8 posts tagged “interpretability”
2025
Olmo 3 is a fully open LLM
Olmo is the LLM series from Ai2—the Allen institute for AI. Unlike most open weight models these are notable for including the full training data, training process and checkpoints along with those releases.
[... 1,834 words]Visual Features Across Modalities: SVG and ASCII Art Reveal Cross-Modal Understanding (via) New model interpretability research from Anthropic, this time focused on SVG and ASCII art generation.
We found that the same feature that activates over the eyes in an ASCII face also activates for eyes across diverse text-based modalities, including SVG code and prose in various languages. This is not limited to eyes – we found a number of cross-modal features that recognize specific concepts: from small components like mouths and ears within ASCII or SVG faces, to full visual depictions like dogs and cats. [...]
These features depend on the surrounding context within the visual depiction. For instance, an SVG circle element activates “eye” features only when positioned within a larger structure that activates “face” features.
And really, I can't not link to this one given the bonus they tagged on at the end!
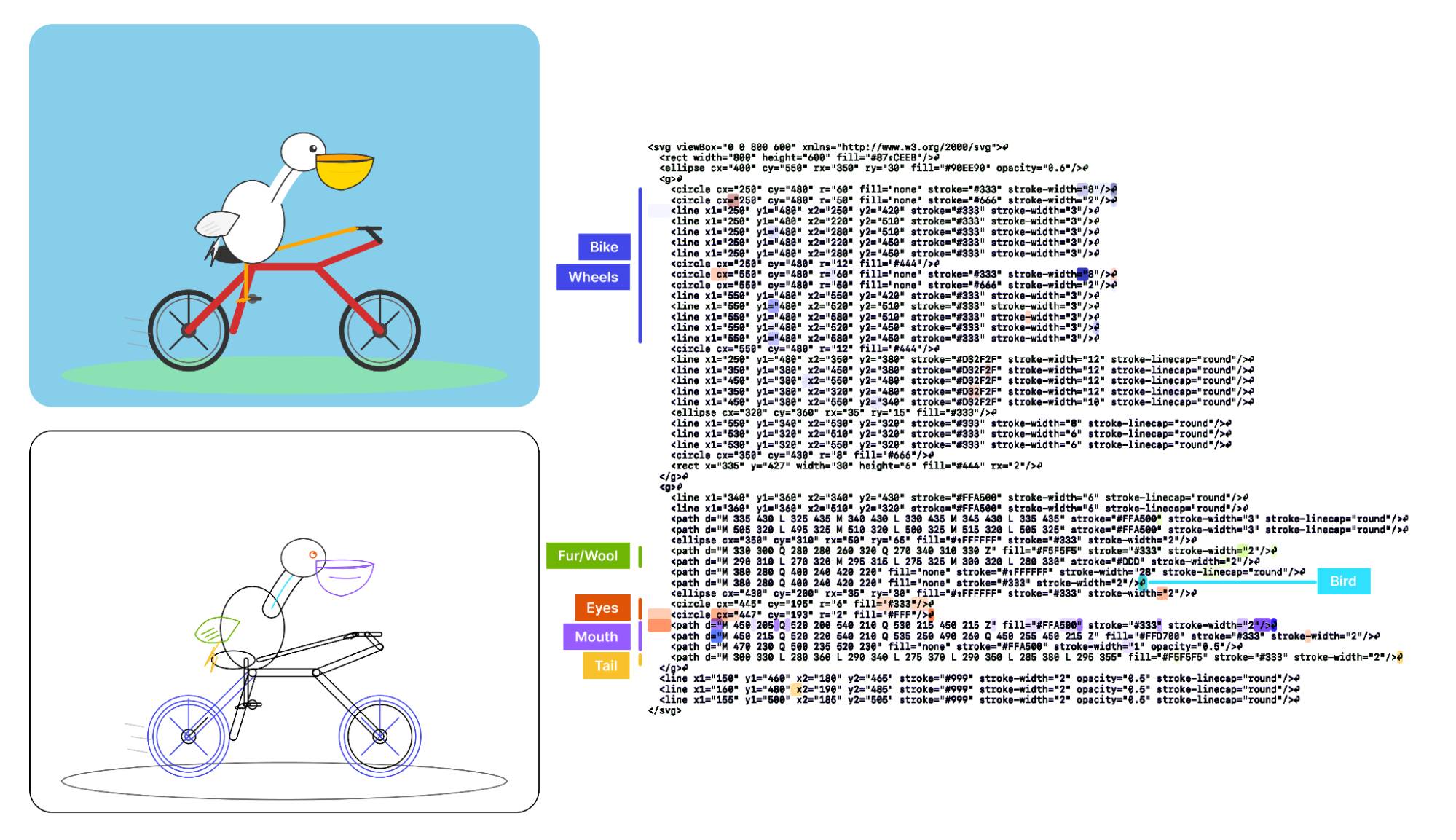
As a bonus, we also inspected features for an SVG of a pelican riding a bicycle, first popularized by Simon Willison as a way to test a model's artistic capabilities. We find features representing concepts including "bike", "wheels", "feet", "tail", "eyes", and "mouth" activating over the corresponding parts of the SVG code.
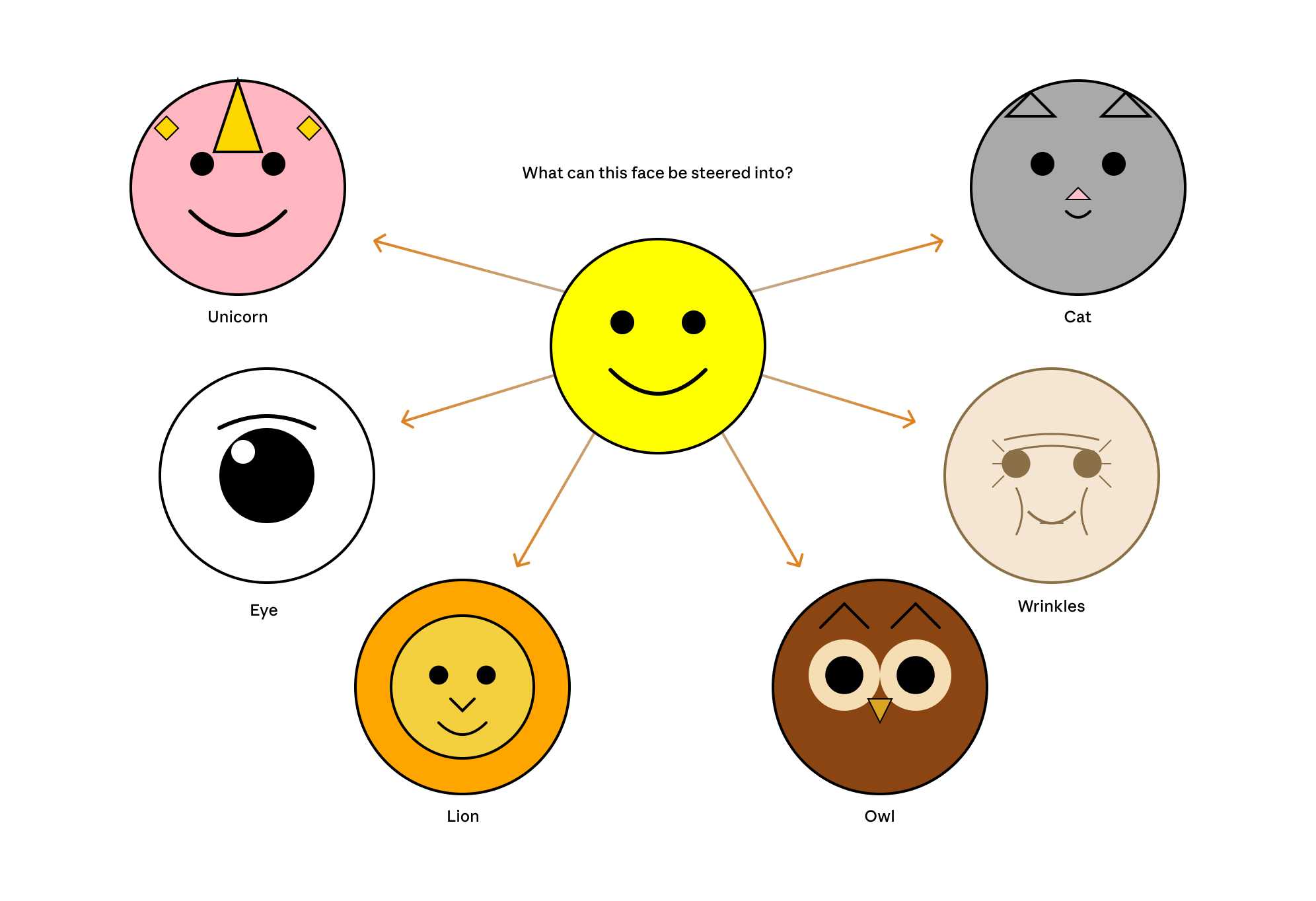
Now that they can identify model features associated with visual concepts in SVG images, can they us those for steering?
It turns out they can! Starting with a smiley SVG (provided as XML with no indication as to what it was drawing) and then applying a negative score to the "smile" feature produced a frown instead, and worked against ASCII art as well.
They could also boost features like unicorn, cat, owl, or lion and get new SVG smileys clearly attempting to depict those creatures.
I'd love to see how this behaves if you jack up the feature for the Golden Gate Bridge.
Tracing the thoughts of a large language model. In a follow-up to the research that brought us the delightful Golden Gate Claude last year, Anthropic have published two new papers about LLM interpretability:
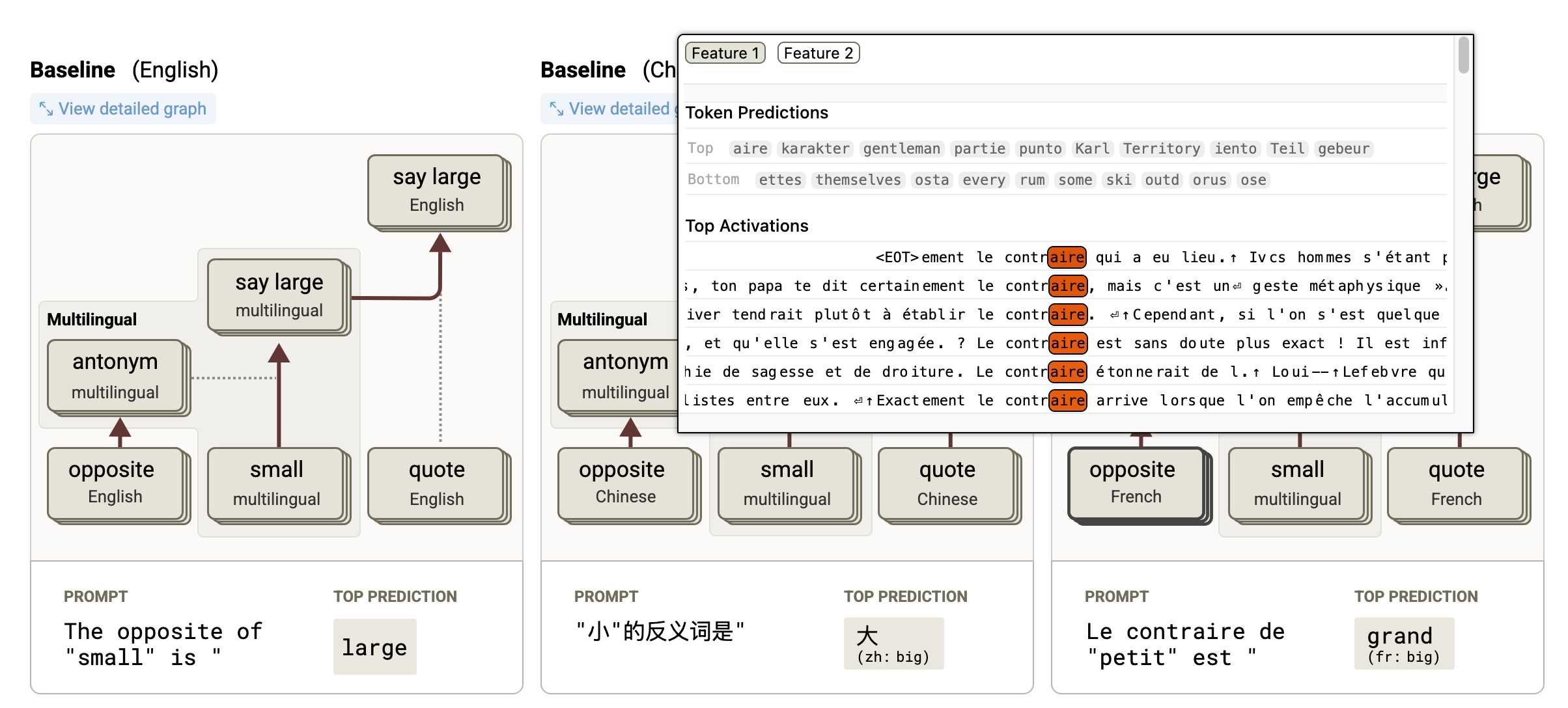
- Circuit Tracing: Revealing Computational Graphs in Language Models extends last year's interpretable features into attribution graphs, which can "trace the chain of intermediate steps that a model uses to transform a specific input prompt into an output response".
- On the Biology of a Large Language Model uses that methodology to investigate Claude 3.5 Haiku in a bunch of different ways. Multilingual Circuits for example shows that the same prompt in three different languages uses similar circuits for each one, hinting at an intriguing level of generalization.
To my own personal delight, neither of these papers are published as PDFs. They're both presented as glorious mobile friendly HTML pages with linkable sections and even some inline interactive diagrams. More of this please!
2024
Extracting Concepts from GPT-4. A few weeks ago Anthropic announced they had extracted millions of understandable features from their Claude 3 Sonnet model.
Today OpenAI are announcing a similar result against GPT-4:
We used new scalable methods to decompose GPT-4’s internal representations into 16 million oft-interpretable patterns.
These features are "patterns of activity that we hope are human interpretable". The release includes code and a paper, Scaling and evaluating sparse autoencoders paper (PDF) which credits nine authors, two of whom - Ilya Sutskever and Jan Leike - are high profile figures that left OpenAI within the past month.
The most fun part of this release is the interactive tool for exploring features. This highlights some interesting features on the homepage, or you can hit the "I'm feeling lucky" button to bounce to a random feature. The most interesting I've found so far is feature 5140 which seems to combine God's approval, telling your doctor about your prescriptions and information passed to the Admiralty.
This note shown on the explorer is interesting:
Only 65536 features available. Activations shown on The Pile (uncopyrighted) instead of our internal training dataset.
Here's the full Pile Uncopyrighted, which I hadn't seen before. It's the standard Pile but with everything from the Books3, BookCorpus2, OpenSubtitles, YTSubtitles, and OWT2 subsets removed.
Golden Gate Claude. This is absurdly fun and weird. Anthropic's recent LLM interpretability research gave them the ability to locate features within the opaque blob of their Sonnet model and boost the weight of those features during inference.
For a limited time only they're serving a "Golden Gate Claude" model which has the feature for the Golden Gate Bridge boosted. No matter what question you ask it the Golden Gate Bridge is likely to be involved in the answer in some way. Click the little bridge icon in the Claude UI to give it a go.
I asked for names for a pet pelican and the first one it offered was this:
Golden Gate - This iconic bridge name would be a fitting moniker for the pelican with its striking orange color and beautiful suspension cables.
And from a recipe for chocolate covered pretzels:
Gently wipe any fog away and pour the warm chocolate mixture over the bridge/brick combination. Allow to air dry, and the bridge will remain accessible for pedestrians to walk along it.
UPDATE: I think the experimental model is no longer available, approximately 24 hours after release. We'll miss you, Golden Gate Claude.
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (via) Big advances in the field of LLM interpretability from Anthropic, who managed to extract millions of understandable features from their production Claude 3 Sonnet model (the mid-point between the inexpensive Haiku and the GPT-4-class Opus).
Some delightful snippets in here such as this one:
We also find a variety of features related to sycophancy, such as an empathy / “yeah, me too” feature 34M/19922975, a sycophantic praise feature 1M/847723, and a sarcastic praise feature 34M/19415708.
ColBERT query-passage scoring interpretability (via) Neat interactive visualization tool for understanding what the ColBERT embedding model does—this works by loading around 50MB of model files directly into your browser and running them with WebAssembly.
2023
Decomposing Language Models Into Understandable Components. Anthropic appear to have made a major breakthrough with respect to the interpretability of Large Language Models:
“[...] we outline evidence that there are better units of analysis than individual neurons, and we have built machinery that lets us find these units in small transformer models. These units, called features, correspond to patterns (linear combinations) of neuron activations. This provides a path to breaking down complex neural networks into parts we can understand”