Apply conversion functions to data in SQLite columns with the sqlite-utils CLI tool
6th August 2021
Earlier this week I released sqlite-utils 3.14 with a powerful new command-line tool: sqlite-utils convert, which applies a conversion function to data stored in a SQLite column.
Anyone who works with data will tell you that 90% of the work is cleaning it up. Running command-line conversions against data in a SQLite file turns out to be a really productive way to do that.
Transforming a column
Here’s a simple example. Say someone gave you data with numbers that are formatted with commas—like 3,044,502—in a count column in a states table.
You can strip those commas out like so:
sqlite-utils convert states.db states count \
'value.replace(",", "")'
The convert command takes four arguments: the database file, the name of the table, the name of the column and a string containing a fragment of Python code that defines the conversion to be applied.
The conversion function can be anything you can express with Python. If you want to import extra modules you can do so using --import module—here’s an example that wraps text using the textwrap module from the Python standard library:
sqlite-utils convert content.db articles content \
'"\n".join(textwrap.wrap(value, 100))' \
--import=textwrap
You can consider this analogous to using Array.map() in JavaScript, or running a transformation using a list comprehension in Python.
Custom functions in SQLite
Under the hood, the tool takes advantage of a powerful SQLite feature: the ability to register custom functions written in Python (or other languages) and call them from SQL.
The text wrapping example above works by executing the following SQL:
update articles set content = convert_value(content)convert_value(value) is a custom SQL function, compiled as Python code and then made available to the database connection.
The equivalent code using just the Python standard library would look like this:
import sqlite3 import textwrap def convert_value(value): return "\n".join(textwrap.wrap(value, 100)) conn = sqlite3.connect("content.db") conn.create_function("convert_value", 1, convert_value) conn.execute("update articles set content = convert_value(content)")
sqlite-utils convert works by compiling the code argument to a Python function, registering it with the connection and executing the above SQL query.
Splitting columns into multiple other columns
Sometimes when I’m working with a table I find myself wanting to split a column into multiple other columns.
A classic example is locations—if a location column contains latitude,longitude values I’ll often want to split that into separate latitude and longitude columns, so I can visualize the data with datasette-cluster-map.
The --multi option lets you do that using sqlite-utils convert:
sqlite-utils convert data.db places location '
latitude, longitude = value.split(",")
return {
"latitude": float(latitude),
"longitude": float(longitude),
}' --multi
--multi tells the command to expect the Python code to return dictionaries. It will then create new columns in the database corresponding to the keys in those dictionaries and populate them using the results of the transformation.
If the places table started with just a location column, after running the above command the new table schema will look like this:
CREATE TABLE [places] (
[location] TEXT,
[latitude] FLOAT,
[longitude] FLOAT
);Common recipes
This new feature in sqlite-utils actually started life as a separate tool entirely, called sqlite-transform.
Part of the rationale for adding it to sqlite-utils was to avoid confusion between what that tool did and the sqlite-utils transform tool, which does something completely different (applies table transformations that aren’t possible using SQLite’s default ALTER TABLE statement). Somewhere along the line I messed up with the naming of the two tools!
sqlite-transform bundles a number of useful default transformation recipes, in addition to allowing arbitrary Python code. I ended up making these available in sqlite-utils convert by exposing them as functions that can be called from the command-line code argument like so:
sqlite-utils convert my.db articles created_at \
'r.parsedate(value)'
Implementing them as Python functions in this way meant I didn’t need to invent a new command-line mechanism for passing in additional options to the individual recipes—instead, parameters are passed like this:
sqlite-utils convert my.db articles created_at \
'r.parsedate(value, dayfirst=True)'
Also available in the sqlite_utils Python library
Almost every feature that is exposed by the sqlite-utils command-line tool has a matching API in the sqlite_utils Python library. convert is no exception.
The Python API lets you perform operations like the following:
db = sqlite_utils.Database("dogs.db") db["dogs"].convert("name", lambda value: value.upper())
Any Python callable can be passed to convert, and it will be applied to every value in the specified column—again, like using map() to apply a transformation to every item in an array.
You can also use the Python API to perform more complex operations like the following two examples:
# Convert title to upper case only for rows with id > 20 table.convert( "title", lambda v: v.upper(), where="id > :id", where_args={"id": 20} ) # Create two new columns, "upper" and "lower", # and populate them from the converted title table.convert( "title", lambda v: { "upper": v.upper(), "lower": v.lower() }, multi=True )
See the full documentation for table.convert() for more options.
A more sophisticated example: analyzing log files
I used the new sqlite-utils convert command earlier today, to debug a performance issue with my blog.
Most of my blog traffic is served via Cloudflare with a 15 minute cache timeout—but occasionally I’ll hit an uncached page, and they had started to feel not quite as snappy as I would expect.
So I dipped into the Heroku dashboard, and saw this pretty sad looking graph:
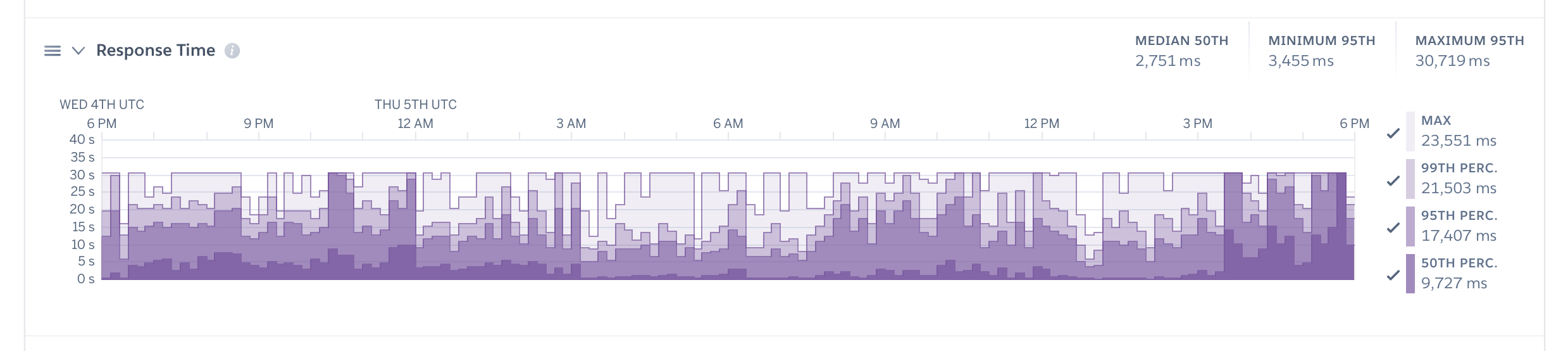
Somehow my 50th percentile was nearly 10 seconds, and my maximum page response time was 23 seconds! Something was clearly very wrong.
I use NGINX as part of my Heroku setup to buffer responses (see Running gunicorn behind nginx on Heroku for buffering and logging), and I have custom NGINX configuration to write to the Heroku logs—mainly to work around a limitation in Heroku’s default logging where it fails to record full user-agents or referrer headers.
I extended that configuration to record the NGINX request_time, upstream_response_time, upstream_connect_time and upstream_header_time variables, which I hoped would help me figure out what was going on.
After applying that change I started seeing Heroku log lines that looked like this:
2021-08-05T17:58:28.880469+00:00 app[web.1]: measure#nginx.service=4.212 request="GET /search/?type=blogmark&page=2&tag=highavailability HTTP/1.1" status_code=404 request_id=25eb296e-e970-4072-b75a-606e11e1db5b remote_addr="10.1.92.174" forwarded_for="114.119.136.88, 172.70.142.28" forwarded_proto="http" via="1.1 vegur" body_bytes_sent=179 referer="-" user_agent="Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://webmaster.petalsearch.com/site/petalbot)" request_time="4.212" upstream_response_time="4.212" upstream_connect_time="0.000" upstream_header_time="4.212";
Next step: analyze those log lines.
I ran this command for a few minutes to gather some logs:
heroku logs -a simonwillisonblog --tail | grep 'measure#nginx.service' > /tmp/log.txt
Having collected 488 log lines, the next step was to load them into SQLite.
The sqlite-utils insert command likes to work with JSON, but I just had raw log lines. I used jq to convert each line into a {"line": "raw log line"} JSON object, then piped that as newline-delimited JSON into sqlite-utils insert:
cat /tmp/log.txt | \
jq --raw-input '{line: .}' --compact-output | \
sqlite-utils insert /tmp/logs.db log - --nl
jq --raw-input accepts input that is just raw lines of text, not yet valid JSON. '{line: .}' is a tiny jq program that builds {"line": "raw input"} objects. --compact-output causes jq to output newline-delimited JSON.
Then sqlite-utils insert /tmp/logs.db log - --nl reads that newline-delimited JSON into a new SQLite log table in a logs.db database file (full documentation here).
Update 6th January 2022: sqlite-utils 3.20 introduced a new sqlite-utils insert ... --lines option for importing raw lines, so you can now achieve this without using jq at all. See
Inserting unstructured data with --lines and --text for details.
Now I had a SQLite table with a single column, line. Next step: parse that nasty log format.
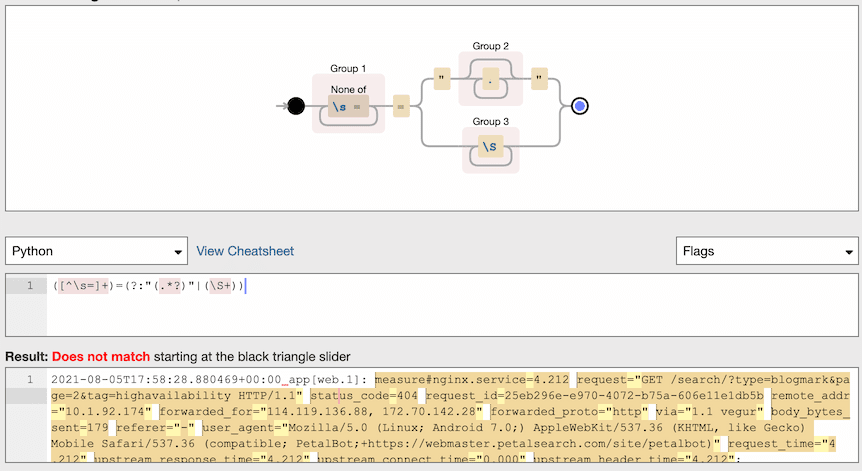
To my surprise I couldn’t find an existing Python library for parsing key=value key2="quoted value" log lines. Instead I had to figure out a regular expression:
([^\s=]+)=(?:"(.*?)"|(\S+))
Here’s that expression visualized using Debuggex:
I used that regular expression as part of a custom function passed in to the sqlite-utils convert tool:
sqlite-utils convert /tmp/logs.db log line --import re --multi "$(cat <<EOD
r = re.compile(r'([^\s=]+)=(?:"(.*?)"|(\S+))')
pairs = {}
for key, value1, value2 in r.findall(value):
pairs[key] = value1 or value2
return pairs
EOD
)"
(This uses a cat <<EOD trick to avoid having to figure out how to escape the single and double quotes in the Python code for usage in a zsh shell command.)
Using --multi here created new columns for each of the key/value pairs seen in that log file.
One last step: convert the types. The new columns are all of type text but I want to do sorting and arithmetic on them so I need to convert them to integers and floats. I used sqlite-utils transform for that:
sqlite-utils transform /tmp/logs.db log \
--type 'measure#nginx.service' float \
--type 'status_code' integer \
--type 'body_bytes_sent' integer \
--type 'request_time' float \
--type 'upstream_response_time' float \
--type 'upstream_connect_time' float \
--type 'upstream_header_time' float
Here’s the resulting log table (in Datasette Lite).
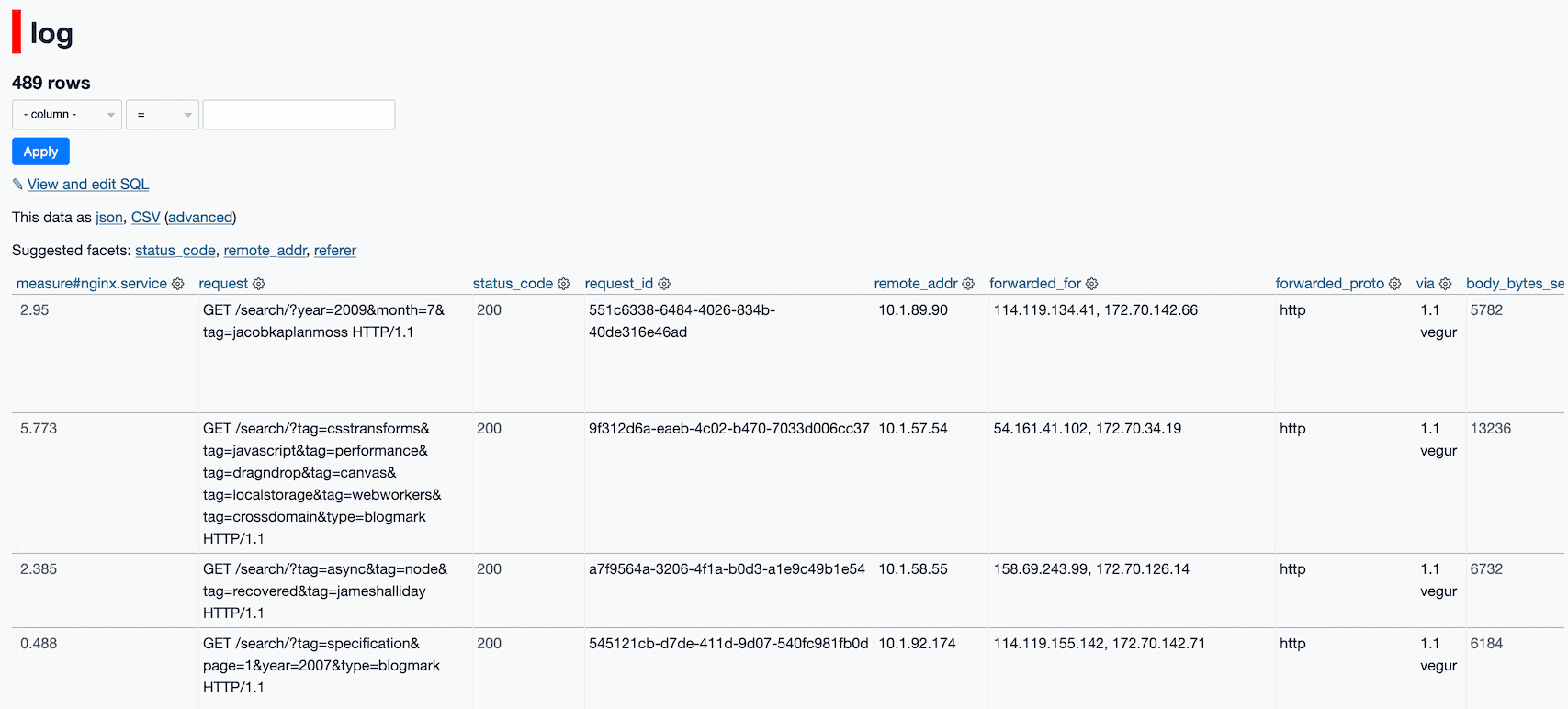
Once the logs were in Datasette, the problem quickly became apparent when I sorted by request_time: an army of search engine crawlers were hitting deep linked filters in my faceted search engine, like /search/?tag=geolocation&tag=offlineresources&tag=canvas&tag=javascript&tag=performance&tag=dragndrop&tag=crossdomain&tag=mozilla&tag=video&tag=tracemonkey&year=2009&type=blogmark. These are expensive pages to generate! They’re also very unlikely to be in my Cloudflare cache.
Could the answer be as simple as a robots.txt rule blocking access to /search/?
I shipped that change and waited a few hours to see what the impact would be:

It took a while for the crawlers to notice that my robots.txt had changed, but by 8 hours later my site performance was dramatically improved—I’m now seeing 99th percentile of around 450ms, compared to 25 seconds before I shipped the robots.txt change!
With this latest addition, sqlite-utils has evolved into a powerful tool for importing, cleaning and re-shaping data—especially when coupled with Datasette in order to explore, analyze and publish the results.
TIL this week
- Search and replace with regular expressions in VS Code
- Check spelling using codespell
- Set a GIF to loop using ImageMagick
- SQLite aggregate filter clauses
- Compressing an animated GIF with ImageMagick mogrify
Releases this week
-
sqlite-transform: 1.2.1—(10 releases total)—2021-08-02
Tool for running transformations on columns in a SQLite database -
sqlite-utils: 3.14—(82 releases total)—2021-08-02
Python CLI utility and library for manipulating SQLite databases -
datasette-json-html: 1.0.1—(6 releases total)—2021-07-31
Datasette plugin for rendering HTML based on JSON values -
datasette-publish-fly: 1.0.2—(5 releases total)—2021-07-30
Datasette plugin for publishing data using Fly
More recent articles
- Claude Opus 4.8: "a modest but tangible improvement" - 28th May 2026
- I think Anthropic and OpenAI have found product-market fit - 27th May 2026
- Notes on Pope Leo XIV's encyclical on AI - 25th May 2026