Thursday, 30th June 2022
s3-ocr: Extract text from PDF files stored in an S3 bucket
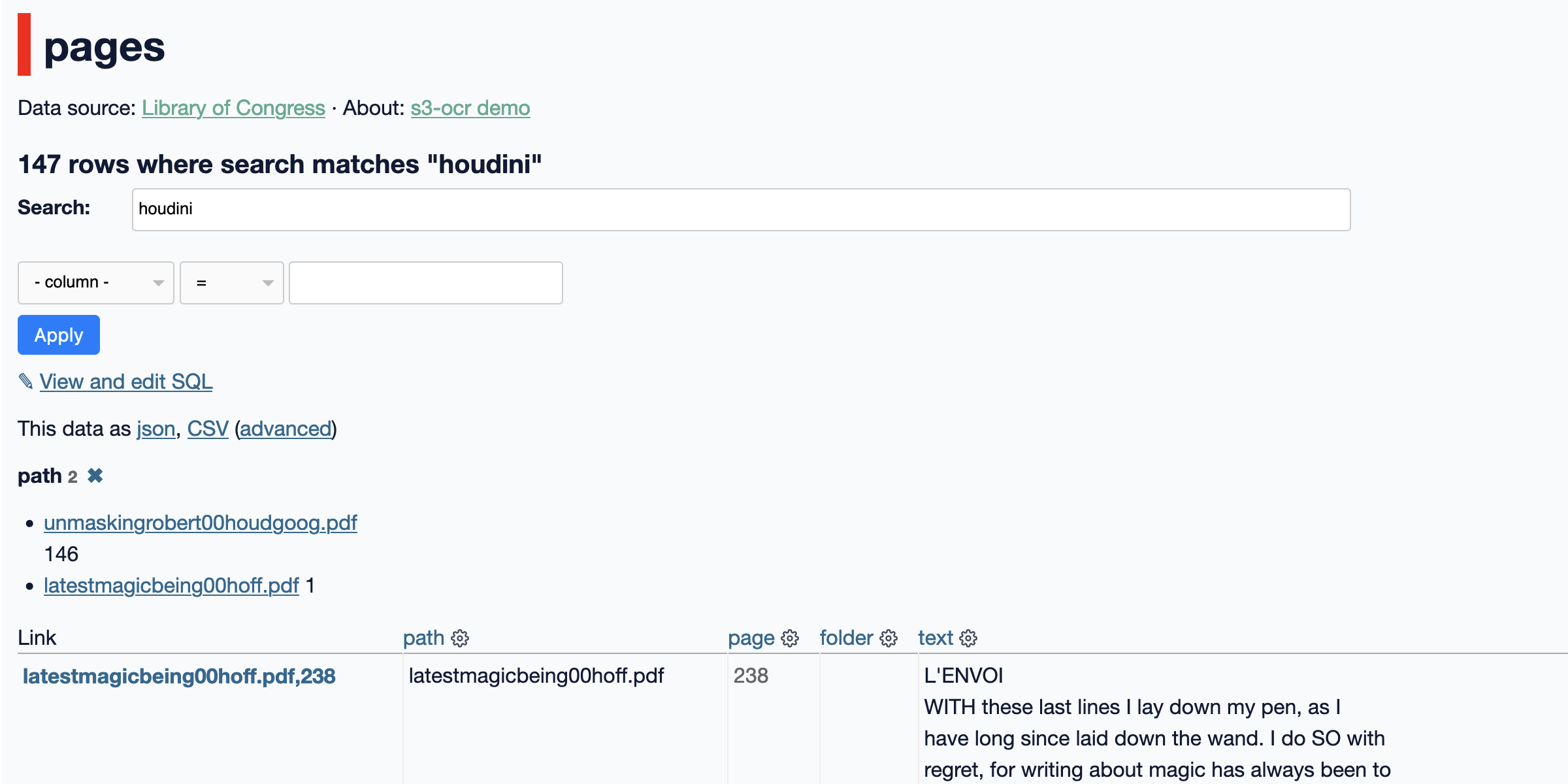
I’ve released s3-ocr, a new tool that runs Amazon’s Textract OCR text extraction against PDF files in an S3 bucket, then writes the resulting text out to a SQLite database with full-text search configured so you can run searches against the extracted data.
[... 1,493 words]