December 2024
136 posts: 12 entries, 62 links, 26 quotes, 36 beats
Dec. 25, 2024
deepseek-ai/DeepSeek-V3-Base (via) No model card or announcement yet, but this new model release from Chinese AI lab DeepSeek (an arm of Chinese hedge fund High-Flyer) looks very significant.
It's a huge model - 685B parameters, 687.9 GB on disk (TIL how to size a git-lfs repo). The architecture is a Mixture of Experts with 256 experts, using 8 per token.
For comparison, Meta AI's largest released model is their Llama 3.1 model with 405B parameters.
The new model is apparently available to some people via both chat.deepseek.com and the DeepSeek API as part of a staged rollout.
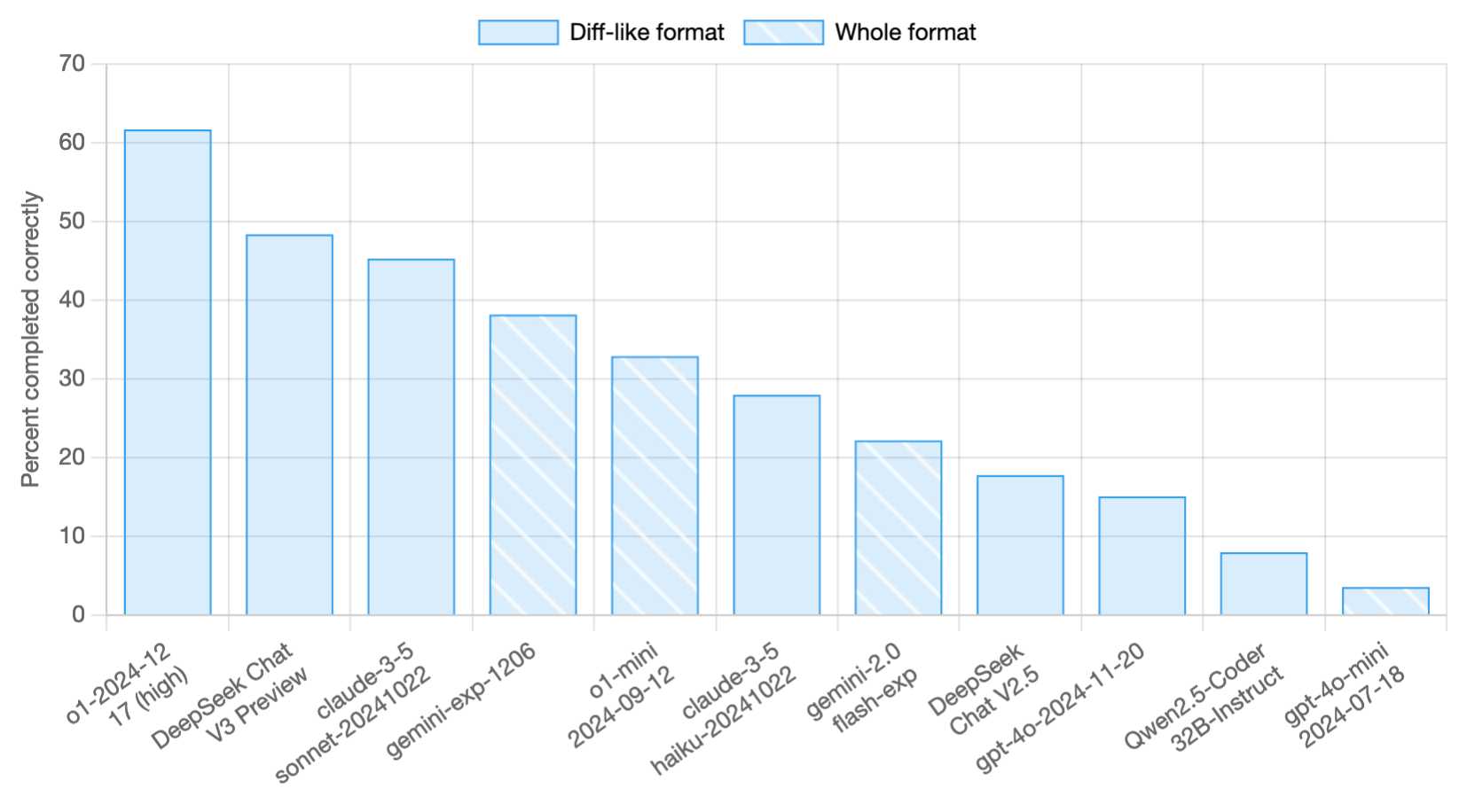
Paul Gauthier got API access and used it to update his new Aider Polyglot leaderboard - DeepSeek v3 preview scored 48.4%, putting it in second place behind o1-2024-12-17 (high) and in front of both claude-3-5-sonnet-20241022 and gemini-exp-1206!
I never know if I can believe models or not (the first time I asked "what model are you?" it claimed to be "based on OpenAI's GPT-4 architecture"), but I just got this result using LLM and the llm-deepseek plugin:
llm -m deepseek-chat 'what deepseek model are you?'
I'm DeepSeek-V3 created exclusively by DeepSeek. I'm an AI assistant, and I'm at your service! Feel free to ask me anything you'd like. I'll do my best to assist you.
Here's my initial experiment log.
Dec. 26, 2024
Cognitive load is what matters (via) Excellent living document (the underlying repo has 625 commits since being created in May 2023) maintained by Artem Zakirullin about minimizing the cognitive load needed to understand and maintain software.
This all rings very true to me. I judge the quality of a piece of code by how easy it is to change, and anything that causes me to take on more cognitive load - unraveling a class hierarchy, reading though dozens of tiny methods - reduces the quality of the code by that metric.
Lots of accumulated snippets of wisdom in this one.
Mantras like "methods should be shorter than 15 lines of code" or "classes should be small" turned out to be somewhat wrong.
Providers and deployers of AI systems shall take measures to ensure, to their best extent, a sufficient level of AI literacy of their staff and other persons dealing with the operation and use of AI systems on their behalf, taking into account their technical knowledge, experience, education and training and the context the AI systems are to be used in, and considering the persons or groups of persons on whom the AI systems are to be used.
— EU Artificial Intelligence Act, Article 4: AI literacy
DeepSeek_V3.pdf (via) The DeepSeek v3 paper (and model card) are out, after yesterday's mysterious release of the undocumented model weights.
Plenty of interesting details in here. The model pre-trained on 14.8 trillion "high-quality and diverse tokens" (not otherwise documented).
Following this, we conduct post-training, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the base model of DeepSeek-V3, to align it with human preferences and further unlock its potential. During the post-training stage, we distill the reasoning capability from the DeepSeek-R1 series of models, and meanwhile carefully maintain the balance between model accuracy and generation length.
By far the most interesting detail though is how much the training cost. DeepSeek v3 trained on 2,788,000 H800 GPU hours at an estimated cost of $5,576,000. For comparison, Meta AI's Llama 3.1 405B (smaller than DeepSeek v3's 685B parameters) trained on 11x that - 30,840,000 GPU hours, also on 15 trillion tokens.
DeepSeek v3 benchmarks comparably to Claude 3.5 Sonnet, indicating that it's now possible to train a frontier-class model (at least for the 2024 version of the frontier) for less than $6 million!
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being brought up today are more around 100K GPUs. E.g. Llama 3 405B used 30.8M GPU-hours, while DeepSeek-V3 looks to be a stronger model at only 2.8M GPU-hours (~11X less compute). If the model also passes vibe checks (e.g. LLM arena rankings are ongoing, my few quick tests went well so far) it will be a highly impressive display of research and engineering under resource constraints.
DeepSeek also announced their API pricing. From February 8th onwards:
Input: $0.27/million tokens ($0.07/million tokens with cache hits)
Output: $1.10/million tokens
Claude 3.5 Sonnet is currently $3/million for input and $15/million for output, so if the models are indeed of equivalent quality this is a dramatic new twist in the ongoing LLM pricing wars.
Dec. 27, 2024
Open WebUI. I tried out this open source (MIT licensed, JavaScript and Python) localhost UI for accessing LLMs today for the first time. It's very nicely done.
I ran it with uvx like this:
uvx --python 3.11 open-webui serve
On first launch it installed a bunch of dependencies and then downloaded 903MB to ~/.cache/huggingface/hub/models--sentence-transformers--all-MiniLM-L6-v2 - a copy of the all-MiniLM-L6-v2 embedding model, presumably for its RAG feature.
It then presented me with a working Llama 3.2:3b chat interface, which surprised me because I hadn't spotted it downloading that model. It turns out that was because I have Ollama running on my laptop already (with several models, including Llama 3.2:3b, already installed) - and Open WebUI automatically detected Ollama and gave me access to a list of available models.
I found a "knowledge" section and added all of the Datasette documentation (by dropping in the .rst files from the docs) - and now I can type # in chat to search for a file, add that to the context and then ask questions about it directly.
I selected the spatialite.rst.txt file, prompted it with "How do I use SpatiaLite with Datasette" and got back this:
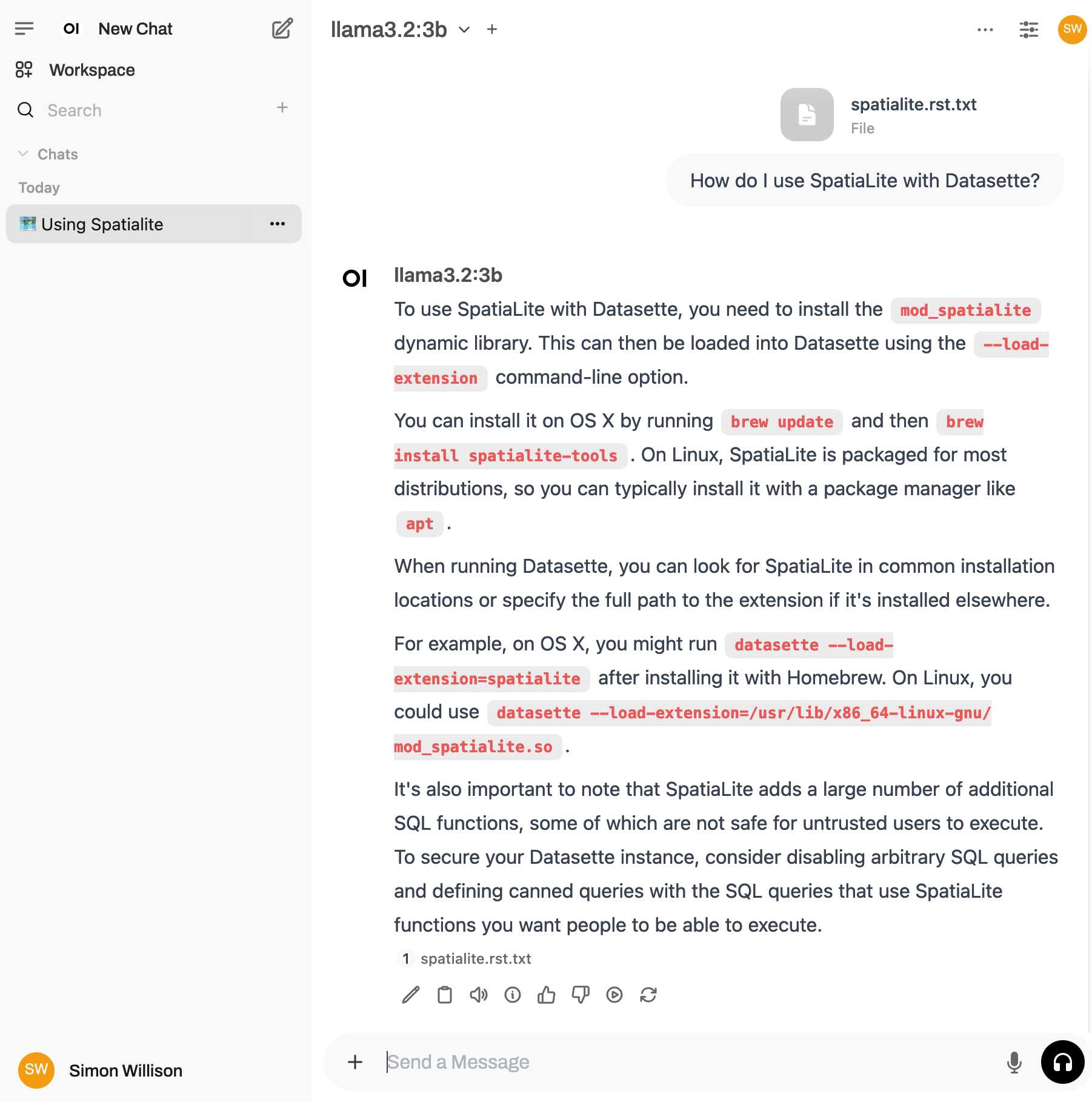
That's honestly a very solid answer, especially considering the Llama 3.2 3B model from Ollama is just a 1.9GB file! It's impressive how well that model can handle basic Q&A and summarization against text provided to it - it somehow has a 128,000 token context size.
Open WebUI has a lot of other tricks up its sleeve: it can talk to API models such as OpenAI directly, has optional integrations with web search and custom tools and logs every interaction to a SQLite database. It also comes with extensive documentation.
Dec. 28, 2024
Looking back, it's clear we overcomplicated things. While embeddings fundamentally changed how we can represent and compare content, they didn't need an entirely new infrastructure category. What we label as "vector databases" are, in reality, search engines with vector capabilities. The market is already correcting this categorization—vector search providers rapidly add traditional search features while established search engines incorporate vector search capabilities. This category convergence isn't surprising: building a good retrieval engine has always been about combining multiple retrieval and ranking strategies. Vector search is just another powerful tool in that toolbox, not a category of its own.
My Approach to Building Large Technical Projects (via) Mitchell Hashimoto wrote this piece about taking on large projects back in June 2023. The project he described in the post is a terminal emulator written in Zig called Ghostty which just reached its 1.0 release.
I've learned that when I break down my large tasks in chunks that result in seeing tangible forward progress, I tend to finish my work and retain my excitement throughout the project. People are all motivated and driven in different ways, so this may not work for you, but as a broad generalization I've not found an engineer who doesn't get excited by a good demo. And the goal is to always give yourself a good demo.
For backend-heavy projects the lack of an initial UI is a challenge here, so Mitchell advocates for early automated tests as a way to start exercising code and seeing progress right from the start. Don't let tests get in the way of demos though:
No matter what I'm working on, I try to build one or two demos per week intermixed with automated test feedback as explained in the previous section.
Building a demo also provides you with invaluable product feedback. You can quickly intuit whether something feels good, even if it isn't fully functional.
For more on the development of Ghostty see this talk Mitchell gave at Zig Showtime last year:
I want the terminal to be a modern platform for text application development, analogous to the browser being a modern platform for GUI application development (for better or worse).
Dec. 29, 2024
Google search hallucinates Encanto 2. Jason Schreier on Bluesky:
I was excited to tell my kids that there's a sequel to Encanto, only to scroll down and learn that Google's AI just completely made this up
I just replicated the same result by searching Google for encanto 2. Here's what the "AI overview" at the top of the page looked like:
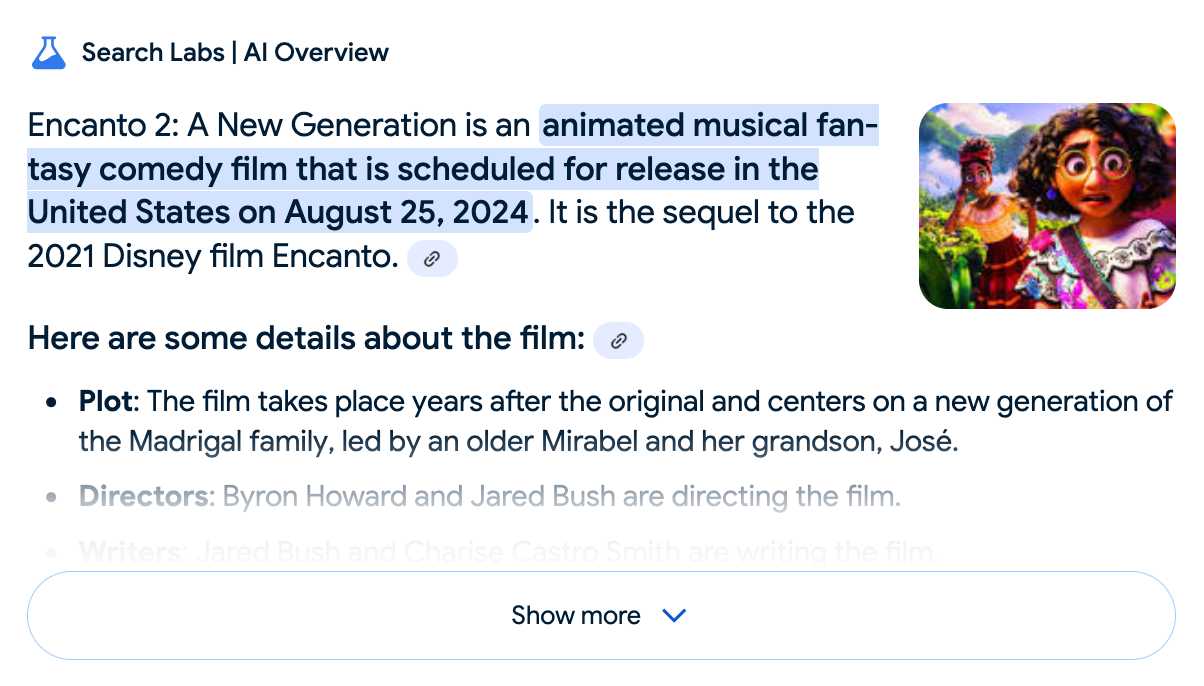
Only when I clicked the "Show more" link did it become clear what had happened:

The link in that first snippet was to the Encanto 2: A New Generation page on Idea Wiki:
This is a fanon wiki, and just like fan-fiction wikis, this one has a variety of fan created ideas on here! These include potential sequels and new series that have yet to exist.
Other cited links included this article about Instagram fan art and Encanto's Sequel Chances Addressed by Disney Director, a very thin article built around a short quote from Encanto's director at D23 Brazil.
And that August 2024 release date (which the AI summary weirdly lists as "scheduled for release" despite that date being five months in the past)? It's from the Idea Wiki imaginary info box for the film.
This is a particularly clear example of how badly wrong AI summarization can go. LLMs are gullible: they believe what you tell them, and the web is full of misleading information - some of which is completely innocent.
Update: I've had some pushback over my use of the term "hallucination" here, on the basis that the LLM itself is doing what it's meant to: summarizing the RAG content that has been provided to it by the host system.
That's fair: this is not a classic LLM hallucination, where the LLM produces incorrect data purely from knowledge partially encoded in its weights.
I classify this as a bug in Google's larger LLM-powered AI overview system. That system should be able to take the existence of invalid data sources into account - given how common searches for non-existent movie sequels (or TV seasons) are, I would hope that AI overviews could classify such searches and take extra steps to avoid serving misleading answers.
So think this is a "hallucination" bug in the AI overview system itself: it's making statements about the world that are not true.
How we think about Threads’ iOS performance (via) This article by Dave LaMacchia and Jason Patterson provides an incredibly deep insight into what effective performance engineering looks like for an app with 100s of millions of users.
I always like hearing about custom performance metrics with their own acronyms. Here we are introduced to %FIRE - the portion of people who experience a frustrating image-render experience (based on how long an image takes to load after the user scrolls it into the viewport), TTNC (time-to-network content) measuring time from app launch to fresh content visible in the feed and cPSR (creation-publish success rate) for how often a user manages to post content that they started to create.
This article introduced me to the concept of a boundary test, described like this:
A boundary test is one where we measure extreme ends of a boundary to learn what the effect is. In our case, we introduced a slight bit of latency when a small percentage of our users would navigate to a user profile, to the conversion view for a post, or to their activity feed.
This latency would allow us to extrapolate what the effect would be if we similarly improved how we delivered content to those views.
[...]
We learned that iOS users don’t tolerate a lot of latency. The more we added, the less often they would launch the app and the less time they would stay in it. With the smallest latency injection, the impact was small or negligible for some views, but the largest injections had negative effects across the board. People would read fewer posts, post less often themselves, and in general interact less with the app. Remember, we weren’t injecting latency into the core feed, either; just into the profile, permalink, and activity.
There's a whole lot more in there, including details of their custom internal performance logger (SLATE, the “Systemic LATEncy” logger) and several case studies of surprising performance improvements made with the assistance of their metrics and tools, plus some closing notes on how Swift concurrency is being adopted throughout Meta.
What's holding back research isn't a lack of verbose, low-signal, high-noise papers. Using LLMs to automatically generate 100x more of those will not accelerate science, it will slow it down.
— François Chollet, 12th May 2024
Dec. 30, 2024
There is no technical moat in this field, and so OpenAI is the epicenter of an investment bubble.
Thus, effectively, OpenAI is to this decade’s generative-AI revolution what Netscape was to the 1990s’ internet revolution. The revolution is real, but it’s ultimately going to be a commodity technology layer, not the foundation of a defensible proprietary moat. In 1995 investors mistakenly thought investing in Netscape was a good way to bet on the future of the open internet and the World Wide Web in particular. Investing in OpenAI today is a bit like that — generative AI technology has a bright future and is transforming the world, but it’s wishful thinking that the breakthrough client implementation is going to form the basis of a lasting industry titan.
Severance on FanFare. I'm coordinating a rewatch of season one of Severance on MetaFilter Fanfare in preparation for season two (due to start on January 17th). I'm posting an episode every three days - we are up to episode 5 so far (excellently titled "The Grim Barbarics of Optics and Design").
Severance is a show that rewatches really well. There are so many delightful details that stand out once you know more about where the series is going.
Dec. 31, 2024
Basically, a frontier model like OpenAI’s O1 is like a Ferrari SF-23. It’s an obvious triumph of engineering, designed to win races, and that’s why we talk about it. But it takes a special pit crew just to change the tires and you can’t buy one for yourself. In contrast, a BERT model is like a Honda Civic. It’s also an engineering triumph, but more subtly, since it is engineered to be affordable, fuel-efficient, reliable, and extremely useful. And that’s why they’re absolutely everywhere.
Things we learned about LLMs in 2024
A lot has happened in the world of Large Language Models over the course of 2024. Here’s a review of things we figured out about the field in the past twelve months, plus my attempt at identifying key themes and pivotal moments.
[... 7,490 words]Timeline of AI model releases in 2024 (via) VB assembled this detailed timeline of every significant AI model release in 2024, for both API and open weight models.
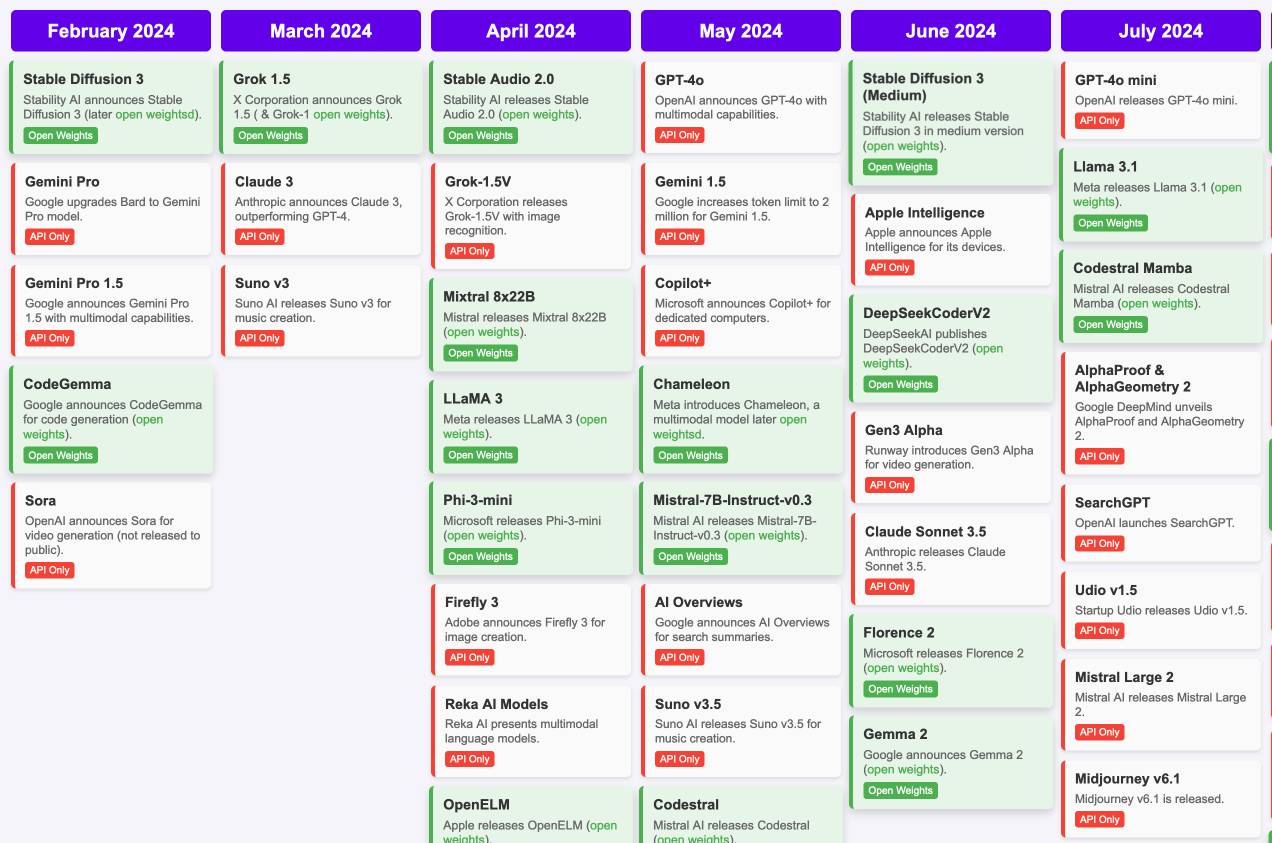
I'd hoped to include something like this in my 2024 review - I'm glad I didn't bother, because VB's is way better than anything I had planned.
VB built it with assistance from DeepSeek v3, incorporating data from this Artificial Intelligence Timeline project by NHLOCAL. The source code (pleasingly simple HTML, CSS and a tiny bit of JavaScript) is on GitHub.