git-history: a tool for analyzing scraped data collected using Git and SQLite
7th December 2021
I described Git scraping last year: a technique for writing scrapers where you periodically snapshot a source of data to a Git repository in order to record changes to that source over time.
The open challenge was how to analyze that data once it was collected. git-history is my new tool designed to tackle that problem.
Git scraping, a refresher
A neat thing about scraping to a Git repository is that the scrapers themselves can be really simple. I demonstrated how to run scrapers for free using GitHub Actions in this five minute lightning talk back in March.
Here’s a concrete example: California’s state fire department, Cal Fire, maintain an incident map at fire.ca.gov/incidents showing the status of current large fires in the state.
I found the underlying data here:
curl https://www.fire.ca.gov/umbraco/Api/IncidentApi/GetIncidents
Then I built a simple scraper that grabs a copy of that every 20 minutes and commits it to Git. I’ve been running that for 14 months now, and it’s collected 1,559 commits!
The thing that excites me most about Git scraping is that it can create truly unique datasets. It’s common for organizations not to keep detailed archives of what changed and where, so by scraping their data into a Git repository you can often end up with a more detailed history than they maintain themselves.
There’s one big challenge though; having collected that data, how can you best analyze it? Reading through thousands of commit differences and eyeballing changes to JSON or CSV files isn’t a great way of finding the interesting stories that have been captured.
git-history
git-history is the new CLI tool I’ve built to answer that question. It reads through the entire history of a file and generates a SQLite database reflecting changes to that file over time. You can then use Datasette to explore the resulting data.
Here’s an example database created by running the tool against my ca-fires-history repository. I created the SQLite database by running this in the repository directory:
git-history file ca-fires.db incidents.json \
--namespace incident \
--id UniqueId \
--convert 'json.loads(content)["Incidents"]'
In this example we are processing the history of a single file called incidents.json.
We use the UniqueId column to identify which records are changed over time as opposed to newly created.
Specifying --namespace incident causes the created database tables to be called incident and incident_version rather than the default of item and item_version.
And we have a fragment of Python code that knows how to turn each version stored in that commit history into a list of objects compatible with the tool, see --convert in the documentation for details.
Let’s use the database to answer some questions about fires in California over the past 14 months.
The incident table contains a copy of the latest record for every incident. We can use that to see a map of every fire:
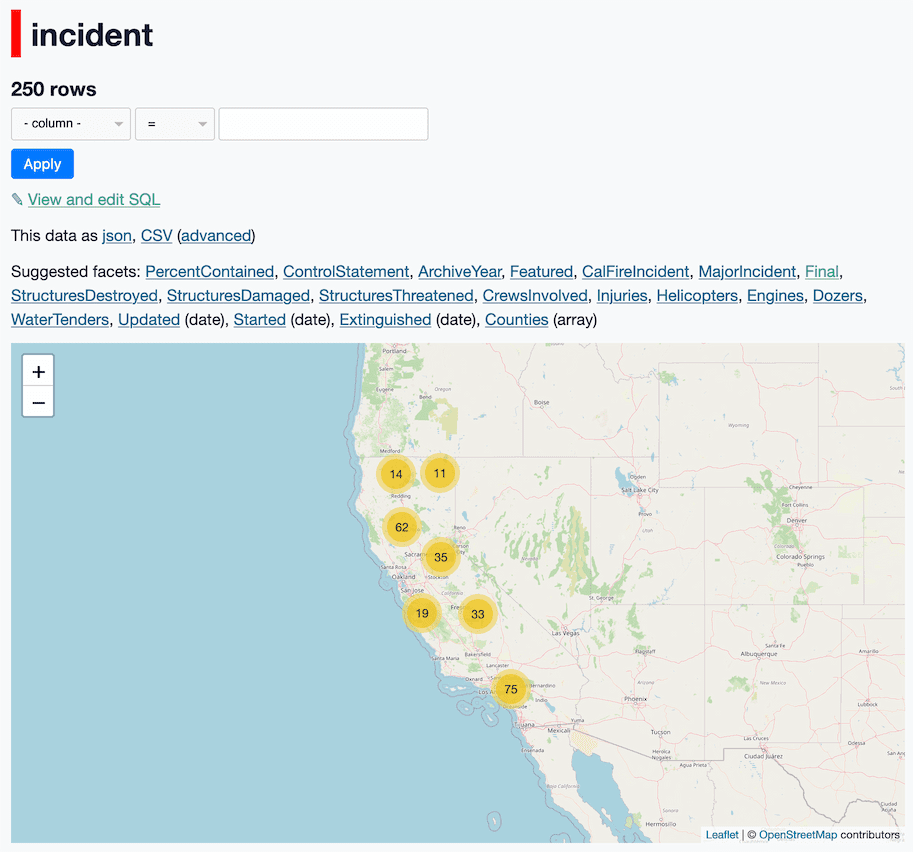
This uses the datasette-cluster-map plugin, which draws a map of every row with a valid latitude and longitude column.
Where things get interesting is the incident_version table. This is where changes between different scraped versions of each item are recorded.
Those 250 fires have 2,060 recorded versions. If we facet by _item we can see which fires had the most versions recorded. Here are the top ten:
- Dixie Fire 268
- Caldor Fire 153
- Monument Fire 65
- August Complex (includes Doe Fire) 64
- Creek Fire 56
- French Fire 53
- Silverado Fire 52
- Fawn Fire 45
- Blue Ridge Fire 39
- McFarland Fire 34
This looks about right—the larger the number of versions the longer the fire must have been burning. The Dixie Fire has its own Wikipedia page!
Clicking through to the Dixie Fire lands us on a page showing every “version” that we captured, ordered by version number.
git-history only writes values to this table that have changed since the previous version. This means you can glance at the table grid and get a feel for which pieces of information were updated over time:
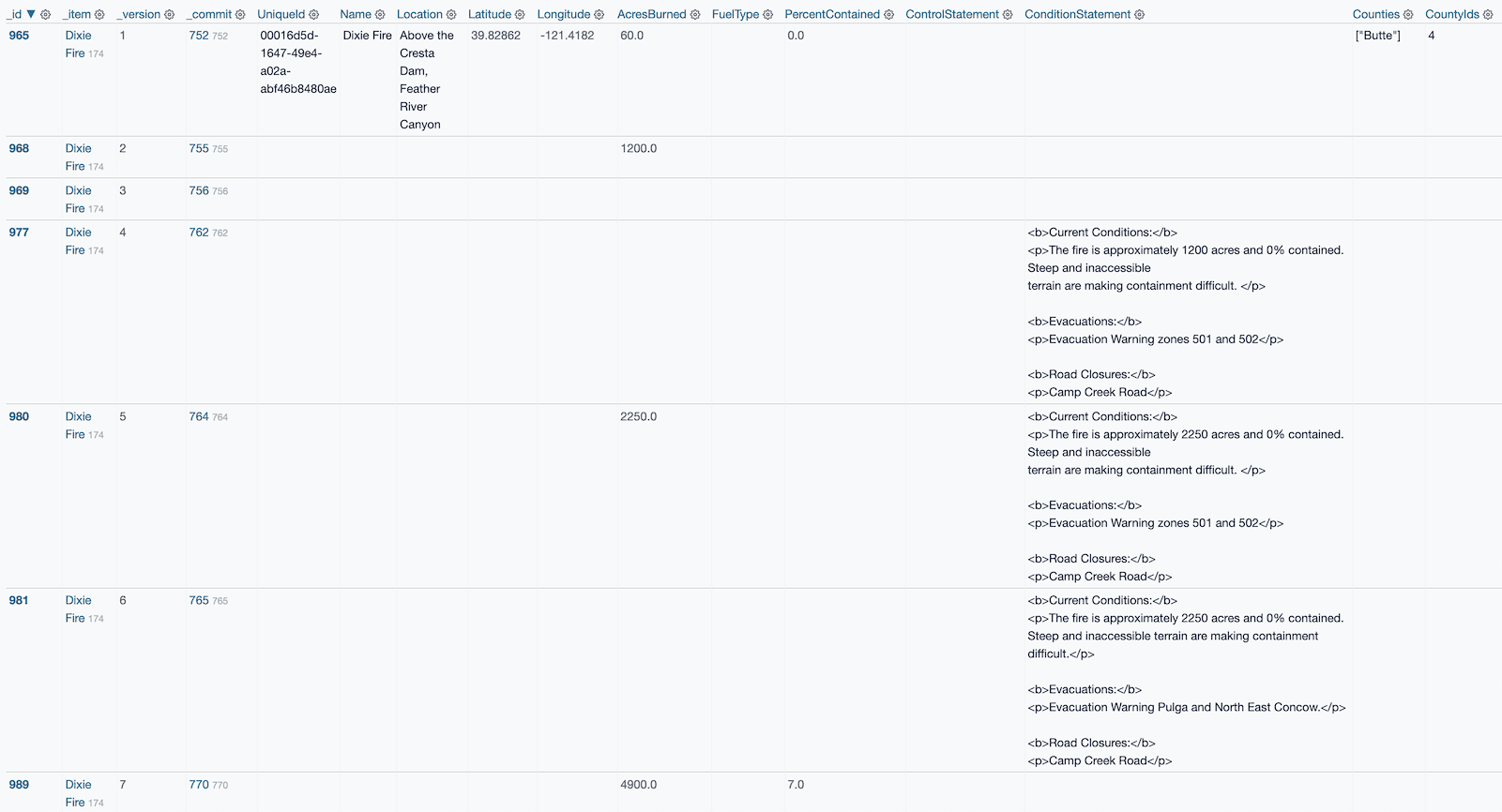
The ConditionStatement is a text description that changes frequently, but the other two interesting columns look to be AcresBurned and PercentContained.
That _commit table is a foreign key to commits, which records commits that have been processed by the tool— mainly so that when you run it a second time it can pick up where it finished last time.
We can join against commits to see the date that each version was created. Or we can use the incident_version_detail view which performs that join for us.
Using that view, we can filter for just rows where _item is 174 and AcresBurned is not blank, then use the datasette-vega plugin to visualize the _commit_at date column against the AcresBurned numeric column... and we get a graph of the growth of the Dixie Fire over time!
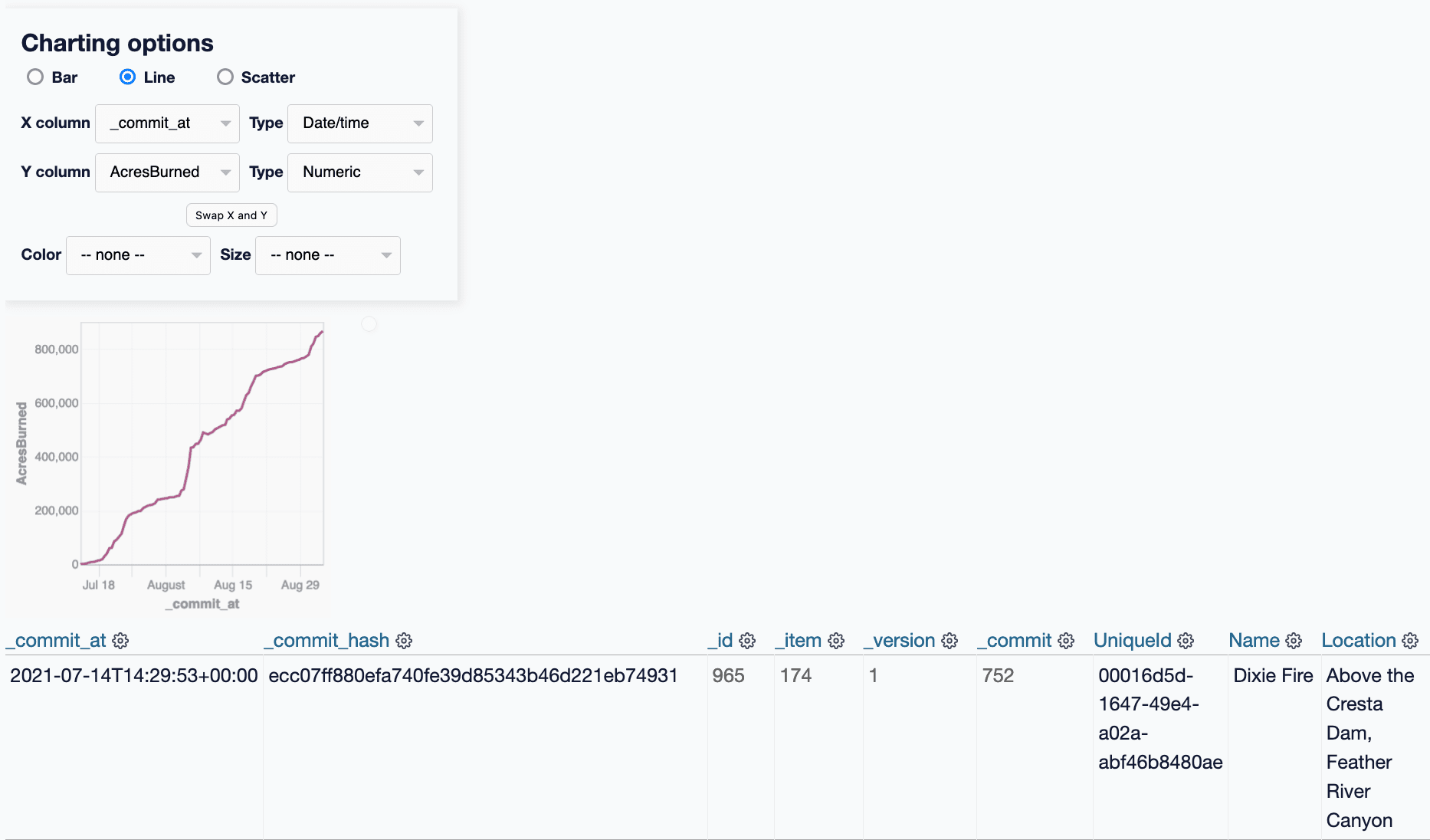
To review: we started out with a GitHub Actions scheduled workflow grabbing a copy of a JSON API endpoint every 20 minutes. Thanks to git-history, Datasette and datasette-vega we now have a chart showing the growth of the longest-lived California wildfire of the last 14 months over time.
A note on schema design
One of the hardest problems in designing git-history was deciding on an appropriate schema for storing version changes over time.
I ended up with the following (edited for clarity):
CREATE TABLE [commits] (
[id] INTEGER PRIMARY KEY,
[hash] TEXT,
[commit_at] TEXT
);
CREATE TABLE [item] (
[_id] INTEGER PRIMARY KEY,
[_item_id] TEXT,
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT,
[_commit] INTEGER
);
CREATE TABLE [item_version] (
[_id] INTEGER PRIMARY KEY,
[_item] INTEGER REFERENCES [item]([_id]),
[_version] INTEGER,
[_commit] INTEGER REFERENCES [commits]([id]),
[IncidentID] TEXT,
[Location] TEXT,
[Type] TEXT
);
CREATE TABLE [columns] (
[id] INTEGER PRIMARY KEY,
[namespace] INTEGER REFERENCES [namespaces]([id]),
[name] TEXT
);
CREATE TABLE [item_changed] (
[item_version] INTEGER REFERENCES [item_version]([_id]),
[column] INTEGER REFERENCES [columns]([id]),
PRIMARY KEY ([item_version], [column])
);As shown earlier, records in the item_version table represent snapshots over time—but to save on database space and provide a neater interface for browsing versions, they only record columns that had changed since their previous version. Any unchanged columns are stored as null.
There’s one catch with this schema: what do we do if a new version of an item sets one of the columns to null? How can we tell the difference between that and a column that didn’t change?
I ended up solving that with an item_changed many-to-many table, which uses pairs of integers (hopefully taking up as little space as possible) to record exactly which columns were modified in which item_version records.
The item_version_detail view displays columns from that many-to-many table as JSON—here’s a filtered example showing which columns were changed in which versions of which items:

Here’s a SQL query that shows, for ca-fires, which columns were updated most often:
select columns.name, count(*)
from incident_changed
join incident_version on incident_changed.item_version = incident_version._id
join columns on incident_changed.column = columns.id
where incident_version._version > 1
group by columns.name
order by count(*) desc- Updated: 1785
- PercentContained: 740
- ConditionStatement: 734
- AcresBurned: 616
- Started: 327
- PersonnelInvolved: 286
- Engines: 274
- CrewsInvolved: 256
- WaterTenders: 225
- Dozers: 211
- AirTankers: 181
- StructuresDestroyed: 125
- Helicopters: 122
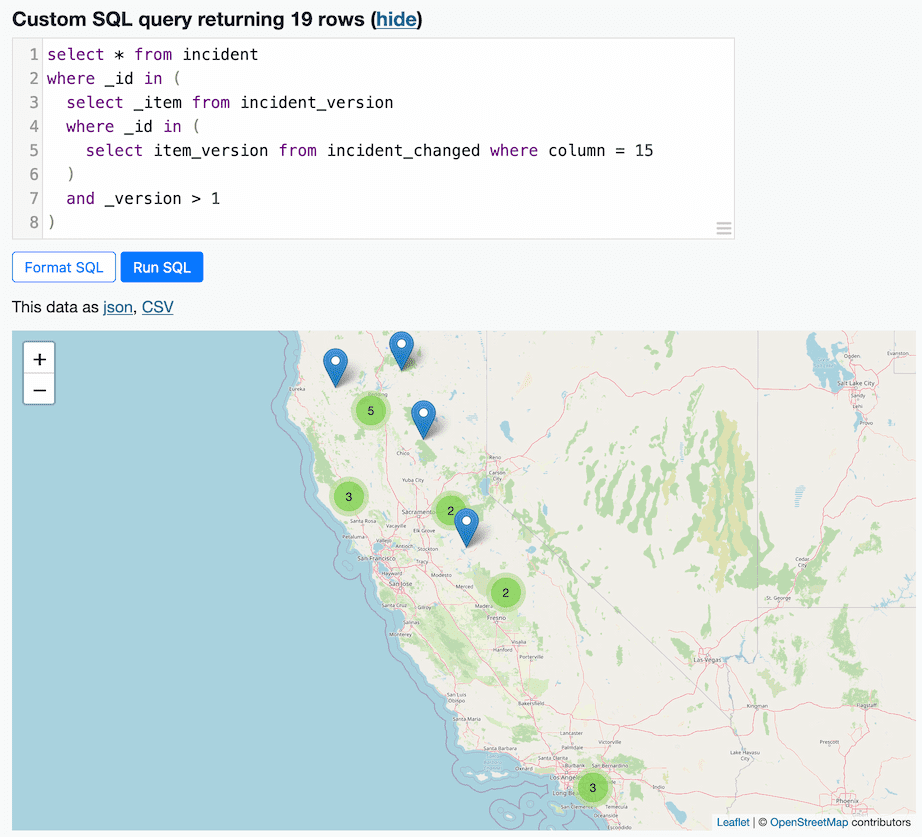
Helicopters are exciting! Let’s find all of the fires which had at least one record where the number of helicopters changed (after the first version). We’ll use a nested SQL query:
select * from incident
where _id in (
select _item from incident_version
where _id in (
select item_version from incident_changed where column = 15
)
and _version > 1
)That returned 19 fires that were significant enough to involve helicopters—here they are on a map:
Advanced usage of --convert
Drew Breunig has been running a Git scraper for the past 8 months in dbreunig/511-events-history against 511.org, a site showing traffic incidents in the San Francisco Bay Area. I loaded his data into this example sf-bay-511 database.
The sf-bay-511 example is useful for digging more into the --convert option to git-history.
git-history requires recorded data to be in a specific shape: it needs a JSON list of JSON objects, where each object has a column that can be treated as a unique ID for purposes of tracking changes to that specific record over time.
The ideal tracked JSON file would look something like this:
[
{
"IncidentID": "abc123",
"Location": "Corner of 4th and Vermont",
"Type": "fire"
},
{
"IncidentID": "cde448",
"Location": "555 West Example Drive",
"Type": "medical"
}
]It’s common for data that has been scraped to not fit this ideal shape.
The 511.org JSON feed can be found here—it’s a pretty complicated nested set of objects, and there’s a bunch of data in there that’s quite noisy without adding much to the overall analysis—things like a updated timestamp field that changes in every version even if there are no changes, or a deeply nested "extension" object full of duplicate data.
I wrote a snippet of Python to transform each of those recorded snapshots into a simpler structure, and then passed that Python code to the --convert option to the script:
#!/bin/bash
git-history file sf-bay-511.db 511-events-history/events.json \
--repo 511-events-history \
--id id \
--convert '
data = json.loads(content)
if data.get("error"):
# {"code": 500, "error": "Error accessing remote data..."}
return
for event in data["Events"]:
event["id"] = event["extension"]["event-reference"]["event-identifier"]
# Remove noisy updated timestamp
del event["updated"]
# Drop extension block entirely
del event["extension"]
# "schedule" block is noisy but not interesting
del event["schedule"]
# Flatten nested subtypes
event["event_subtypes"] = event["event_subtypes"]["event_subtype"]
if not isinstance(event["event_subtypes"], list):
event["event_subtypes"] = [event["event_subtypes"]]
yield event
'
The single-quoted string passed to --convert is compiled into a Python function and run against each Git version in turn. My code loops through the nested Events list, modifying each record and then outputting them as an iterable sequence using yield.
A few of the records in the history were server 500 errors, so the code block knows how to identify and skip those as well.
When working with git-history I find myself spending most of my time iterating on these conversion scripts. Passing strings of Python code to tools like this is a pretty fun pattern—I also used it for sqlite-utils convert earlier this year.
Trying this out yourself
If you want to try this out for yourself the git-history tool has an extensive README describing the other options, and the scripts used to create these demos can be found in the demos folder.
The git-scraping topic on GitHub now has over 200 repos now built by dozens of different people—that’s a lot of interesting scraped data sat there waiting to be explored!
More recent articles
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026