Exploring MusicCaps, the evaluation data released to accompany Google’s MusicLM text-to-music model
27th January 2023
Google Research just released MusicLM: Generating Music From Text. It’s a new generative AI model that takes a descriptive prompt and produces a “high-fidelity” music track. Here’s the paper (and a more readable version using arXiv Vanity).
There’s no interactive demo yet, but there are dozens of examples on the site. The prompts are things like this:
A fusion of reggaeton and electronic dance music, with a spacey, otherworldly sound. Induces the experience of being lost in space, and the music would be designed to evoke a sense of wonder and awe, while being danceable.
Included are examples of opera, jazz, peruvian punk, berlin 90s house and many more. It’s a really fun page to explore.
The MusicCaps dataset
The paper abstract includes this line:
To support future research, we publicly release MusicCaps, a dataset composed of 5.5k music-text pairs, with rich text descriptions provided by human experts.
Later in the paper they provide a little more detail:
To evaluate MusicLM, we prepare MusicCaps, a high-quality music caption dataset, which we make publicly available. This dataset includes 5.5k music clips from AudioSet (Gemmeke et al., 2017), each paired with corresponding text descriptions in English, written by ten professional musicians. For each 10-second music clip, MusicCaps provides: (1) a free-text caption consisting of four sentences on average, describing the music and (2) a list of music aspects, describing genre, mood, tempo, singer voices, instrumentation, dissonances, rhythm, etc. On average, the dataset includes eleven aspects per clip.
Here’s where they published that data on Kaggle.
I love digging into these training datasets—and this one is pretty tiny. I decided to take a look and see what I could learn.
I built musiccaps.datasette.io to support exploring and searching the data.
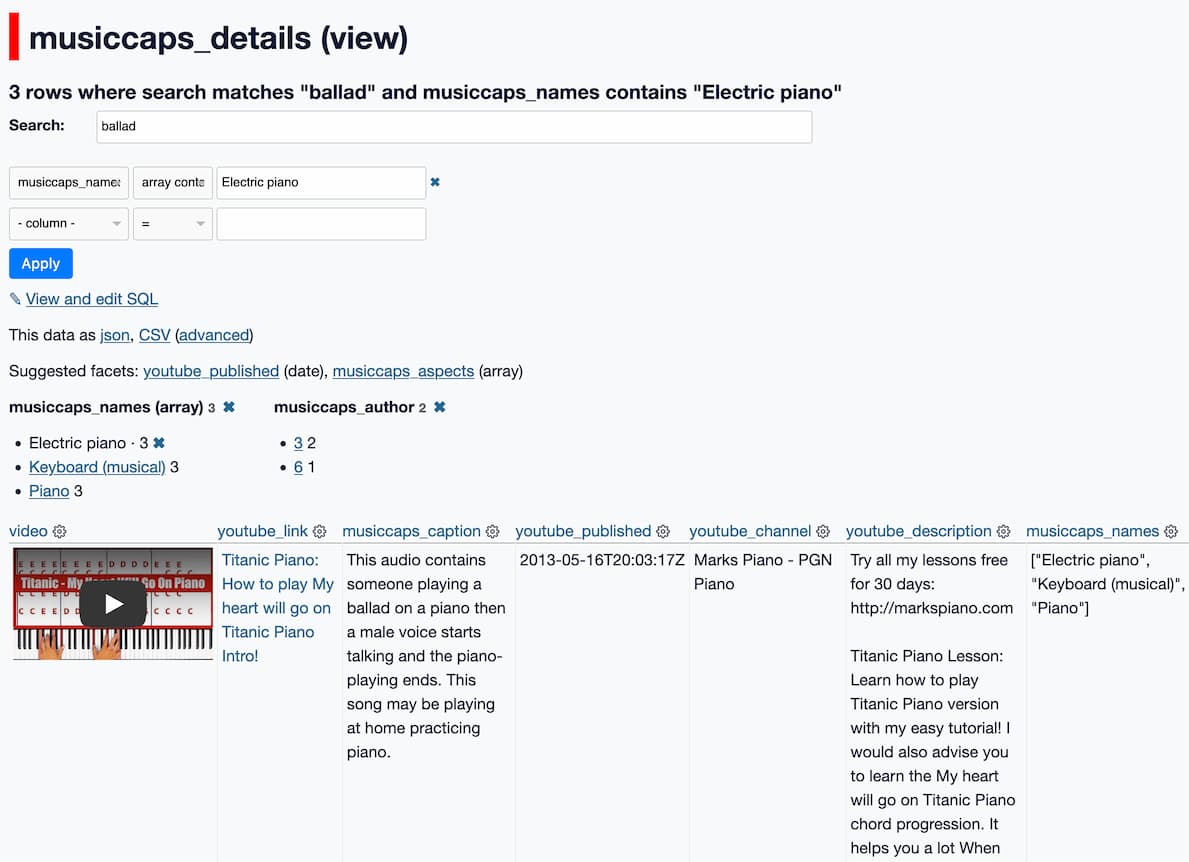
The dataset itself turns out to not have any audio clips in it at all—instead, each row of the data includes a YouTube video ID and a start and end time for a clip within it.
This is similar to how the LAION dataset used for Stable Diffusion works—that dataset contains URLs to images, but not the images themselves.
A YouTube video ID is just a string like zYM0gtd_PRo—the dataset has no further information.
But... information on those videos is available via the YouTube API. So I fetched back full details of all 5,500 videos and included them in the database as well.
This means we can start answering all sorts of interesting questions:
- Which YouTube channels are most represented in the dataset?—the answer is ProGuitarShopDemos with 12, Berliner Philharmoniker with 8, Prymaxe with 8—generally it’s a pretty wide distribution though, with 5,163 channels represented.
- How many videos are no longer on YouTube?—18 of the videos referenced in the dataset no longer exist according to the YouTube API.
- How many videos include the magic YouTube description phrase “No copyright infringement intended”?—31 of them do. See No Copyright Intended by Andy Baio for background on this superstition.
The search feature is configured to run against the human-written descriptions provided as the key feature of the MusicCaps dataset—try some searches like opera, ballad, guitar, or whimsical.
How I built this
The dataset is available on Kaggle, but since it’s licensed CC BY-SA 4.0 I grabbed a copy of it and dropped the CSV into this GitHub repo.
You can explore that using Datasette Lite at this URL:
This was a decent starting point, but it felt really important to be able to click “play” and listen to that audio.
I built a new Datasette plugin for this: datasette-youtube-embed.
The plugin works by looking out for YouTube URLs of the following format:
https://www.youtube.com/watch?v=-U16iKiXGuYhttps://www.youtube.com/watch?v=-U16iKiXGuY&start=30https://www.youtube.com/watch?v=-U16iKiXGuY&start=30&end=40
If it finds one of those, it replaces it with a YouTube embed that passes through the start and end parameters, if present.
This means it can play the exact clip that was referenced by the MusicCaps dataset.
My first attempt at this plugin used regular YouTube embeds, but Datasette defaults to returning up to 100 rows on a page, and 100 YouTube iframe embeds is pretty heavy!
Instead, I switched the plugin to use the Lite YouTube Embed Web Component by Paul Irish.
Sadly this means the plugin doesn’t work with Datasette Lite, so I switched to deploying a full Datasette instance to Vercel instead.
Adding video details from the YouTube API
I wanted to add more context about each of the videos. The YouTube Data API has a videos endpoint which accepts a comma-separated list of video IDs (up to 50 at a time, not mentioned in the documentation) and returns details about each video.
After some experimentation, this turned out to be the recipe that gave me the key data I wanted:
https://www.googleapis.com/youtube/v3/videos
?part=snippet,statistics
&id=video_id1,video_id2,video_id3
&key=youtube-api-key
I built a Jupyter notebook that batched up all of the IDs into groups of 50, fetched the data and wrote it into my SQLite database using sqlite-utils.
The audioset_positive_labels column in the initial CSV had values like /m/0140xf,/m/02cjck,/m/04rlf—these turned out to be match IDs in this CSV file of AudioSet categories in the tensorflow/models GitHub repo, so I fetched and transformed those as well.
I had to do a little bit of extra cleanup to get everything working how I wanted. The final result was two tables, with the following schema:
CREATE TABLE [musiccaps] (
[ytid] TEXT PRIMARY KEY,
[url] TEXT,
[caption] TEXT,
[aspect_list] TEXT,
[audioset_names] TEXT,
[author_id] TEXT,
[start_s] TEXT,
[end_s] TEXT,
[is_balanced_subset] INTEGER,
[is_audioset_eval] INTEGER,
[audioset_ids] TEXT
);
CREATE TABLE [videos] (
[id] TEXT PRIMARY KEY,
[publishedAt] TEXT,
[channelId] TEXT,
[title] TEXT,
[description] TEXT,
[thumbnails] TEXT,
[channelTitle] TEXT,
[tags] TEXT,
[categoryId] TEXT,
[liveBroadcastContent] TEXT,
[localized] TEXT,
[viewCount] INTEGER,
[likeCount] INTEGER,
[favoriteCount] INTEGER,
[commentCount] INTEGER,
[defaultAudioLanguage] TEXT,
[defaultLanguage] TEXT
);I configured SQLite full-text search against the musiccaps.caption column.
The last step was to create a SQL view that combined the key data from the two tables. After some more iteration I came up with this one:
CREATE VIEW musiccaps_details AS select
musiccaps.url as video,
json_object(
'label',
coalesce(videos.title, 'Missing from YouTube'),
'href',
musiccaps.url
) as youtube_link,
musiccaps.caption as musiccaps_caption,
videos.publishedAt as youtube_published,
videos.channelTitle as youtube_channel,
videos.description as youtube_description,
musiccaps.audioset_names as musiccaps_names,
musiccaps.aspect_list as musiccaps_aspects,
musiccaps.author_id as musiccaps_author,
videos.id as youtube_id,
musiccaps.rowid as musiccaps_rowid
from
musiccaps
left join videos on musiccaps.ytid = videos.id;I built a custom template for the instance homepage to add a search box, then shipped the whole thing to Vercel using the datasette-publish-vercel plugin.
Let me know what you find
Digging around in this data is a lot of fun. I’d love to hear what you find. Hit me up on Mastodon if you find anything interesting!
More recent articles
- Is Claude Code going to cost $100/month? Probably not - it's all very confusing - 22nd April 2026
- Where's the raccoon with the ham radio? (ChatGPT Images 2.0) - 21st April 2026
- Changes in the system prompt between Claude Opus 4.6 and 4.7 - 18th April 2026