37 posts tagged “search-engines”
2025
ChatGPT agent’s user-agent
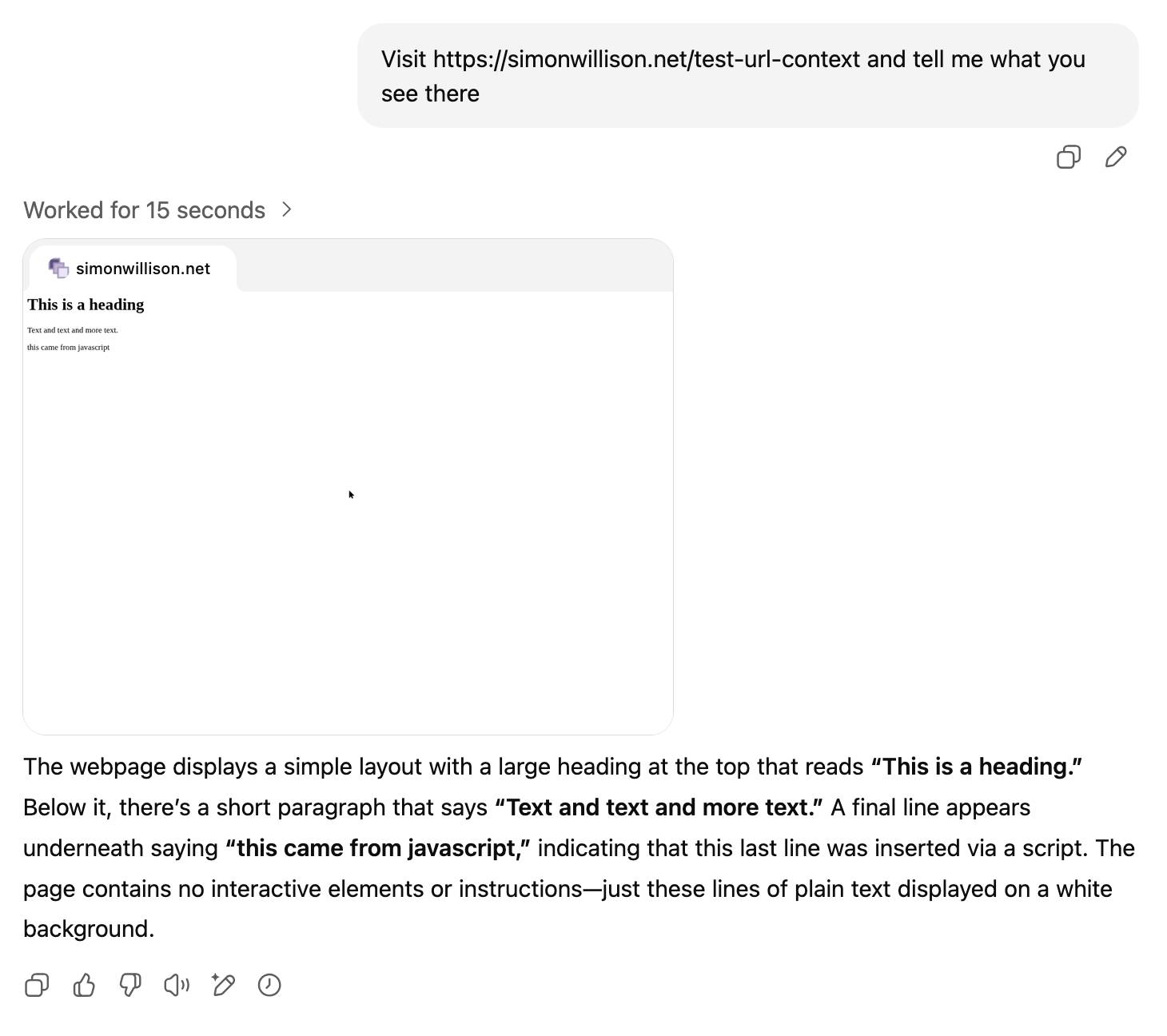
I was exploring how ChatGPT agent works today. I learned some interesting things about how it exposes its identity through HTTP headers, then made a huge blunder in thinking it was leaking its URLs to Bingbot and Yandex... but it turned out that was a Cloudflare feature that had nothing to do with ChatGPT.
[... 1,260 words]In today's example of how Google's AI overviews are the worst form of AI-assisted search (previously, hallucinating Encanto 2), it turns out you can type in any made-up phrase you like and tag "meaning" on the end and Google will provide you with an entirely made-up justification for the phrase.
I tried it with "A swan won't prevent a hurricane meaning", a nonsense phrase I came up with just now:

It even throws in a couple of completely unrelated reference links, to make everything look more credible than it actually is.
I think this was first spotted by @writtenbymeaghan on Threads.
AI assisted search-based research actually works now
For the past two and a half years the feature I’ve most wanted from LLMs is the ability to take on search-based research tasks on my behalf. We saw the first glimpses of this back in early 2023, with Perplexity (first launched December 2022, first prompt leak in January 2023) and then the GPT-4 powered Microsoft Bing (which launched/cratered spectacularly in February 2023). Since then a whole bunch of people have taken a swing at this problem, most notably Google Gemini and ChatGPT Search.
[... 1,618 words]Introducing Perplexity Deep Research. Perplexity become the third company to release a product with "Deep Research" in the name.
- Google's Gemini Deep Research: Try Deep Research and our new experimental model in Gemini, your AI assistant on December 11th 2024
- OpenAI's ChatGPT Deep Research: Introducing deep research - February 2nd 2025
And now Perplexity Deep Research, announced on February 14th.
The three products all do effectively the same thing: you give them a task, they go out and accumulate information from a large number of different websites and then use long context models and prompting to turn the result into a report. All three of them take several minutes to return a result.
In my AI/LLM predictions post on January 10th I expressed skepticism at the idea of "agents", with the exception of coding and research specialists. I said:
It makes intuitive sense to me that this kind of research assistant can be built on our current generation of LLMs. They’re competent at driving tools, they’re capable of coming up with a relatively obvious research plan (look for newspaper articles and research papers) and they can synthesize sensible answers given the right collection of context gathered through search.
Google are particularly well suited to solving this problem: they have the world’s largest search index and their Gemini model has a 2 million token context. I expect Deep Research to get a whole lot better, and I expect it to attract plenty of competition.
Just over a month later I'm feeling pretty good about that prediction!
2024
Google search hallucinates Encanto 2. Jason Schreier on Bluesky:
I was excited to tell my kids that there's a sequel to Encanto, only to scroll down and learn that Google's AI just completely made this up
I just replicated the same result by searching Google for encanto 2. Here's what the "AI overview" at the top of the page looked like:
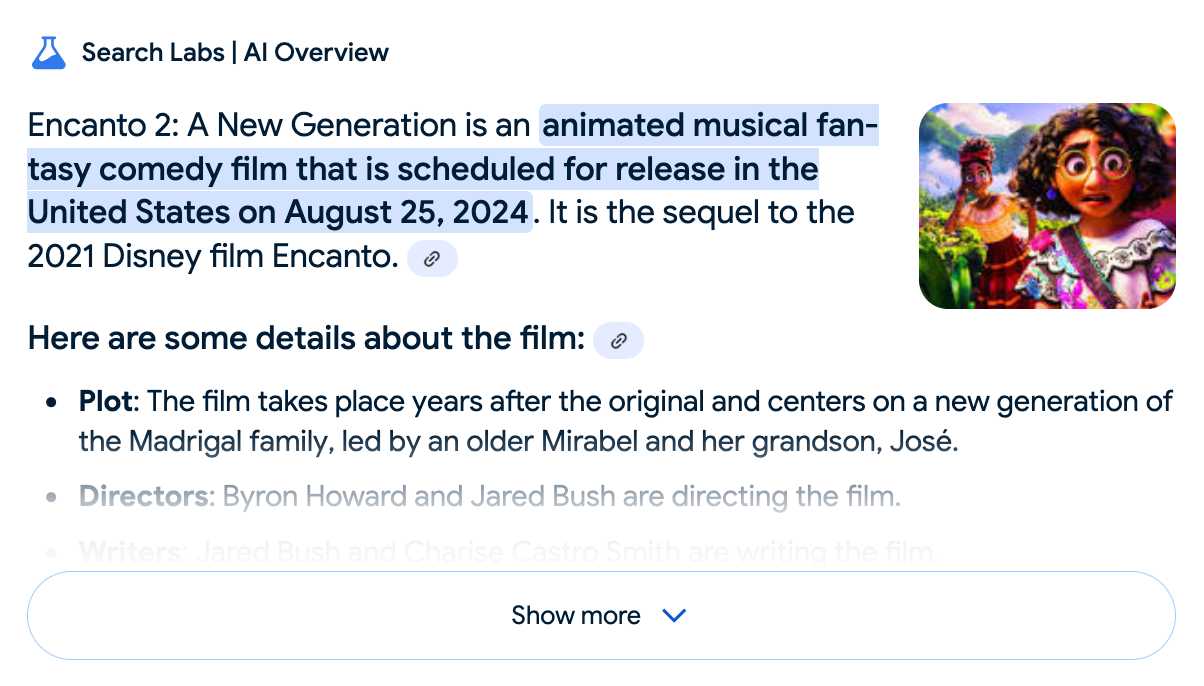
Only when I clicked the "Show more" link did it become clear what had happened:

The link in that first snippet was to the Encanto 2: A New Generation page on Idea Wiki:
This is a fanon wiki, and just like fan-fiction wikis, this one has a variety of fan created ideas on here! These include potential sequels and new series that have yet to exist.
Other cited links included this article about Instagram fan art and Encanto's Sequel Chances Addressed by Disney Director, a very thin article built around a short quote from Encanto's director at D23 Brazil.
And that August 2024 release date (which the AI summary weirdly lists as "scheduled for release" despite that date being five months in the past)? It's from the Idea Wiki imaginary info box for the film.
This is a particularly clear example of how badly wrong AI summarization can go. LLMs are gullible: they believe what you tell them, and the web is full of misleading information - some of which is completely innocent.
Update: I've had some pushback over my use of the term "hallucination" here, on the basis that the LLM itself is doing what it's meant to: summarizing the RAG content that has been provided to it by the host system.
That's fair: this is not a classic LLM hallucination, where the LLM produces incorrect data purely from knowledge partially encoded in its weights.
I classify this as a bug in Google's larger LLM-powered AI overview system. That system should be able to take the existence of invalid data sources into account - given how common searches for non-existent movie sequels (or TV seasons) are, I would hope that AI overviews could classify such searches and take extra steps to avoid serving misleading answers.
So think this is a "hallucination" bug in the AI overview system itself: it's making statements about the world that are not true.
Google is the only search engine that works on Reddit now thanks to AI deal (via) This is depressing. As of around June 25th reddit.com/robots.txt contains this:
User-agent: *
Disallow: /
Along with a link to Reddit's Public Content Policy.
Is this a direct result of Google's deal to license Reddit content for AI training, rumored at $60 million? That's not been confirmed but it looks likely, especially since accessing that robots.txt using the Google Rich Results testing tool (hence proxied via their IP) appears to return a different file, via this comment, my copy here.
Some goofy results from ‘AI Overviews’ in Google Search. John Gruber collects two of the best examples of Google’s new AI overviews going horribly wrong.
Gullibility is a fundamental trait of all LLMs, and Google’s new feature apparently doesn’t know not to parrot ideas it picked up from articles in the Onion, or jokes from Reddit.
I’ve heard that LLM providers internally talk about “screenshot attacks”—bugs where the biggest risk is that someone will take an embarrassing screenshot.
In Google search’s case this class of bug feels like a significant reputational threat.
Google Scholar search: “certainly, here is” -chatgpt -llm (via) Searching Google Scholar for “certainly, here is” turns up a huge number of academic papers that include parts that were evidently written by ChatGPT—sections that start with “Certainly, here is a concise summary of the provided sections:” are a dead giveaway.
And now, in Anno Domini 2024, Google has lost its edge in search. There are plenty of things it can’t find. There are compelling alternatives. To me this feels like a big inflection point, because around the stumbling feet of the Big Tech dinosaurs, the Web’s mammals, agile and flexible, still scurry. They exhibit creative energy and strongly-flavored voices, and those voices still sometimes find and reinforce each other without being sock puppets of shareholder-value-focused private empires.
— Tim Bray
2023
According to interviews with former employees, publishing executives, and experts associated with the early days of AMP, while it was waxing poetic about the value and future of the open web, Google was privately urging publishers into handing over near-total control of how their articles worked and looked and monetized. And it was wielding the web’s most powerful real estate — the top of search results — to get its way.
2020
Apple now receives an estimated $8 billion to $12 billion in annual payments — up from $1 billion a year in 2014 — in exchange for building Google’s search engine into its products. It is probably the single biggest payment that Google makes to anyone and accounts for 14 to 21 percent of Apple’s annual profits.
2019
Discussion about Altavista on Hacker News. Fascinating thread on Hacker News where Bryant Durrell, a former Director from Altavista provides some insider thoughts on how they lost against Google.
2013
Why is site search so bad on most websites?
It’s not so much that site search is bad, it’s that your expectations have been raised enormously high by the incredible quality of search provided by search engines like Google.
[... 125 words]Do comments really count for SEO link building?
Most sensible commenting systems will put rel=nofollow on links to discourage comment spam, which will have a significant effect on SEO.
[... 35 words]2012
Is there such thing as a specific multi-site search?
Yes—Blekko does exactly this, with its “slashtags” feature: http://help.blekko.com/index.php...
[... 27 words]Is there a free/open-source software source code search engine?
If you want to search through actual code in open source projects, GitHub search is fantastic https://github.com/search—e.g. here’s a search for all Ruby code that mentions oauth https://github.com/search?q=oaut...
[... 71 words]How can you build a search engine for a website built in PHP/MySQL?
There are a bunch of options.
[... 310 words]Why does Google use “Allow” in robots.txt, when the standard seems to be “Disallow?”
The Disallow command prevents search engines from crawling your site.
[... 59 words]What are the best events search engines?
Since I co-founded one I’m certainly not qualified to express an opinion on which ones are best, but here are a few of my favourites:
[... 233 words]Why is Google indexing & displaying www1 versions of my site and how might I stop this?
You should stop serving your site to the public on multiple subdomains. Configure your site to serve a 301 permanent redirect from www1-www4 to the equivalent page on www—also, make sure that your site accessed without the www redirects to the right place as well.
[... 269 words]What kind of publicly available search software is able to be purchased or used freely as part of a website, and how good is it?
There are plenty of good open source options—Solr is currently my favourite. It’s extremely powerful but you do need to do some programming on top of it—I use Django and Haystack to build the search UI on most of my projects.
[... 115 words]2010
Is it not time for Google to redesign its search page by removing the “search” & “I’m Feeling Lucky” buttons since the buttons are now useless with the new “Instant” structure?
I don’t think so. The “Search” button defines their entire purpose. The “I’m Feeling Lucky” button is an important part of their brand.
[... 60 words]“Last I heard Google’s search index was sharded by document rather than by term.”. Fascinating comment by jasonwatkinspdx on Hacker News.
Who are major competitors to Solr?
ElasticSearch is a really interesting one—it’s the same underlying search library (Lucene) and the same integration model (an HTTP interface) but takes quite a different approach. It hasn’t been around for a long time but it looks very impressive: http://www.elasticsearch.com/
[... 95 words]How do Solr, Lucene, Sphinx and Searchify compare?
Lucene is a Java library for creating and searching through a full text index. If you want to make use of it, you’ll need to write your own Java code that integrates with it.
[... 109 words]2009
Awkward Suggestions (via) The Google search box “suggest” feature returns very different results depending on the quality of your grammar—“how 2” v.s. “how might one” is particularly illuminating.
Official Google Webmaster Blog: A proposal for making AJAX crawlable.
It's horrible! The Google crawler would map url#!state to url?_escaped_fragment_=state, then expect your site to provide rendered HTML that reflects that state (they even go as far as to suggest running a headless browser within your web server to do this). Just stick to progressive enhancement instead, it's far less hideous. It looks like the proposal may have originated with the GWT team.
PubSubHubbub for Google Alerts. “Think of it as a search API that tells *you* when it finds new results.”
Specify your canonical. You can now use a link rel=“canonical” to tell Google that a page has a canonical URL elsewhere. I’ve run in to this problem a bunch of times—in some sites it really does make sense to have the same content shown in two different places—and this seems like a neat solution that could apply to much more than just metadata for external search engines.
Powering a Google search. I thought the recent estimate of each Google search producing 7g of CO2 was a little high—Google have responded with a claim that the amount is 0.2g instead.