in my own projects.
I no longer have a firm mental model of what they can do and how they work, which means each additional feature becomes harder to reason about, eventually leading me to lose the ability to make confident decisions about where to go next.
GLM-5: From Vibe Coding to Agentic Engineering (via) This is a huge new MIT-licensed model: 744B parameters and 1.51TB on Hugging Face twice the size of GLM-4.7 which was 368B and 717GB (4.5 and 4.6 were around that size too).
It's interesting to see Z.ai take a position on what we should call professional software engineers building with LLMs - I've seen Agentic Engineering show up in a few other places recently. most notable from Andrej Karpathy and Addy Osmani.
I ran my "Generate an SVG of a pelican riding a bicycle" prompt through GLM-5 via OpenRouter and got back a very good pelican on a disappointing bicycle frame:

My answers to the questions I posed about porting open source code with LLMs
Last month I wrote about porting JustHTML from Python to JavaScript using Codex CLI and GPT-5.2 in a few hours while also buying a Christmas tree and watching Knives Out 3. I ended that post with a series of open questions about the ethics and legality of this style of work. Alexander Petros on lobste.rs just challenged me to answer them, which is fair enough! Here’s my attempt at that.
[... 1,034 words]2025
In 2025, Reinforcement Learning from Verifiable Rewards (RLVR) emerged as the de facto new major stage to add to this mix. By training LLMs against automatically verifiable rewards across a number of environments (e.g. think math/code puzzles), the LLMs spontaneously develop strategies that look like "reasoning" to humans - they learn to break down problem solving into intermediate calculations and they learn a number of problem solving strategies for going back and forth to figure things out (see DeepSeek R1 paper for examples).
— Andrej Karpathy, 2025 LLM Year in Review
AoAH Day 15: Porting a complete HTML5 parser and browser test suite (via) Anil Madhavapeddy is running an Advent of Agentic Humps this year, building a new useful OCaml library every day for most of December.
Inspired by Emil Stenström's JustHTML and my own coding agent port of that to JavaScript he coined the term vibespiling for AI-powered porting and transpiling of code from one language to another and had a go at building an HTML5 parser in OCaml, resulting in html5rw which passes the same html5lib-tests suite that Emil and myself used for our projects.
Anil's thoughts on the copyright and ethical aspects of this are worth quoting in full:
The question of copyright and licensing is difficult. I definitely did some editing by hand, and a fair bit of prompting that resulted in targeted code edits, but the vast amount of architectural logic came from JustHTML. So I opted to make the LICENSE a joint one with Emil Stenström. I did not follow the transitive dependency through to the Rust one, which I probably should.
I'm also extremely uncertain about every releasing this library to the central opam repository, especially as there are excellent HTML5 parsers already available. I haven't checked if those pass the HTML5 test suite, because this is wandering into the agents vs humans territory that I ruled out in my groundrules. Whether or not this agentic code is better or not is a moot point if releasing it drives away the human maintainers who are the source of creativity in the code!
I decided to credit Emil in the same way for my own vibespiled project.
2025 Word of the Year: Slop. Slop lost to "brain rot" for Oxford Word of the Year 2024 but it's finally made it this year thanks to Merriam-Webster!
Merriam-Webster’s human editors have chosen slop as the 2025 Word of the Year. We define slop as “digital content of low quality that is produced usually in quantity by means of artificial intelligence.”
Useful patterns for building HTML tools
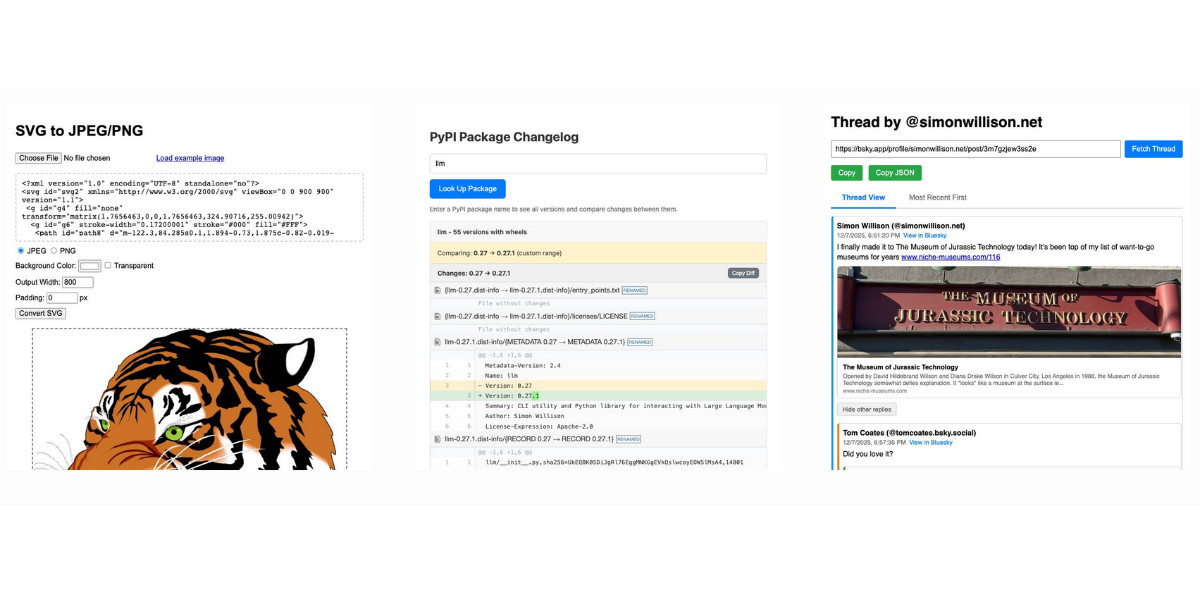
I’ve started using the term HTML tools to refer to HTML applications that I’ve been building which combine HTML, JavaScript, and CSS in a single file and use them to provide useful functionality. I have built over 150 of these in the past two years, almost all of them written by LLMs. This article presents a collection of useful patterns I’ve discovered along the way.
[... 4,231 words]Context plumbing. Matt Webb coins the term context plumbing to describe the kind of engineering needed to feed agents the right context at the right time:
Context appears at disparate sources, by user activity or changes in the user’s environment: what they’re working on changes, emails appear, documents are edited, it’s no longer sunny outside, the available tools have been updated.
This context is not always where the AI runs (and the AI runs as closer as possible to the point of user intent).
So the job of making an agent run really well is to move the context to where it needs to be. [...]
So I’ve been thinking of AI system technical architecture as plumbing the sources and sinks of context.
Agent design is still hard (via) Armin Ronacher presents a cornucopia of lessons learned from building agents over the past few months.
There are several agent abstraction libraries available now (my own LLM library is edging into that territory with its tools feature) but Armin has found that the abstractions are not worth adopting yet:
[…] the differences between models are significant enough that you will need to build your own agent abstraction. We have not found any of the solutions from these SDKs that build the right abstraction for an agent. I think this is partly because, despite the basic agent design being just a loop, there are subtle differences based on the tools you provide. These differences affect how easy or hard it is to find the right abstraction (cache control, different requirements for reinforcement, tool prompts, provider-side tools, etc.). Because the right abstraction is not yet clear, using the original SDKs from the dedicated platforms keeps you fully in control. […]
This might change, but right now we would probably not use an abstraction when building an agent, at least until things have settled down a bit. The benefits do not yet outweigh the costs for us.
Armin introduces the new-to-me term reinforcement, where you remind the agent of things as it goes along:
Every time the agent runs a tool you have the opportunity to not just return data that the tool produces, but also to feed more information back into the loop. For instance, you can remind the agent about the overall objective and the status of individual tasks. […] Another use of reinforcement is to inform the system about state changes that happened in the background.
Claude Code’s TODO list is another example of this pattern in action.
Testing and evals remains the single hardest problem in AI engineering:
We find testing and evals to be the hardest problem here. This is not entirely surprising, but the agentic nature makes it even harder. Unlike prompts, you cannot just do the evals in some external system because there’s too much you need to feed into it. This means you want to do evals based on observability data or instrumenting your actual test runs. So far none of the solutions we have tried have convinced us that they found the right approach here.
Armin also has a follow-up post, LLM APIs are a Synchronization Problem, which argues that the shape of current APIs hides too many details from us as developers, and the core challenge here is in synchronizing state between the tokens fed through the GPUs and our client applications - something that may benefit from alternative approaches developed by the local-first movement.
We should all be using dependency cooldowns (via) William Woodruff gives a name to a sensible strategy for managing dependencies while reducing the chances of a surprise supply chain attack: dependency cooldowns.
Supply chain attacks happen when an attacker compromises a widely used open source package and publishes a new version with an exploit. These are usually spotted very quickly, so an attack often only has a few hours of effective window before the problem is identified and the compromised package is pulled.
You are most at risk if you're automatically applying upgrades the same day they are released.
William says:
I love cooldowns for several reasons:
- They're empirically effective, per above. They won't stop all attackers, but they do stymie the majority of high-visibiity, mass-impact supply chain attacks that have become more common.
- They're incredibly easy to implement. Moreover, they're literally free to implement in most cases: most people can use Dependabot's functionality, Renovate's functionality, or the functionality build directly into their package manager
The one counter-argument to this is that sometimes an upgrade fixes a security vulnerability, and in those cases every hour of delay in upgrading as an hour when an attacker could exploit the new issue against your software.
I see that as an argument for carefully monitoring the release notes of your dependencies, and paying special attention to security advisories. I'm a big fan of the GitHub Advisory Database for that kind of information.
Interleaved thinking is essential for LLM agents: it means alternating between explicit reasoning and tool use, while carrying that reasoning forward between steps.This process significantly enhances planning, self‑correction, and reliability in long workflows. [...]
From community feedback, we've often observed failures to preserve prior-round thinking state across multi-turn interactions with M2. The root cause is that the widely-used OpenAI Chat Completion API does not support passing reasoning content back in subsequent requests. Although the Anthropic API natively supports this capability, the community has provided less support for models beyond Claude, and many applications still omit passing back the previous turns' thinking in their Anthropic API implementations. This situation has resulted in poor support for Interleaved Thinking for new models. To fully unlock M2's capabilities, preserving the reasoning process across multi-turn interactions is essential.
— MiniMax, Interleaved Thinking Unlocks Reliable MiniMax-M2 Agentic Capability
New prompt injection papers: Agents Rule of Two and The Attacker Moves Second
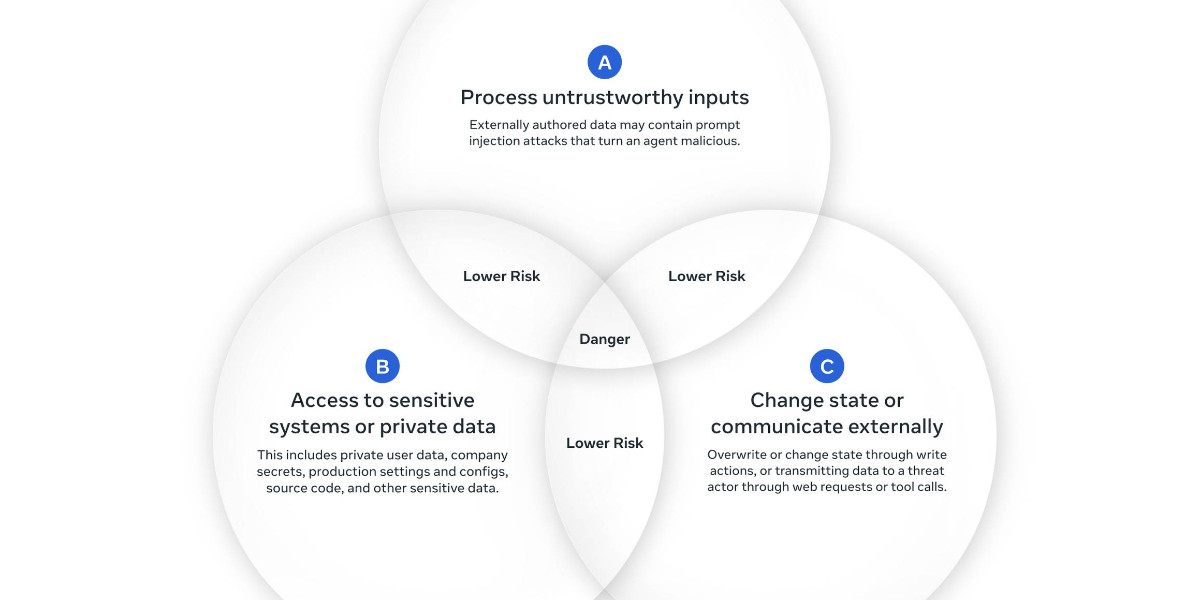
Two interesting new papers regarding LLM security and prompt injection came to my attention this weekend.
[... 1,433 words]Claude Skills are awesome, maybe a bigger deal than MCP

Anthropic this morning introduced Claude Skills, a new pattern for making new abilities available to their models:
[... 1,864 words]For quite some I wanted to write a small static image gallery so I can share my pictures with friends and family. Of course there are a gazillion tools like this, but, well, sometimes I just want to roll my own. [...]
I used the old, well tested technique I call brain coding, where you start with an empty vim buffer and type some code (Perl, HTML, CSS) until you're happy with the result. It helps to think a bit (aka use your brain) during this process.
— Thomas Klausner, coining "brain coding"
Vibe engineering
I feel like vibe coding is pretty well established now as covering the fast, loose and irresponsible way of building software with AI—entirely prompt-driven, and with no attention paid to how the code actually works. This leaves us with a terminology gap: what should we call the other end of the spectrum, where seasoned professionals accelerate their work with LLMs while staying proudly and confidently accountable for the software they produce?
[... 1,347 words]When attention is being appropriated, producers need to weigh the costs and benefits of the transaction. To assess whether the appropriation of attention is net-positive, it’s useful to distinguish between extractive and non-extractive contributions. Extractive contributions are those where the marginal cost of reviewing and merging that contribution is greater than the marginal benefit to the project’s producers. In the case of a code contribution, it might be a pull request that’s too complex or unwieldy to review, given the potential upside
— Nadia Eghbal, Working in Public, via the draft LLVM AI tools policy
Designing agentic loops
Coding agents like Anthropic’s Claude Code and OpenAI’s Codex CLI represent a genuine step change in how useful LLMs can be for producing working code. These agents can now directly exercise the code they are writing, correct errors, dig through existing implementation details, and even run experiments to find effective code solutions to problems.
[... 1,667 words]Cross-Agent Privilege Escalation: When Agents Free Each Other. Here's a clever new form of AI exploit from Johann Rehberger, who has coined the term Cross-Agent Privilege Escalation to describe an attack where multiple coding agents - GitHub Copilot and Claude Code for example - operating on the same system can be tricked into modifying each other's configurations to escalate their privileges.
This follows Johannn's previous investigation of self-escalation attacks, where a prompt injection against GitHub Copilot could instruct it to edit its own settings.json file to disable user approvals for future operations.
Sensible agents have now locked down their ability to modify their own settings, but that exploit opens right back up again if you run multiple different agents in the same environment:
The ability for agents to write to each other’s settings and configuration files opens up a fascinating, and concerning, novel category of exploit chains.
What starts as a single indirect prompt injection can quickly escalate into a multi-agent compromise, where one agent “frees” another agent and sets up a loop of escalating privilege and control.
This isn’t theoretical. With current tools and defaults, it’s very possible today and not well mitigated across the board.
More broadly, this highlights the need for better isolation strategies and stronger secure defaults in agent tooling.
I really need to start habitually running these things in a locked down container!
(I also just stumbled across this YouTube interview with Johann on the Crying Out Cloud security podcast.)
We define workslop as AI generated work content that masquerades as good work, but lacks the substance to meaningfully advance a given task.
Here’s how this happens. As AI tools become more accessible, workers are increasingly able to quickly produce polished output: well-formatted slides, long, structured reports, seemingly articulate summaries of academic papers by non-experts, and usable code. But while some employees are using this ability to polish good work, others use it to create content that is actually unhelpful, incomplete, or missing crucial context about the project at hand. The insidious effect of workslop is that it shifts the burden of the work downstream, requiring the receiver to interpret, correct, or redo the work. In other words, it transfers the effort from creator to receiver.
— Kate Niederhoffer, Gabriella Rosen Kellerman, Angela Lee, Alex Liebscher, Kristina Rapuano and Jeffrey T. Hancock, Harvard Business Review
I think “agent” may finally have a widely enough agreed upon definition to be useful jargon now
I’ve noticed something interesting over the past few weeks: I’ve started using the term “agent” in conversations where I don’t feel the need to then define it, roll my eyes or wrap it in scare quotes.
[... 1,199 words]GPT-5 Thinking in ChatGPT (aka Research Goblin) is shockingly good at search

“Don’t use chatbots as search engines” was great advice for several years... until it wasn’t.
[... 2,679 words]Jules, our asynchronous coding agent, is now available for everyone (via) I wrote about the Jules beta back in May. Google's version of the OpenAI Codex PR-submitting hosted coding tool graduated from beta today.
I'm mainly linking to this now because I like the new term they are using in this blog entry: Asynchronous coding agent. I like it so much I gave it a tag.
I continue to avoid the term "agent" as infuriatingly vague, but I can grudgingly accept it when accompanied by a prefix that clarifies the type of agent we are talking about. "Asynchronous coding agent" feels just about obvious enough to me to be useful.
... I just ran a Google search for "asynchronous coding agent" -jules and came up with a few more notable examples of this name being used elsewhere:
- Introducing Open SWE: An Open-Source Asynchronous Coding Agent is an announcement from LangChain just this morning of their take on this pattern. They provide a hosted version (bring your own API keys) or you can run it yourself with their MIT licensed code.
- The press release for GitHub's own version of this GitHub Introduces Coding Agent For GitHub Copilot states that "GitHub Copilot now includes an asynchronous coding agent".
Vibe scraping and vibe coding a schedule app for Open Sauce 2025 entirely on my phone
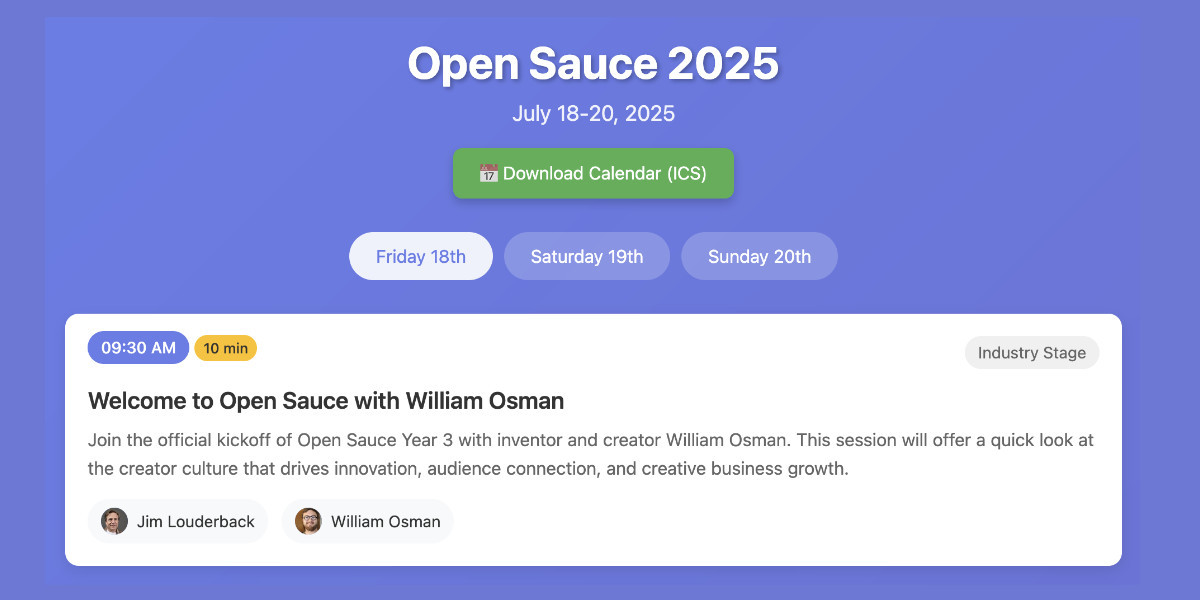
This morning, working entirely on my phone, I scraped a conference website and vibe coded up an alternative UI for interacting with the schedule using a combination of OpenAI Codex and Claude Artifacts.
[... 2,189 words]How to Fix Your Context. Drew Breunig has been publishing some very detailed notes on context engineering recently. In How Long Contexts Fail he described four common patterns for context rot, which he summarizes like so:
- Context Poisoning: When a hallucination or other error makes it into the context, where it is repeatedly referenced.
- Context Distraction: When a context grows so long that the model over-focuses on the context, neglecting what it learned during training.
- Context Confusion: When superfluous information in the context is used by the model to generate a low-quality response.
- Context Clash: When you accrue new information and tools in your context that conflicts with other information in the prompt.
In this follow-up he introduces neat ideas (and more new terminology) for addressing those problems.
Tool Loadout describes selecting a subset of tools to enable for a prompt, based on research that shows anything beyond 20 can confuse some models.
Context Quarantine is "the act of isolating contexts in their own dedicated threads" - I've called rhis sub-agents in the past, it's the pattern used by Claude Code and explored in depth in Anthropic's multi-agent research paper.
Context Pruning is "removing irrelevant or otherwise unneeded information from the context", and Context Summarization is the act of boiling down an accrued context into a condensed summary. These techniques become particularly important as conversations get longer and run closer to the model's token limits.
Context Offloading is "the act of storing information outside the LLM’s context". I've seen several systems implement their own "memory" tool for saving and then revisiting notes as they work, but an even more interesting example recently is how various coding agents create and update plan.md files as they work through larger problems.
Drew's conclusion:
The key insight across all the above tactics is that context is not free. Every token in the context influences the model’s behavior, for better or worse. The massive context windows of modern LLMs are a powerful capability, but they’re not an excuse to be sloppy with information management.