Weeknotes: The Squirrel Census, Genome SQL query
21st October 2019
This week was mostly about incremental improvements. And squirrels.
The Squirrel Census
Last October a team of 323 volunteer Squirrel Sighters got together to attempt the first ever comprehensive census of the squirrels in New York’s Central Park.
The result was the Central Park Squirrel Census 2019 Report, an absolutely delightful package you can order from their site that includes two beautiful five foot long maps, a written supplemental report and (not kidding) a 45-RPM vinyl audio report.
I bought a copy and everyone I have shown it to has fallen in love with it.
Last week they released the underlying data through the NYC open data portal! Naturally I loaded it into a Datasette instance (running on Glitch, which is also made in New York). You can facet by fur color.
Analyzing my genome with SQL
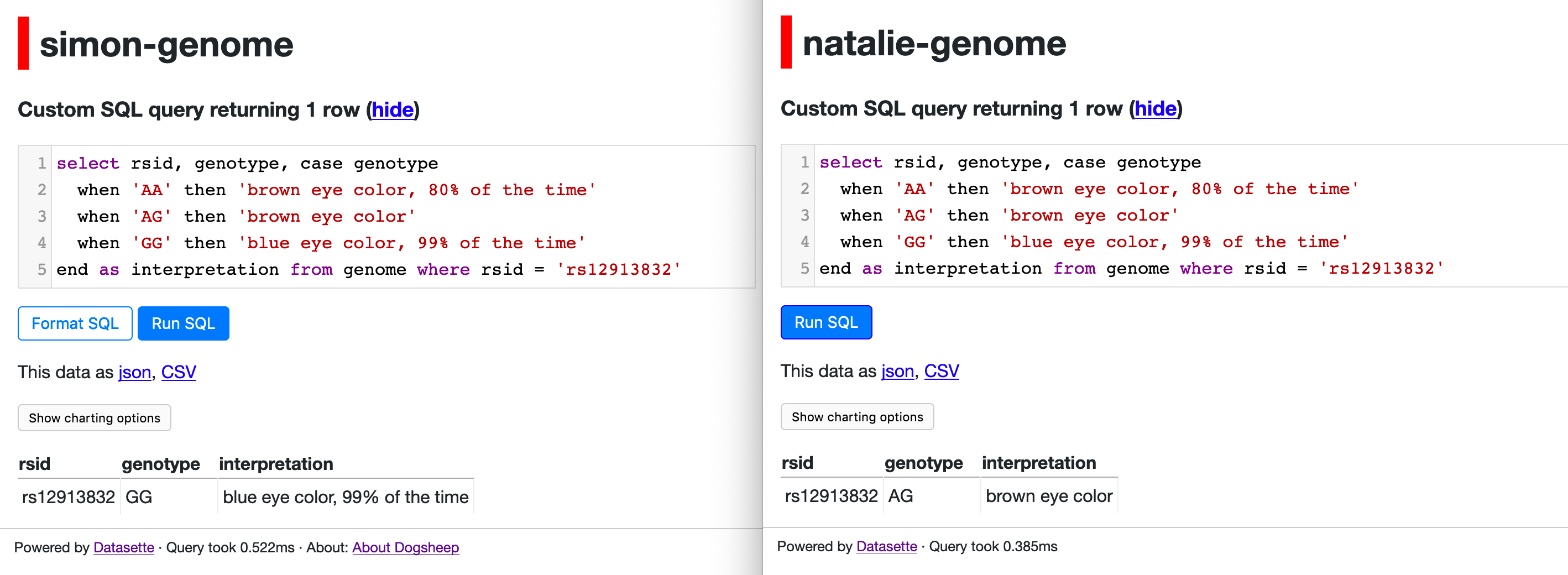
Natalie and I attended the first half of the last San Francisco Science Hack Day. I made a 44 second pitch asking for help using SQL to analyze my genome, and Dr. Laura Cantino answered my call and helped me figure out how to run some fun queries.
Here’s my favourite example so far:
select rsid, genotype, case genotype
when 'AA' then 'brown eye color, 80% of the time'
when 'AG' then 'brown eye color'
when 'GG' then 'blue eye color, 99% of the time'
end as interpretation from genome where rsid = 'rs12913832'
It works! If I run it against my genome it gets GG (blue eyes), and if I run it against Natalie’s it gets AG (brown).
twitter-to-sqlite crons for Dogsheep
I upgraded my personal Dogsheep instance to start fetching fresh data via cron. This meant improving twitter-to-sqlite to be better at incremental data fetching. Here’s the resulting relevant section of my cron tab:
# Fetch new tweets I have tweeted every 10 minutes
1,11,21,31,41,51 * * * * /home/ubuntu/datasette-venv/bin/twitter-to-sqlite user-timeline /home/ubuntu/twitter.db -a /home/ubuntu/auth.json --since
# Fetch most recent 50 tweets I have favourited every 10 minutes
6,16,26,36,46,56 * * * * /home/ubuntu/datasette-venv/bin/twitter-to-sqlite favorites /home/ubuntu/twitter.db -a /home/ubuntu/auth.json --stop_after=50
# Fetch new tweets from my home timeline every 5 minutes
2,7,12,17,22,27,32,37,42,47,52,57 * * * * /home/ubuntu/datasette-venv/bin/twitter-to-sqlite home-timeline /home/ubuntu/timeline.db -a /home/ubuntu/auth.json --since
That last line is quite fun: I’m now hitting the Twitter home-timeline API every five minutes and storing the resulting tweets in a separate timeline.db database. This equates to creating a searchable permanent database of anything tweeted by any of the 3,600+ accounts I follow.
The main thing I’ve learned from this exercise is that I’m really grateful for Twitter’s algorithmic timeline! Accounts I follow tweeted between 13,000 and 22,000 times a day over the past week (/timeline/tweets?_where=id+in+(select+tweet+from+timeline_tweets)&_facet_date=created_at). Trusting the algorithm to show me the highlights frees me to be liberal in following new accounts.
Playing with lit-html
I have a couple of projects brewing where I’ll be building out a JavaScript UI. I used React for both datasette-vega and owlsnearme and it works OK, but it’s pretty weighty (~40KB gzipped) and requires a complex build step.
For my current pro;jects, I’m willing to sacrifice compatibility with older browsers in exchange for less code and no build step.
I considered going completely library free, but having some kind of templating mechanism for constructing complex DOM elements is useful.
I love JavaScript tagged template literals—they’re like Python’s f-strings but even better, because you can provide your own function that executes against every interpolated value—ideal for implementing Django-style autoescaping.
I’ve used them for my own tiny autoescaping implementation in the past, but I’m getting excited about exploring lit-html, which extends the same technique to cover a lot more functionality while still weighing in at less than 4KB gzipped.
Thanks to Laurence Rowe on Twitter I now have a tidy one-liner for running lit-html in the Firefox developer console, loaded from a module:
let {html, render} = await import('https://unpkg.com/lit-html?module');
// Try it out like so:
render(html`<h1>Hello world</h1>`, document.body);
And here’s a full proof-of-concept script showing data loaded from Datasette via fetch() which is then rendered using lit-html:
<div></div>
<script type="module">
import {html, render} from 'https://unpkg.com/lit-html?module';
const myTemplate = (data) => html`<p>Hello ${JSON.stringify(data)}</p>`;
async function go() {
let div = document.getElementsByTagName("div")[0];
var data = await (await fetch("https://latest.datasette.io/fixtures/complex_foreign_keys.json?_labels=on&_shape=array")).json();
render(myTemplate(data), div);
}
go();
</script>
Everything else
I shipped a new release of Datasette (version 0.30) incorporating some bug fixes and the external contributions I talked about last week.
I started work on a new project which has been brewing for a while. Not ready to talk about it yet but I did buy a domain name (through Google Domains this time, but I got some great advice from Twitter on domain registrars with non-terrible UIs in 2019).
More recent articles
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026
- Mr. Chatterbox is a (weak) Victorian-era ethically trained model you can run on your own computer - 30th March 2026