December 2021
52 posts: 5 entries, 15 links, 2 quotes, 30 beats
Dec. 1, 2021

Weeknotes: Shaving some beautiful yaks

I’ve been mostly shaving yaks this week—two in particular: the Datasette table refactor and the next release of git-history. I also built and released my first Web Component!
[... 1,307 words]Dec. 2, 2021
100 years of whatever this will be. This piece by apenwarr defies summarization but I enjoyed reading it a lot.
Dec. 3, 2021
Dec. 5, 2021
jc (via) This is such a great idea: jc is a CLI tool which knows how to convert the output of dozens of different classic Unix utilities to JSON, so you can more easily process it programmatically, pipe it through jq and suchlike. “pipx install jc” to install, then “dig example.com | jc --dig” to try it out.
Dec. 6, 2021
Centrifuge: a reliable system for delivering billions of events per day (via) From 2018, a write-up from Segment explaining how they solved the problem of delivering webhooks from thousands of different producers to hundreds of potentially unreliable endpoints. They started with Kafka and ended up on a custom system written in Go against RDS MySQL that was specifically tuned to their write-heavy requirements.
1.1.1.1/purge-cache (via) Cloudflare’s 1.1.1.1 DNS service has a tool that anyone can use to flush a specific DNS entry from their cache—could be useful for assisting rollouts of new DNS configurations.
Google Public DNS Flush Cache (via) Google Public DNS (8.8.8.8) have a flush cache page too.
Dec. 7, 2021
s3-credentials 0.8. The latest release of my s3-credentials CLI tool for creating S3 buckets with credentials to access them (with read-write, read-only or write-only policies) adds a new --public option for creating buckets that allow public access, such that anyone who knows a filename can download a file. The s3-credentials put-object command also now sets the appropriate Content-Type heading on the uploaded object.
One popular way of making money through cryptocurrency is to start a new currency, while retaining a large chunk of it for yourself. As a result, there are now thousands of competing cryptocurrencies in operation, with relatively little technical difference between them. In order to succeed, currency founders must convince people that their currency is new and different, and crucially, that the buyer understands this while other less savvy investors do not. Wild claims, fanciful economic ideas and rampant technobabble are the order of the day. This is a field that thrives on mystique, and particularly preys on participants’ fear of missing out on the next big thing.

git-history: a tool for analyzing scraped data collected using Git and SQLite
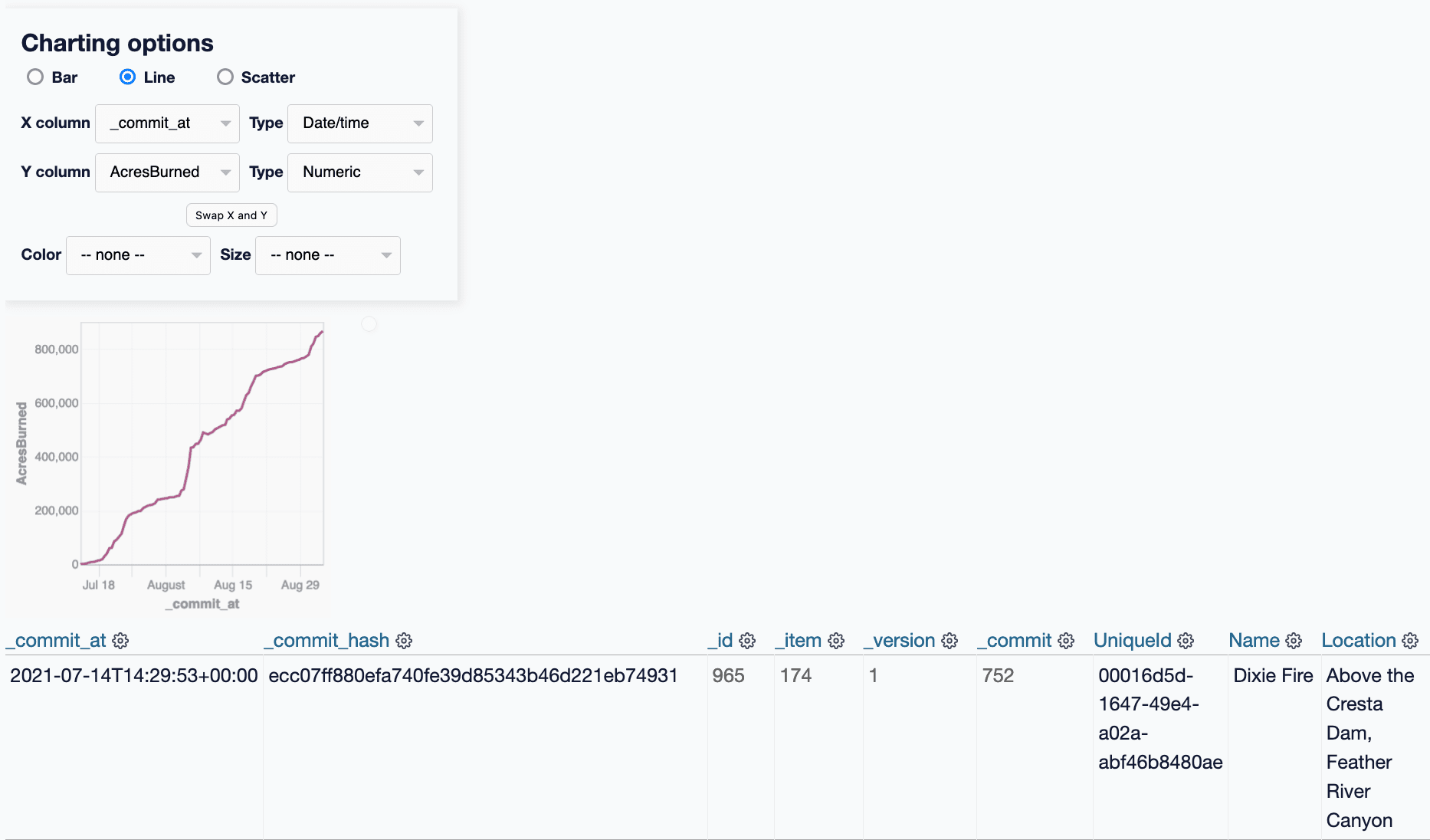
I described Git scraping last year: a technique for writing scrapers where you periodically snapshot a source of data to a Git repository in order to record changes to that source over time.
[... 2,002 words]Dec. 8, 2021
Weeknotes: git-history, bug magnets and s3-credentials --public
I’ve stopped considering my projects “shipped” until I’ve written a proper blog entry about them, so yesterday I finally shipped git-history, coinciding with the release of version 0.6—a full 27 days after the first 0.1.
[... 1,013 words]Dec. 9, 2021

Notes on Notes.app. Apple’s Notes app keeps its data in a SQLite database at ~/Library/Group\ Containers/group.com.apple.notes/NoteStore.sqlite—but it’s pretty difficult to extract data from. It turns out the note text is stored as a gzipped protocol buffers object in the ZICNOTEDATA.ZDATA column. Steve Dunham did the hard work of figuring out how it all works—the complexity stems from Apple’s use of CRDT’s to support seamless multiple edits from different devices.
Introducing stack graphs (via) GitHub launched “precise code navigation” for Python today—the first language to get support for this feature. Click on any Python symbol in GitHub’s code browsing views and a box will show you exactly where that symbol was defined—all based on static analysis by a custom parser written in Rust as opposed to executing any Python code directly. The underlying computer science uses a technique called stack graphs, based on scope graphs research from Eelco Visser’s research group at TU Delft.
Dec. 10, 2021
wheel.yml for Pyjion using cibuildwheel (via) cibuildwheel, maintained by the Python Packaging Authority, builds and tests Python wheels across multiple platforms. I hadn’t realized quite how minimal a configuration using their GitHub Actions action was until I looked at how Pyjion was using it.
Dec. 11, 2021

Dec. 12, 2021
servefolder.dev (via) Absurdly clever application of service workers and the file system API: you can select a folder from your computer and the contents of that folder will be served (just to you) from a path on this website—all without uploading any content. The code is on GitHub and offers a useful, succinct introduction to how to use those APIs.