Weeknotes: github-to-sqlite workflows, datasette-ripgrep enhancements, Datasette 0.52
6th December 2020
This week: Improvements to datasette-ripgrep, github-to-sqlite and datasette-graphql, plus Datasette 0.52 and a flurry of dot-releases.
datasette-ripgrep 0.5 and 0.6
datasette-ripgrep (introduced last week) landed on Hacker News, and the comments there inspired me to build a few new features. The interface looks like this now:
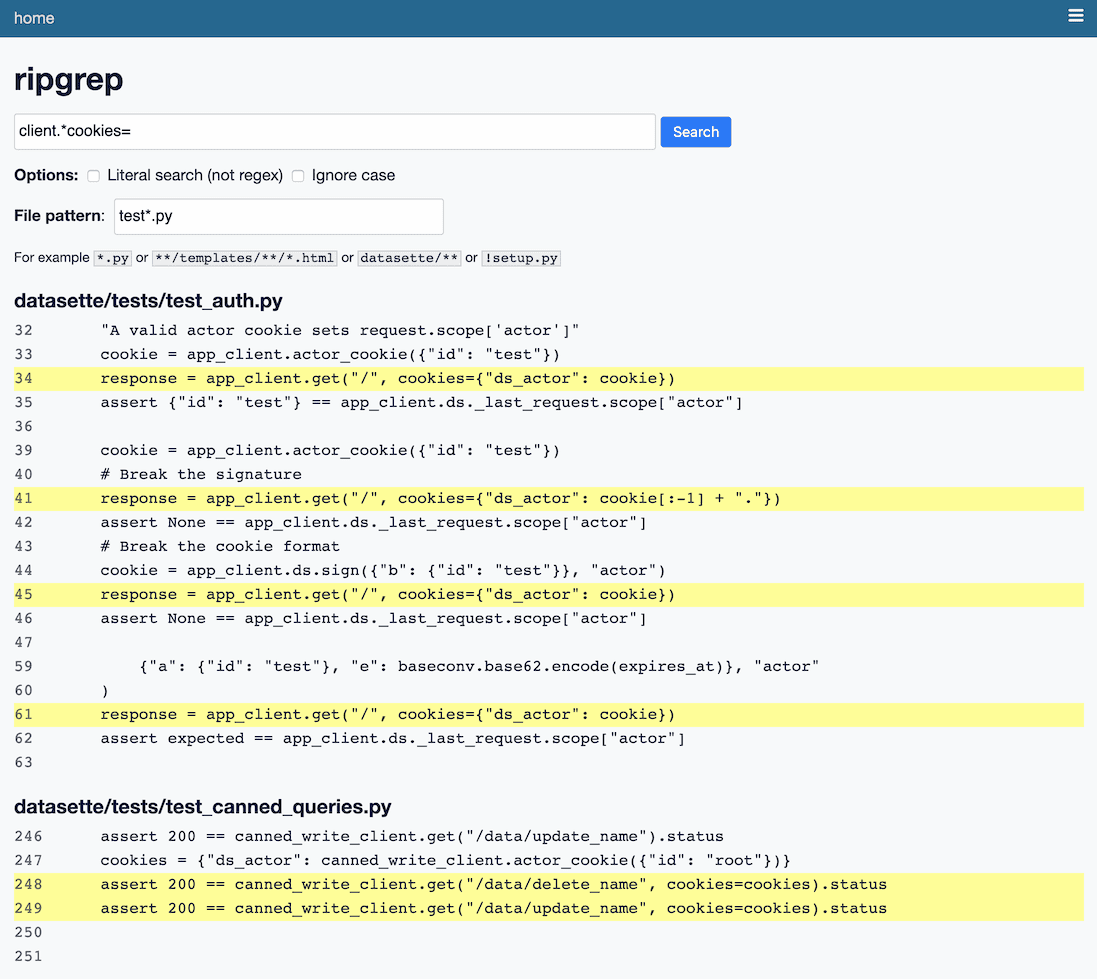
I added options for literal searches (as opposed to a regex match) and ignoring case, and a field that lets you filter to just a specific file pattern, for example test*.py.
These are already features of ripgrep so adding them was a case of hooking up the interface and using it to modify the command-line arguments passed to the underlying tool.
github-to-sqlite workflows
github-to-sqlite is my command-line tool for importing data from the GitHub API into a SQLite database, for analysis with Datasette.
I released github-to-sqlite 2.8 this week with two new commands: github-to-sqlite pull-requests, contributed by Adam Jonas, and github-to-sqlite workflows.
The new workflows command can be run against one or more repositories and will fetch their GitHub Actions workflow YAML files, parse them and use them to populate new database tables called workflows, jobs and steps.
If you run workflows across a bunch of different repositories this means you can analyze your workflow usage using SQL!
My github-to-sqlite demo now includes workflows from my core Datasette and Dogsheep projects. Some example queries:
- My most commonly used action steps—the top two are
actions/checkout@v2andactions/cache@v2. - All steps using actions/cache@v1, which need to be upgraded to
v2(this link will likely soon stop returning any results as I apply those updates). - My workflows that use the workflow_dispatch trigger.
The implementation is a good example of my sqlite-utils library in action—I pass the extracted YAML data straight to the .insert(data, alter=True) method which creates the correct table schema automatically, altering it if there are any missing columns.
datasette-graphql 1.3
datasette-graphql 1.3 has one tiny feature which I find enormously satisfying.
The plugin provides a GraphQL interface to any table in Datasette. The latest versions use the new “table actions” menu (accessible through a cog icon in the page heading) to provide a link to an example query for that table.
I added the example queries in 1.2, but in 1.3 the example has been expanded to include examples of foreign key references. For a table like this one of GitHub commits the example query now looks like this:
{
commits {
totalCount
pageInfo {
hasNextPage
endCursor
}
nodes {
sha
message
author_date
committer_date
raw_author {
id
name
}
raw_committer {
id
name
}
repo {
id
name
}
author {
id
login
}
committer {
id
login
}
}
}
}The new foreign key references include the repo, author and committer fields. The example query now demonstrates the most interesting feature of datasette-graphql—its ability to automatically convert foreign key relationships in your database into nested GraphQL fields.
It’s a small change, but it makes me really happy.
Datasette 0.52
I shipped Datasette 0.52, a relatively minor release which mainly kicked off an effort to rebrand “configuration” as “settings”.
I’m doing this as part of my effort to fix Datasette’s “metadata” concept. The metadata.json file started out as a way to add metadata—title, description, license and source information. Over time the file expanded to cover things like default facet displays and sort orders... and then when plugins came along it grew to cover plugin configuration as well.
This is really confusing. Editing metadata.json to configure a plugin doesn’t make a great deal of sense.
For Datasette 1.0 I want to clean this up. I’m planning on splitting metadata and configuration into separate mechanisms.
There’s just one problem: Datasette already has a “configuration” concept in the form of the --config command-line option which can be used to set some very fundamental options for the Datasette server—things like the SQL time limit and the maximum allowed CSV download size.
I want to call plugin configuration settings “configuration”, so I’ve renamed --config to --settings—see the new settings documentation for details.
This also gave me the chance to clean up a weird design decision. Datasette’s configuration options looked like this:
datasette data.db --config sql_time_limit_ms:1000
The new --setting replacement instead looks like this:
datasette data.db --setting sql_time_limit_ms 1000
Note the lack of a colon here—having an option take two arguments is a perfectly cromulent way of using Click, but it’s one I wasn’t aware of when I first released Datasette.
The old --config mechanism continues to work, but it now displays a deprecation warning—it will be removed in Datasette 1.0.
Datasette dot-releases
0.52 has already had more dot-releases than any other version of Datasette. These are all pure bug fixes, mostly for obscure bugs that are unlikely to have affected anyone. To summarize the release notes:
-
0.52.1 updated the testing plugins documentation to promote
datasette.client, fixed a bug with the display of compound foreign keys and improved the locations searched by thedatasette --load-module=spatialiteshortcut. -
0.52.2 fixed support for the generated columns feature added in SQLite 3.31.0, fixed a 500 error on
OPTIONSrequests, added support for >32MB database file downloads on Cloud Run and shipped a CSS fix to the cog menus contributed by Abdussamet Koçak. - 0.52.3 fixed a fun bug with Datasette installed on Amazon Linux running on ARM where static assets would 404. I eventually tracked that down to an unexpected symlink in the site-packages directory.
-
0.52.4 now writes errors logged by Datasette to
stderr, notstdout. It also fixes a startup error on Windows, another contribution from Abdussamet Koçak.
Broken Dogsheep
My personal Dogsheep broke this week. I’ve been running it on an Amazon Lightsail instance, and this week I learned that Lightsail has a baseline CPU mechanism which grants your instance burst capacity but shuts it down if it exceeds that capacity too often!
So I’m moving it to a DigitalOcean droplet which won’t do that, and trying to figure out enough Ansible to completely automate the process.
My ideal server is one that is configured entirely from files in source control, and updates itself by pulling new configuration from that repository. I plan to use ansible-pull for this, once I’ve put together the necessary playbooks.
More recent articles
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026
- Highlights from my conversation about agentic engineering on Lenny's Podcast - 2nd April 2026