9 posts tagged “webgpu”
2025
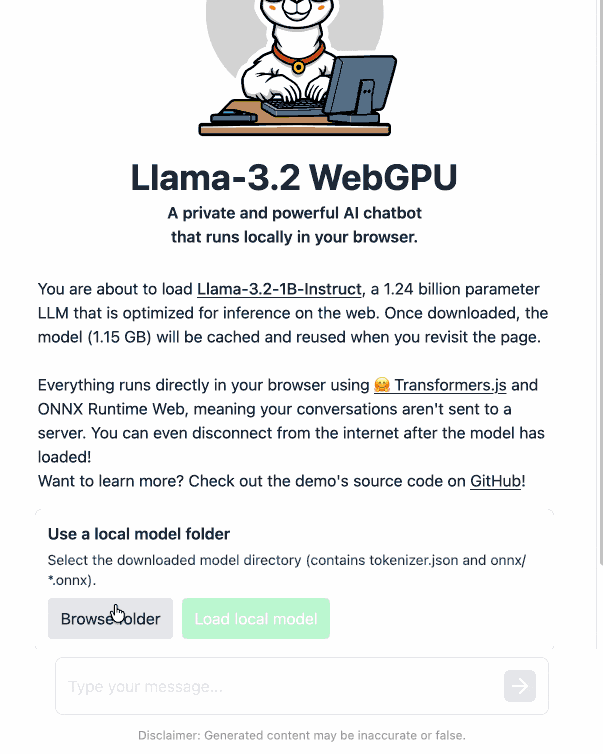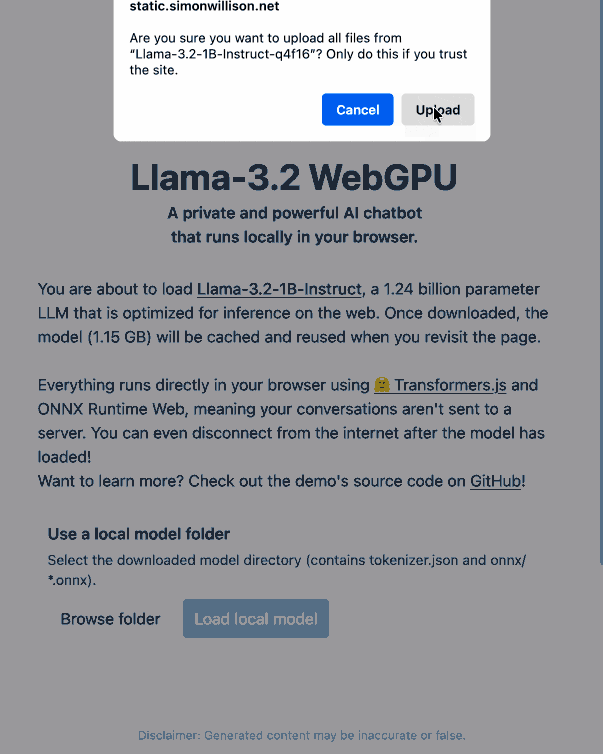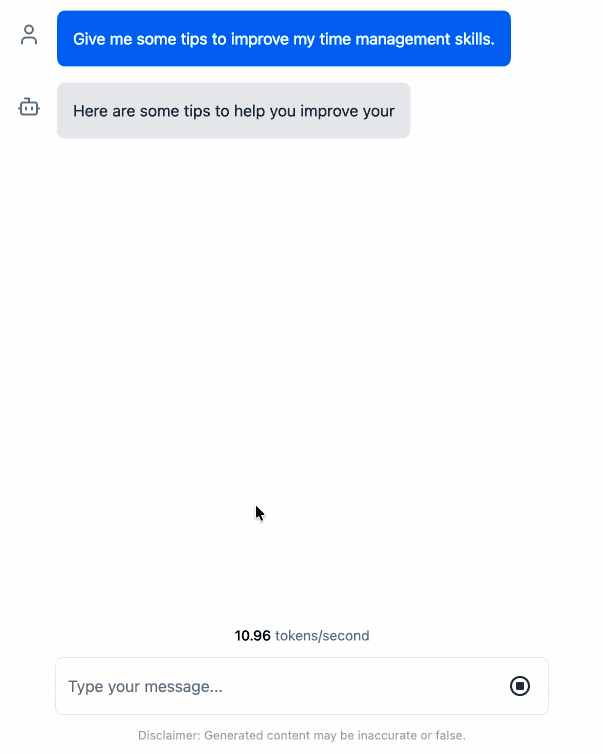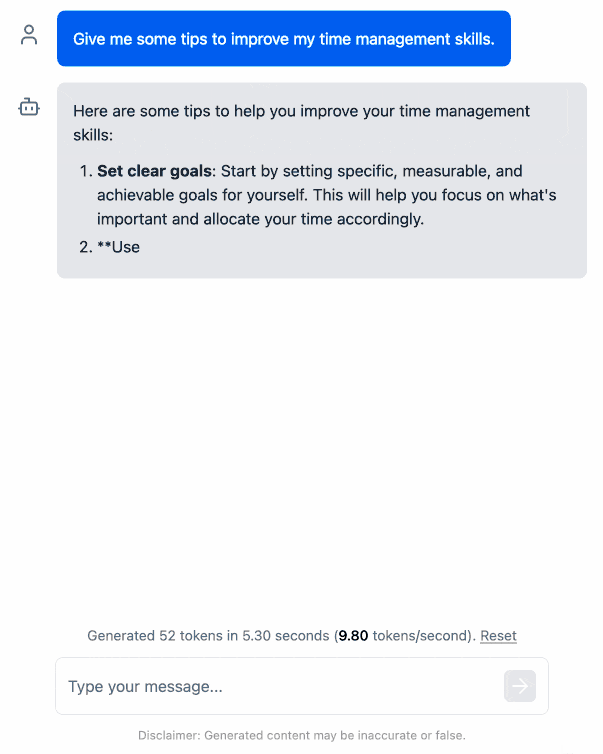
Load Llama-3.2 WebGPU in your browser from a local folder (via) Inspired by a comment on Hacker News I decided to see if it was possible to modify the transformers.js-examples/tree/main/llama-3.2-webgpu Llama 3.2 chat demo (online here, I wrote about it last November) to add an option to open a local model file directly from a folder on disk, rather than waiting for it to download over the network.
I posed the problem to OpenAI's GPT-5-enabled Codex CLI like this:
git clone https://github.com/huggingface/transformers.js-examples
cd transformers.js-examples/llama-3.2-webgpu
codex
Then this prompt:
Modify this application such that it offers the user a file browse button for selecting their own local copy of the model file instead of loading it over the network. Provide a "download model" option too.
Codex churned away for several minutes, even running commands like curl -sL https://raw.githubusercontent.com/huggingface/transformers.js/main/src/models.js | sed -n '1,200p' to inspect the source code of the underlying Transformers.js library.
After four prompts total (shown here) it built something which worked!
To try it out you'll need your own local copy of the Llama 3.2 ONNX model. You can get that (a ~1.2GB) download) like so:
git lfs install
git clone https://huggingface.co/onnx-community/Llama-3.2-1B-Instruct-q4f16
Then visit my llama-3.2-webgpu page in Chrome or Firefox Nightly (since WebGPU is required), click "Browse folder", select that folder you just cloned, agree to the "Upload" confirmation (confusing since nothing is uploaded from your browser, the model file is opened locally on your machine) and click "Load local model".
Here's an animated demo (recorded in real-time, I didn't speed this up):
I pushed a branch with those changes here. The next step would be to modify this to support other models in addition to the Llama 3.2 demo, but I'm pleased to have got to this proof of concept with so little work beyond throwing some prompts at Codex to see if it could figure it out.
According to the Codex /status command this used 169,818 input tokens, 17,112 output tokens and 1,176,320 cached input tokens. At current GPT-5 token pricing ($1.25/million input, $0.125/million cached input, $10/million output) that would cost 53.942 cents, but Codex CLI hooks into my existing $20/month ChatGPT Plus plan so this was bundled into that.
Shipping WebGPU on Windows in Firefox 141 (via) WebGPU is coming to Mac and Linux soon as well:
Although Firefox 141 enables WebGPU only on Windows, we plan to ship WebGPU on Mac and Linux in the coming months, and finally on Android.
From this article I learned that it's already available in Firefox Nightly:
Note that WebGPU has been available in Firefox Nightly on all platforms other than Android for quite some time.
I tried the most recent Nightly on my Mac and now the Github Issue Generator running locally w/ SmolLM2 & WebGPU demo (previously) works! Firefox stable gives me an error message saying "Error: WebGPU is not supported in your current environment, but it is necessary to run the WebLLM engine."
The Firefox implementation is based on wgpu, an open source Rust WebGPU library.
2024
Structured Generation w/ SmolLM2 running in browser & WebGPU (via) Extraordinary demo by Vaibhav Srivastav (VB). Here's Hugging Face's SmolLM2-1.7B-Instruct running directly in a web browser (using WebGPU, so requires Chrome for the moment) demonstrating structured text extraction, converting a text description of an image into a structured GitHub issue defined using JSON schema.
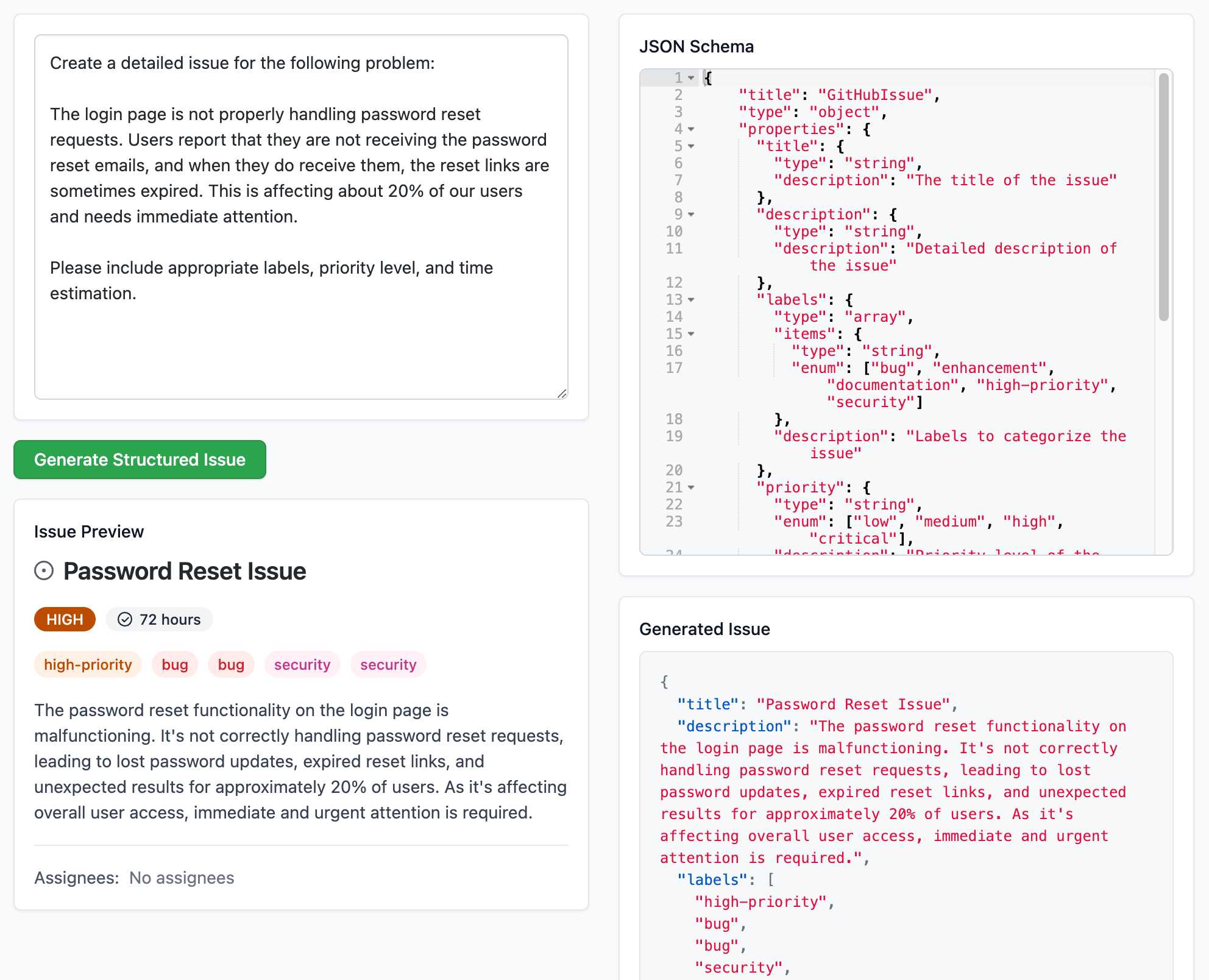
The page loads 924.8MB of model data (according to this script to sum up files in window.caches) and performs everything in-browser. I did not know a model this small could produce such useful results.
Here's the source code for the demo. It's around 200 lines of code, 50 of which are the JSON schema describing the data to be extracted.
The real secret sauce here is web-llm by MLC. This library has made loading and executing prompts through LLMs in the browser shockingly easy, and recently incorporated support for MLC's XGrammar library (also available in Python) which implements both JSON schema and EBNF-based structured output guidance.
llama-3.2-webgpu (via) Llama 3.2 1B is a really interesting models, given its 128,000 token input and its tiny size (barely more than a GB).
This page loads a 1.24GB q4f16 ONNX build of the Llama-3.2-1B-Instruct model and runs it with a React-powered chat interface directly in the browser, using Transformers.js and WebGPU. Source code for the demo is here.
It worked for me just now in Chrome; in Firefox and Safari I got a “WebGPU is not supported by this browser” error message.
[On WebGPU in Firefox] There is a lot of work to do still to make sure we comply with the spec. in a way that's acceptable to ship in a browser. We're 90% of the way there in terms of functionality, but the last 10% of fixing up spec. changes in the last few years + being significantly more resourced-constrained (we have 3 full-time folks, Chrome has/had an order of magnitude more humans working on WebGPU) means we've got our work cut out for us. We're hoping to ship sometime in the next year, but I won't make promises here.
experimental-phi3-webgpu (via) Run Microsoft’s excellent Phi-3 model directly in your browser, using WebGPU so didn’t work in Firefox for me, just in Chrome.
It fetches around 2.1GB of data into the browser cache on first run, but then gave me decent quality responses to my prompts running at an impressive 21 tokens a second (M2, 64GB).
I think Phi-3 is the highest quality model of this size, so it’s a really good fit for running in a browser like this.
2023
WebLLM supports Llama 2 70B now. The WebLLM project from MLC uses WebGPU to run large language models entirely in the browser. They recently added support for Llama 2, including Llama 2 70B, the largest and most powerful model in that family.
To my astonishment, this worked! I used a M2 Mac with 64GB of RAM and Chrome Canary and it downloaded many GBs of data... but it worked, and spat out tokens at a slow but respectable rate of 3.25 tokens/second.
MLC: Bringing Open Large Language Models to Consumer Devices (via) “We bring RedPajama, a permissive open language model to WebGPU, iOS, GPUs, and various other platforms.” I managed to get this running on my Mac (see via link) with a few tweaks to their official instructions.
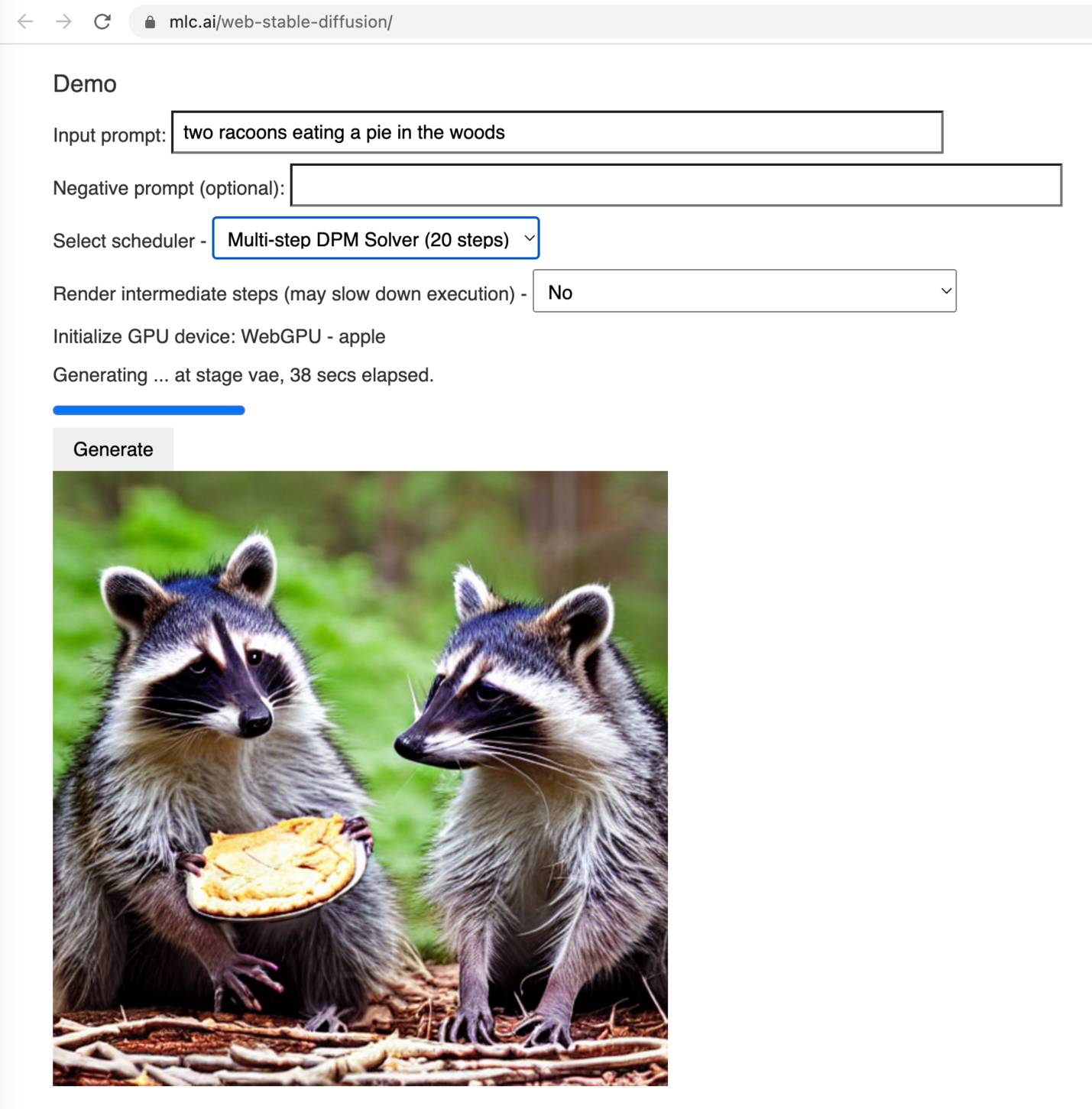
Web Stable Diffusion (via) I just ran the full Stable Diffusion image generation model entirely in my browser, and used it to generate an image of two raccoons eating pie in the woods. I had to use Google Chrome Canary since this depends on WebGPU which still isn't fully rolled out, but it worked perfectly.