25 posts tagged “stable-diffusion”
2026
FLUX.2-klein-4B Pure C Implementation (via) On 15th January Black Forest Labs, a lab formed by the creators of the original Stable Diffusion, released black-forest-labs/FLUX.2-klein-4B - an Apache 2.0 licensed 4 billion parameter version of their FLUX.2 family.
Salvatore Sanfilippo (antirez) decided to build a pure C and dependency-free implementation to run the model, with assistance from Claude Code and Claude Opus 4.5.
Salvatore shared this note on Hacker News:
Something that may be interesting for the reader of this thread: this project was possible only once I started to tell Opus that it needed to take a file with all the implementation notes, and also accumulating all the things we discovered during the development process. And also, the file had clear instructions to be taken updated, and to be processed ASAP after context compaction. This kinda enabled Opus to do such a big coding task in a reasonable amount of time without loosing track. Check the file IMPLEMENTATION_NOTES.md in the GitHub repo for more info.
Here's that IMPLEMENTATION_NOTES.md file.
2025
Qwen-Image: Crafting with Native Text Rendering (via) Not content with releasing six excellent open weights LLMs in July, Qwen are kicking off August with their first ever image generation model.
Qwen-Image is a 20 billion parameter MMDiT (Multimodal Diffusion Transformer, originally proposed for Stable Diffusion 3) model under an Apache 2.0 license. The Hugging Face repo is 53.97GB.
Qwen released a detailed technical report (PDF) to accompany the model. The model builds on their Qwen-2.5-VL vision LLM, and they also made extensive use of that model to help create some of their their training data:
In our data annotation pipeline, we utilize a capable image captioner (e.g., Qwen2.5-VL) to generate not only comprehensive image descriptions, but also structured metadata that captures essential image properties and quality attributes.
Instead of treating captioning and metadata extraction as independent tasks, we designed an annotation framework in which the captioner concurrently describes visual content and generates detailed information in a structured format, such as JSON. Critical details such as object attributes, spatial relationships, environmental context, and verbatim transcriptions of visible text are captured in the caption, while key image properties like type, style, presence of watermarks, and abnormal elements (e.g., QR codes or facial mosaics) are reported in a structured format.
They put a lot of effort into the model's ability to render text in a useful way. 5% of the training data (described as "billions of image-text pairs") was data "synthesized through controlled text rendering techniques", ranging from simple text through text on an image background up to much more complex layout examples:
To improve the model’s capacity to follow complex, structured prompts involving layout-sensitive content, we propose a synthesis strategy based on programmatic editing of pre-defined templates, such as PowerPoint slides or User Interface Mockups. A comprehensive rule-based system is designed to automate the substitution of placeholder text while maintaining the integrity of layout structure, alignment, and formatting.
I tried the model out using the ModelScope demo - I signed in with GitHub and verified my account via a text message to a phone number. Here's what I got for "A raccoon holding a sign that says "I love trash" that was written by that raccoon":

The raccoon has very neat handwriting!
Update: A version of the model exists that can edit existing images but it's not yet been released:
Currently, we have only open-sourced the text-to-image foundation model, but the editing model is also on our roadmap and planned for future release.
2024
Announcing FLUX1.1 [pro] and the BFL API (via) FLUX is the image generation model family from Black Forest Labs, a startup founded by members of the team that previously created Stable Diffusion.
Released today, FLUX1.1 [pro] continues the general trend of AI models getting both better and more efficient:
FLUX1.1 [pro] provides six times faster generation than its predecessor FLUX.1 [pro] while also improving image quality, prompt adherence, and diversity.
Black Forest Labs appear to have settled on a potentially workable business model: their smallest, fastest model FLUX.1 [schnell] is Apache 2 licensed. The next step up is FLUX.1 [dev] which is open weights for non-commercial use only. The [pro] models are closed weights, made available exclusively through their API or partnerships with other API providers.
I tried the new 1.1 model out using black-forest-labs/flux-1.1-pro on Replicate just now. Here's my prompt:
Photograph of a Faberge egg representing the California coast. It should be decorated with ornate pelicans and sea lions and a humpback whale.

The FLUX models have a reputation for being really good at following complex prompts. In this case I wanted the sea lions to appear in the egg design rather than looking at the egg from the beach, but I imagine I could get better results if I continued to iterate on my prompt.
The FLUX models are also better at applying text than any other image models I've tried myself.
2023
I’ve resigned from my role leading the Audio team at Stability AI, because I don’t agree with the company’s opinion that training generative AI models on copyrighted works is ‘fair use’.
[...] I disagree because one of the factors affecting whether the act of copying is fair use, according to Congress, is “the effect of the use upon the potential market for or value of the copyrighted work”. Today’s generative AI models can clearly be used to create works that compete with the copyrighted works they are trained on. So I don’t see how using copyrighted works to train generative AI models of this nature can be considered fair use.
But setting aside the fair use argument for a moment — since ‘fair use’ wasn’t designed with generative AI in mind — training generative AI models in this way is, to me, wrong. Companies worth billions of dollars are, without permission, training generative AI models on creators’ works, which are then being used to create new content that in many cases can compete with the original works.
If you visit (often NSFW, beware!) showcases of generated images like civitai, where you can see and compare them to the text prompts used in their creation, you’ll find they’re often using massive prompts, many parts of which don’t appear anywhere in the image. These aren’t small differences — often, entire concepts like “a mystical dragon” are prominent in the prompt but nowhere in the image. These users are playing a gacha game, a picture-making slot machine. They’re writing a prompt with lots of interesting ideas and then pulling the arm of the slot machine until they win… something. A compelling image, but not really the image they were asking for.
IF by DeepFloyd Lab (via) New image generation AI model, financially backed by StabilityAI but based on the Google Imagen paper. Claims to be much better at following complex prompts, including being able to generate text! I tried the Colab notebook with “a photograph of raccoon in the woods holding a sign that says ’I will eat your trash’” and it didn’t quite get the text right, see via link for the result.
Stability AI Launches the First of its StableLM Suite of Language Models (via) 3B and 7B base models, with 15B and 30B are on the way. CC BY-SA-4.0. “StableLM is trained on a new experimental dataset built on The Pile, but three times larger with 1.5 trillion tokens of content. We will release details on the dataset in due course.”
How I Used Stable Diffusion and Dreambooth to Create A Painted Portrait of My Dog (via) I like posts like this that go into detail in terms of how much work it takes to deliberately get the kind of result you really want using generative AI tools. Jake Dahn trained a Dreambooth model from 40 photos of Queso—his photogenic Golden Retriever—using Replicate, then gathered the prompts from ten images he liked on Lexica and generated over 1,000 different candidate images, picked his favourite, used Draw Things img2img resizing to expand the image beyond the initial crop, then Automatic1111 inpainting to tweak the ears, then Real-ESRGAN 4x+ to upscale for the final print.
From Deep Learning Foundations to Stable Diffusion. Brand new free online video course from Jeremy Howard: 30 hours of content, covering everything you need to know to implement the Stable Diffusion image generation algorithm from scratch. I previewed parts of this course back in December and it was fascinating: this field is moving so fast that some of the lectures covered papers that had been released just a few days before.
Stable Diffusion copyright lawsuits could be a legal earthquake for AI. Timothy B. Lee provides a thorough discussion of the copyright lawsuits currently targeting Stable Diffusion and GitHub Copilot, including subtle points about how the interpretation of “fair use” might be applied to the new field of generative AI.
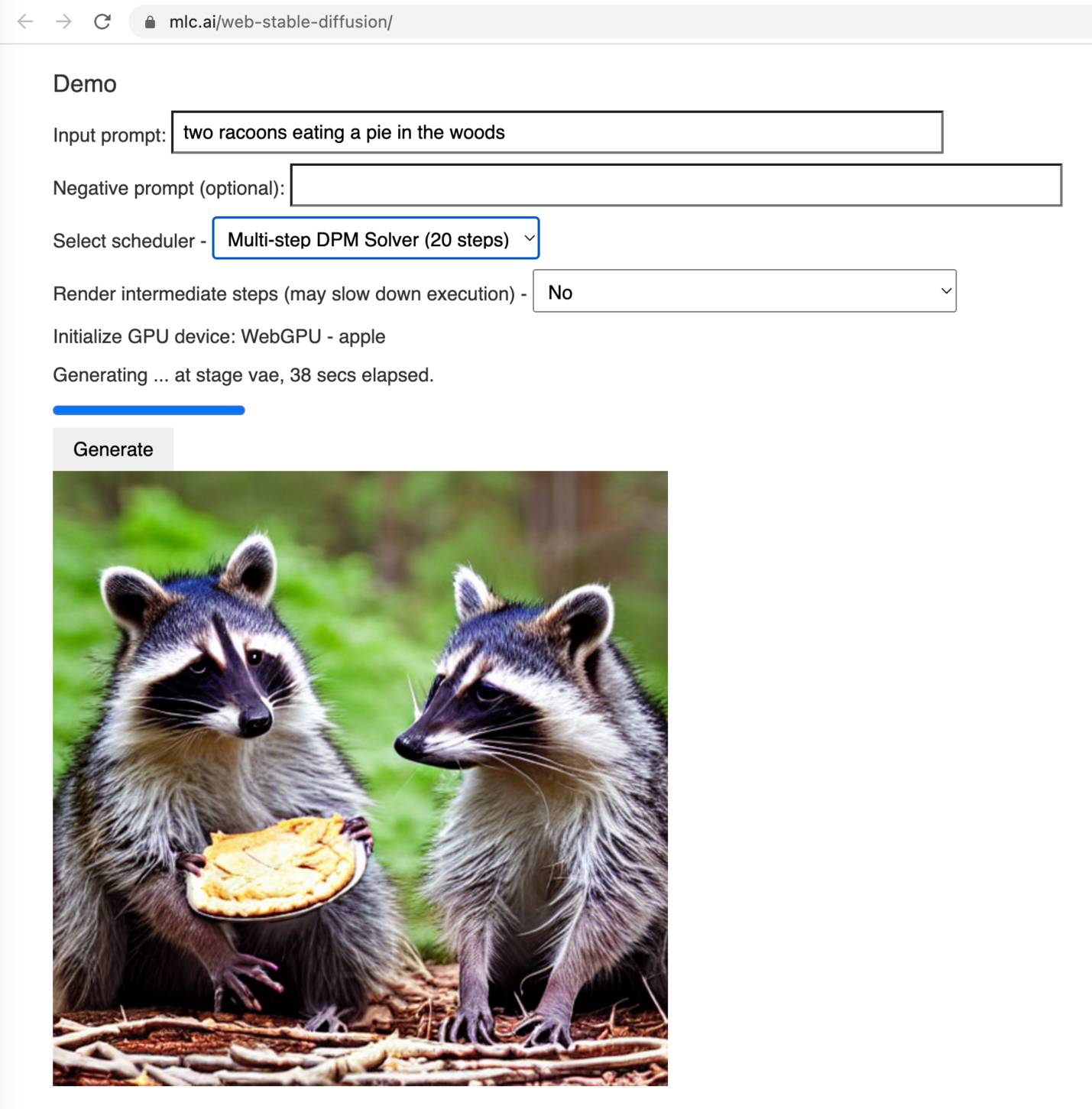
Web Stable Diffusion (via) I just ran the full Stable Diffusion image generation model entirely in my browser, and used it to generate an image of two raccoons eating pie in the woods. I had to use Google Chrome Canary since this depends on WebGPU which still isn't fully rolled out, but it worked perfectly.
ControlNet (via) A spectacular step forward in image generation—using “conditional control” to control models like Stable Diffusion. The README here is full of examples of what this enables. Extremely finely grained control of generated images based on a sketch, or in input image—including tricks like using Canny edge detection (an algorithm from 1986) to convert any image into an outline which can then be used as input to the model.
2022
A 4.2GiB file isn’t a heist of every single artwork on the Internet, and those who think it is are the ones undervaluing their own contributions and creativity. It’s an amazing summary of what we know about art, and everyone should be able to use it to learn, grow, and create.
Stable Diffusion 2.0 and the Importance of Negative Prompts for Good Results. Stable Diffusion 2.0 is out, and it’s a very different model from 1.4/1.5. It’s trained using a new text encoder (OpenCLIP, in place of OpenAI’s CLIP) which means a lot of the old tricks—notably using “Greg Rutkowski” to get high quality fantasy art—no longer work. What DOES work, incredibly well, is negative prompting—saying things like “cyberpunk forest by Salvador Dali” but negative on “trees, green”. Max Woolf explores negative prompting in depth in this article, including how to combine it with textual inversion.
The AI that creates any picture you want, explained. Vox made this explainer video about text-to-image generative AI models back in June, months before Stable Diffusion was released and shortly before the DALL-E preview started rolling out to a wider audience. It’s a really good video—in particular the animation that explains at a high level how diffusion models work, which starts about 5m30s in.
The Illustrated Stable Diffusion (via) Jay Alammar provides a detailed, clearly explained description of how the Stable Diffusion image generation model actually works under the hood..
I Resurrected “Ugly Sonic” with Stable Diffusion Textual Inversion (via) “I trained an Ugly Sonic object concept on 5 image crops from the movie trailer, with 6,000 steps [...] (on a T4 GPU, this took about 1.5 hours and cost about $0.21 on a GCP Spot instance)”
Of all the parameters in SD, the seed parameter is the most important anchor for keeping the image generation the same. In SD-space, there are only 4.3 billion possible seeds. You could consider each seed a different universe, numbered as the Marvel universe does (where the main timeline is #616, and #616 Dr Strange visits #838 and a dozen other universes). Universe #42 is the best explored, because someone decided to make it the default for text2img.py (probably a Hitchhiker’s Guide reference). But you could change the seed, and get a totally different result from what is effectively a different universe.
— swyx
The Changelog: Stable Diffusion breaks the internet. I’m on this week’s episode of The Changelog podcast, talking about Stable Diffusion, AI ethics and a little bit about prompt injection attacks too.
Exploring the training data behind Stable Diffusion
Two weeks ago, the Stable Diffusion image generation model was released to the public. I wrote about this last week, in Stable Diffusion is a really big deal—a post which has since become one of the top ten results for “stable diffusion” on Google and shown up in all sorts of different places online.
[... 2,897 words]Grokking Stable Diffusion (via) Jonathan Whitaker built this interactive Jupyter notebook that walks through how to use Stable Diffusion from Python step-by-step, and then dives deep into helping understand the different components of the implementation, including how text is encoded, how the diffusion loop works and more. This is by far the most useful tool I’ve seen yet for understanding how this model actually works. You can run Jonathan’s notebook directly on Google Colab, with a GPU.
Run Stable Diffusion on your M1 Mac’s GPU. Ben Firshman provides detailed instructions for getting Stable Diffusion running on an M1 Mac.
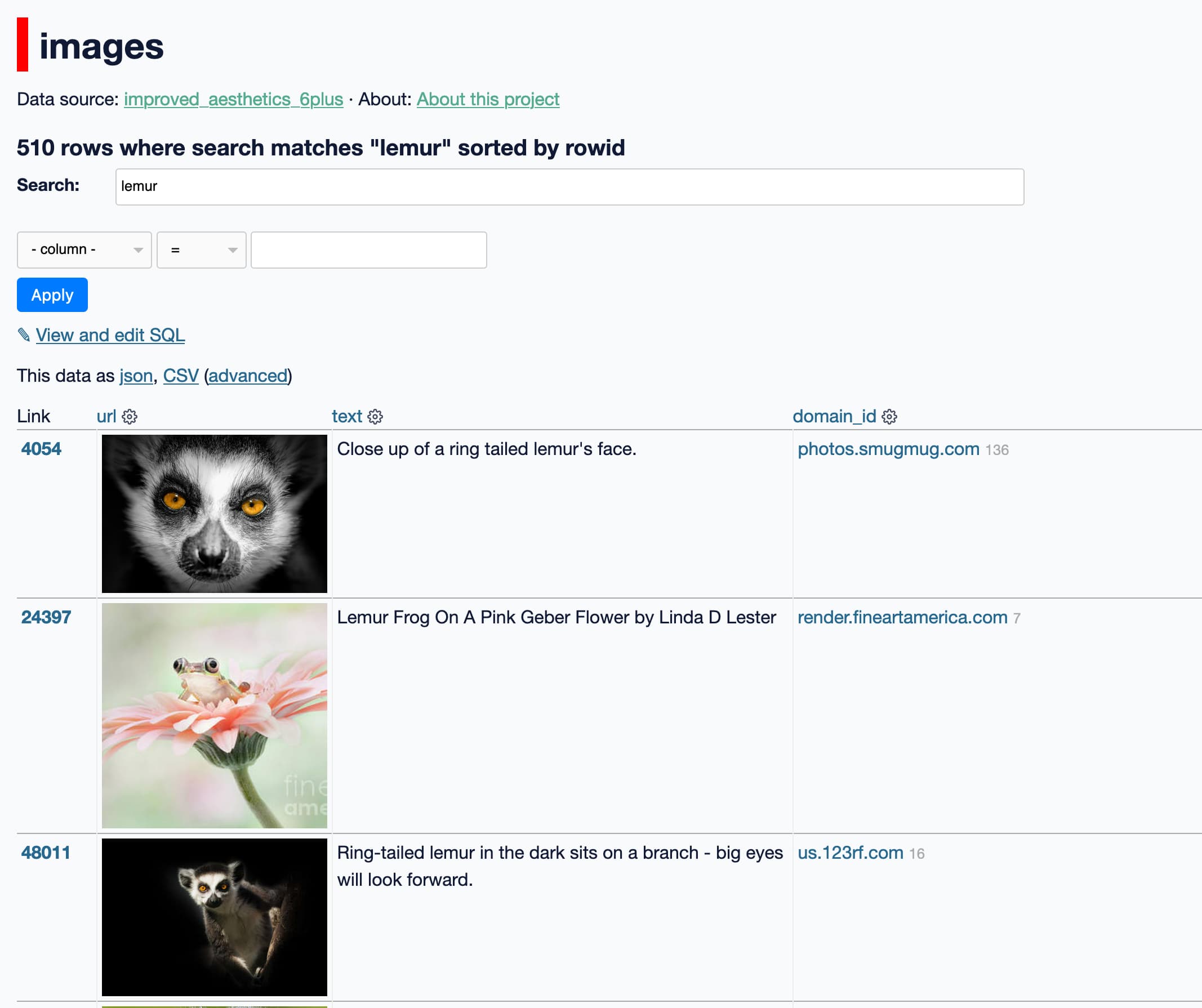
Exploring 12 Million of the 2.3 Billion Images Used to Train Stable Diffusion’s Image Generator. Andy Baio and I collaborated on an investigation into the training set used for Stable Diffusion. I built a Datasette instance with 12m image records sourced from the LAION-Aesthetics v2 6+ aesthetic score data used as part of the training process, and built a tool so people could run searches and explore the data. Andy did some extensive analysis of things like the domains scraped for the images and names of celebrities and artists represented in the data. His write-up here explains our project in detail and some of the patterns we’ve uncovered so far.
Stable Diffusion is a really big deal
If you haven’t been paying attention to what’s going on with Stable Diffusion, you really should be.
[... 1,443 words]Stable Diffusion Public Release (via) New AI just dropped. Stable Diffusion is similar to DALL-E, but completely open source and with a CC0 license applied to everything it generates. I have a Twitter thread (the via) link of comparisons I’ve made between its output and my previous DALL-E experiments. The announcement buries the lede somewhat: to try it out, visit beta.dreamstudio.ai—which you can use for free at the moment, but it’s unclear to me how billing is supposed to work.