11 posts tagged “transformers-js”
2025
Load Llama-3.2 WebGPU in your browser from a local folder (via) Inspired by a comment on Hacker News I decided to see if it was possible to modify the transformers.js-examples/tree/main/llama-3.2-webgpu Llama 3.2 chat demo (online here, I wrote about it last November) to add an option to open a local model file directly from a folder on disk, rather than waiting for it to download over the network.
I posed the problem to OpenAI's GPT-5-enabled Codex CLI like this:
git clone https://github.com/huggingface/transformers.js-examples
cd transformers.js-examples/llama-3.2-webgpu
codex
Then this prompt:
Modify this application such that it offers the user a file browse button for selecting their own local copy of the model file instead of loading it over the network. Provide a "download model" option too.
Codex churned away for several minutes, even running commands like curl -sL https://raw.githubusercontent.com/huggingface/transformers.js/main/src/models.js | sed -n '1,200p' to inspect the source code of the underlying Transformers.js library.
After four prompts total (shown here) it built something which worked!
To try it out you'll need your own local copy of the Llama 3.2 ONNX model. You can get that (a ~1.2GB) download) like so:
git lfs install
git clone https://huggingface.co/onnx-community/Llama-3.2-1B-Instruct-q4f16
Then visit my llama-3.2-webgpu page in Chrome or Firefox Nightly (since WebGPU is required), click "Browse folder", select that folder you just cloned, agree to the "Upload" confirmation (confusing since nothing is uploaded from your browser, the model file is opened locally on your machine) and click "Load local model".
Here's an animated demo (recorded in real-time, I didn't speed this up):
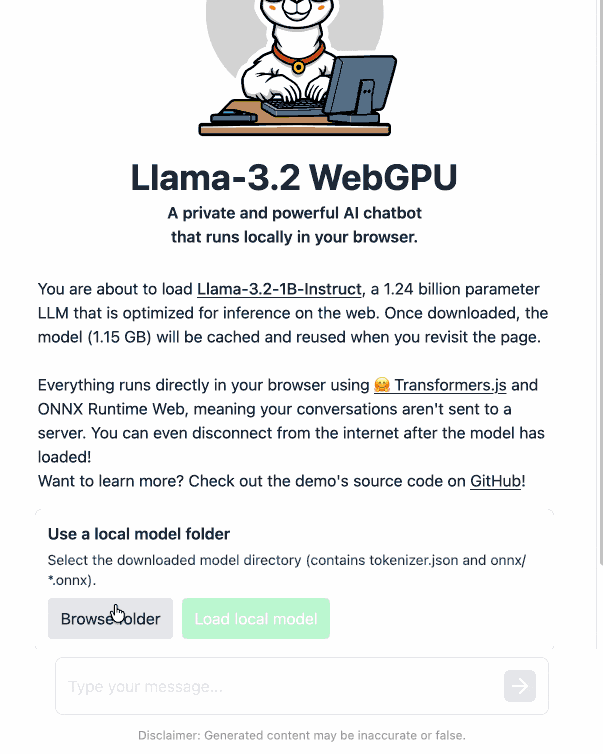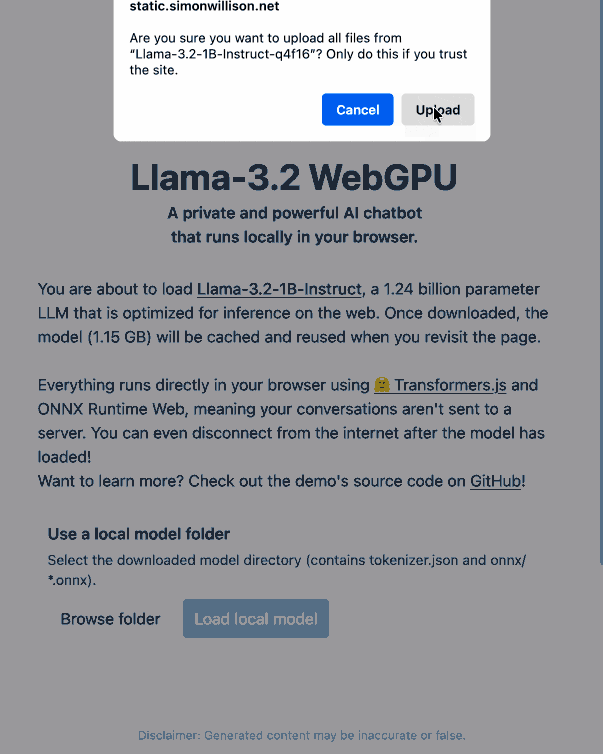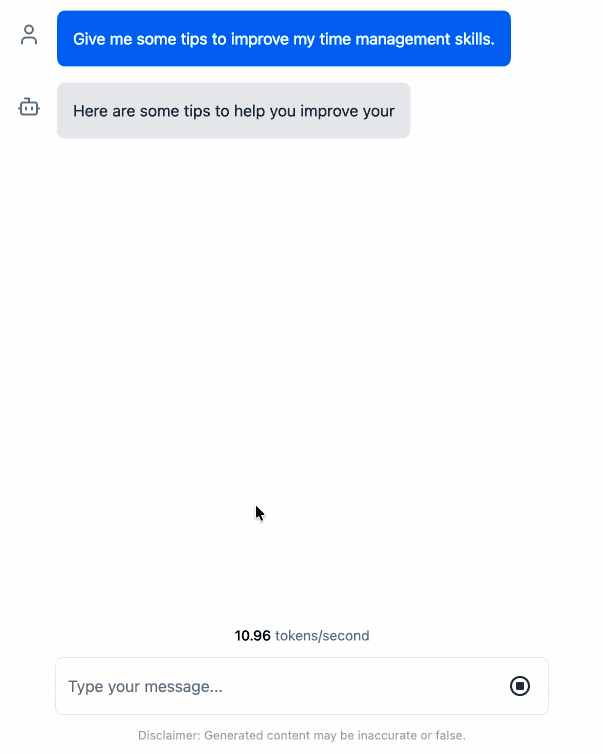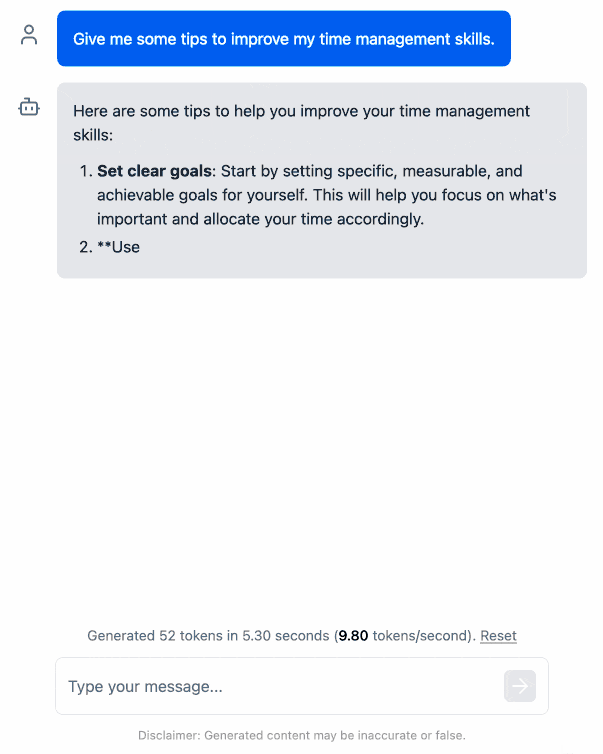
I pushed a branch with those changes here. The next step would be to modify this to support other models in addition to the Llama 3.2 demo, but I'm pleased to have got to this proof of concept with so little work beyond throwing some prompts at Codex to see if it could figure it out.
According to the Codex /status command this used 169,818 input tokens, 17,112 output tokens and 1,176,320 cached input tokens. At current GPT-5 token pricing ($1.25/million input, $0.125/million cached input, $10/million output) that would cost 53.942 cents, but Codex CLI hooks into my existing $20/month ChatGPT Plus plan so this was bundled into that.
Introducing EmbeddingGemma. Brand new open weights (under the slightly janky Gemma license) 308M parameter embedding model from Google:
Based on the Gemma 3 architecture, EmbeddingGemma is trained on 100+ languages and is small enough to run on less than 200MB of RAM with quantization.
It's available via sentence-transformers, llama.cpp, MLX, Ollama, LMStudio and more.
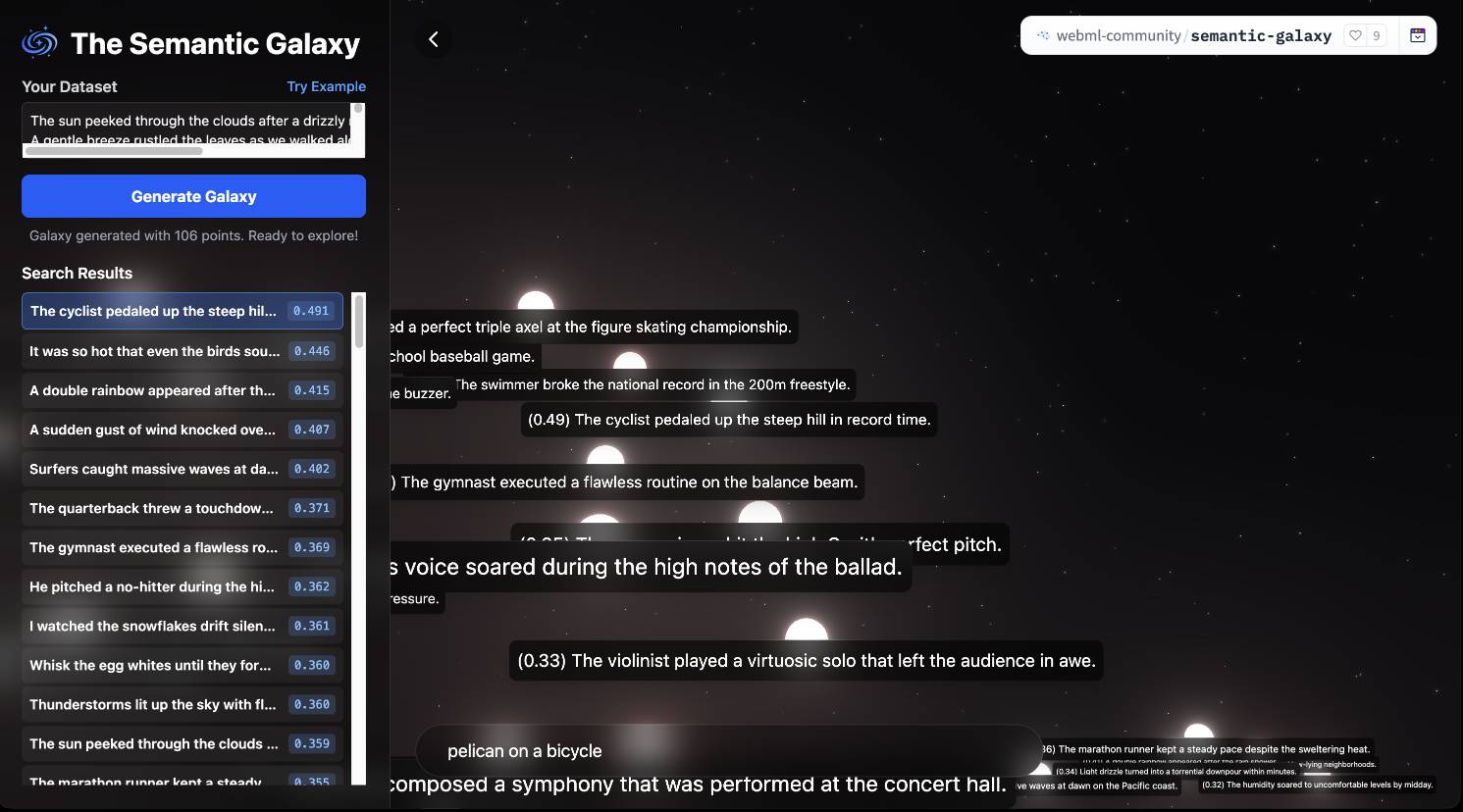
As usual for these smaller models there's a Transformers.js demo (via) that runs directly in the browser (in Chrome variants) - Semantic Galaxy loads a ~400MB model and then lets you run embeddings against hundreds of text sentences, map them in a 2D space and run similarity searches to zoom to points within that space.
DeepSeek Janus-Pro. Another impressive model release from DeepSeek. Janus is their series of "unified multimodal understanding and generation models" - these are models that can both accept images as input and generate images for output.
Janus-Pro is the new 7B model, which DeepSeek describe as "an advanced version of Janus, improving both multimodal understanding and visual generation significantly". It's released under the not fully open source DeepSeek license.
Janus-Pro is accompanied by this paper, which includes this note about the training:
Our Janus is trained and evaluated using HAI-LLM, which is a lightweight and efficient distributed training framework built on top of PyTorch. The whole training process took about 7/14 days on a cluster of 16/32 nodes for 1.5B/7B model, each equipped with 8 Nvidia A100 (40GB) GPUs.
It includes a lot of high benchmark scores, but closes with some notes on the model's current limitations:
In terms of multimodal understanding, the input resolution is limited to 384 × 384, which affects its performance in fine-grained tasks such as OCR. For text-to-image generation, the low resolution, combined with reconstruction losses introduced by the vision tokenizer, results in images that, while rich in semantic content, still lack fine details. For example, small facial regions occupying limited image space may appear under-detailed. Increasing the image resolution could mitigate these issues.
The easiest way to try this one out is using the Hugging Face Spaces demo. I tried the following prompt for the image generation capability:
A photo of a raccoon holding a handwritten sign that says "I love trash"
And got back this image:

It's now also been ported to Transformers.js, which means you can run the 1B model directly in a WebGPU browser such as Chrome here at webml-community/janus-pro-webgpu (loads about 2.24 GB of model files).
2024
llama-3.2-webgpu (via) Llama 3.2 1B is a really interesting models, given its 128,000 token input and its tiny size (barely more than a GB).
This page loads a 1.24GB q4f16 ONNX build of the Llama-3.2-1B-Instruct model and runs it with a React-powered chat interface directly in the browser, using Transformers.js and WebGPU. Source code for the demo is here.
It worked for me just now in Chrome; in Firefox and Safari I got a “WebGPU is not supported by this browser” error message.
Experimenting with local alt text generation in Firefox Nightly (via) The PDF editor in Firefox (confession: I did not know Firefox ships with a PDF editor) is getting an experimental feature that can help suggest alt text for images for the human editor to then adapt and improve on.
This is a great application of AI, made all the more interesting here because Firefox will run a local model on-device for this, using a custom trained model they describe as "our 182M parameters model using a Distilled version of GPT-2 alongside a Vision Transformer (ViT) image encoder".
The model uses WebAssembly with ONNX running in Transfomers.js, and will be downloaded the first time the feature is put to use.
The Tokenizer Playground (via) I built a tool like this a while ago, but this one is much better: it provides an interface for experimenting with tokenizers from a wide range of model architectures, including Llama, Claude, Mistral and Grok-1—all running in the browser using Transformers.js.
Adaptive Retrieval with Matryoshka Embeddings (via) Nomic Embed v1 only came out two weeks ago, but the same team just released Nomic Embed v1.5 trained using a new technique called Matryoshka Representation.
This means that unlike v1 the v1.5 embeddings are resizable - instead of a fixed 768 dimension embedding vector you can trade size for quality and drop that size all the way down to 64, while still maintaining strong semantically relevant results.
Joshua Lochner build this interactive demo on top of Transformers.js which illustrates quite how well this works: it lets you embed a query, embed a series of potentially matching text sentences and then adjust the number of dimensions and see what impact it has on the results.
2023
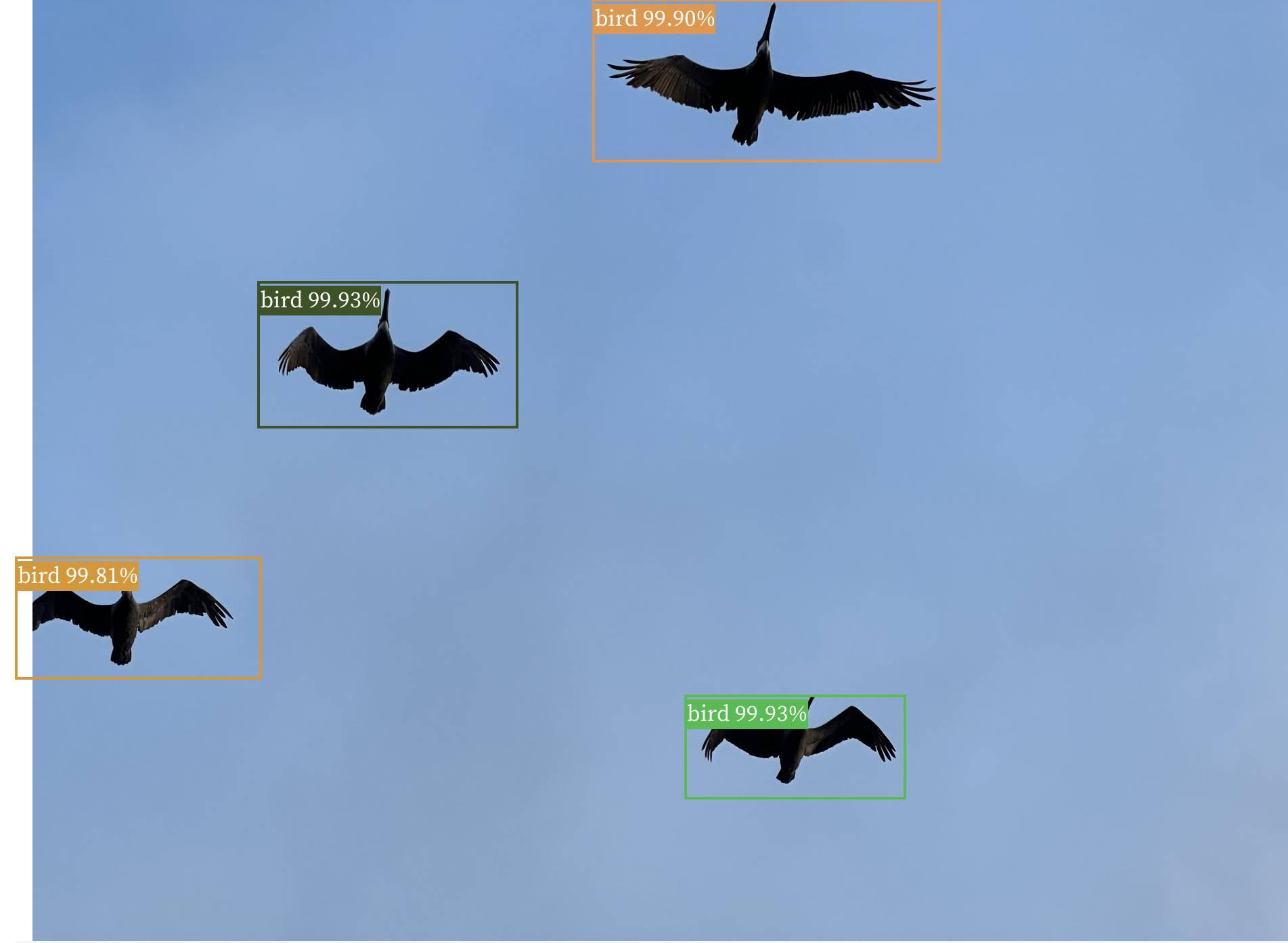
Observable notebook: Detect objects in images (via) I built an Observable notebook that uses Transformers.js and the Xenova/detra-resnet-50 model to detect objects in images, entirely running within your browser. You can select an image using a file picker and it will show you that image with bounding boxes and labels drawn around items within it. I have a demo image showing some pelicans flying ahead, but it works with any image you give it - all without uploading that image to a server.
Perplexity: interactive LLM visualization (via) I linked to a video of Linus Lee's GPT visualization tool the other day. Today he's released a new version of it that people can actually play with: it runs entirely in a browser, powered by a 120MB version of the GPT-2 ONNX model loaded using the brilliant Transformers.js JavaScript library.
Could you train a ChatGPT-beating model for $85,000 and run it in a browser?
I think it’s now possible to train a large language model with similar functionality to GPT-3 for $85,000. And I think we might soon be able to run the resulting model entirely in the browser, and give it capabilities that leapfrog it ahead of ChatGPT.
[... 1,751 words]Transformers.js. Hugging Face Transformers is a library of Transformer machine learning models plus a Python package for loading and running them. Transformers.js provides a JavaScript alternative interface which runs in your browser, thanks to a set of precompiled WebAssembly binaries for a selection of models. This interactive demo is incredible: in particular, try running the Image classification with google/vit-base-patch16-224 (91MB) model against any photo to get back labels representing that photo. Dropping one of these models onto a page is as easy as linking to a hosted CDN script and running a few lines of JavaScript.