July 2024
141 posts: 4 entries, 81 links, 35 quotes, 1 note, 20 beats
July 28, 2024
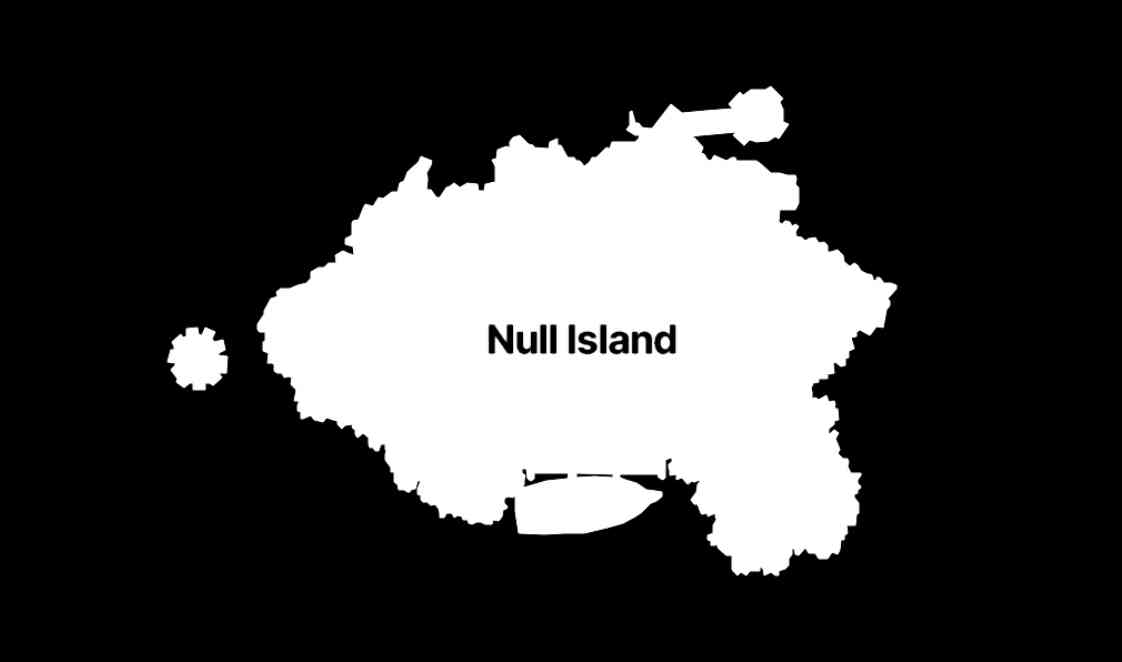
The many lives of Null Island (via) Stamen's custom basemaps have long harbored an Easter egg: zoom all the way in on 0, 0 to see the outline of the mystical "null island", the place where GIS glitches and data bugs accumulate, in the Gulf of Guinea south of Ghana.
Stamen's Alan McConchie provides a detailed history of the Easter egg - first introduced by Mike Migurski in 2010 - along with a definitive guide to the GIS jokes and traditions that surround it.
Here's Null Island on Stamen's Toner map. The shape (also available as GeoJSON) is an homage to the island from 1993's Myst, hence the outline of a large docked ship at the bottom.
Alan recently gave a talk about Stamen's updated custom maps at State of the Map US 2024 (video, slides) - their Toner and Terrain maps are now available as vector tiles served by Stadia Maps (here's the announcement), but their iconic watercolor style is yet to be updated to vectors, due to the weird array of raster tricks it used to achieve the effect.
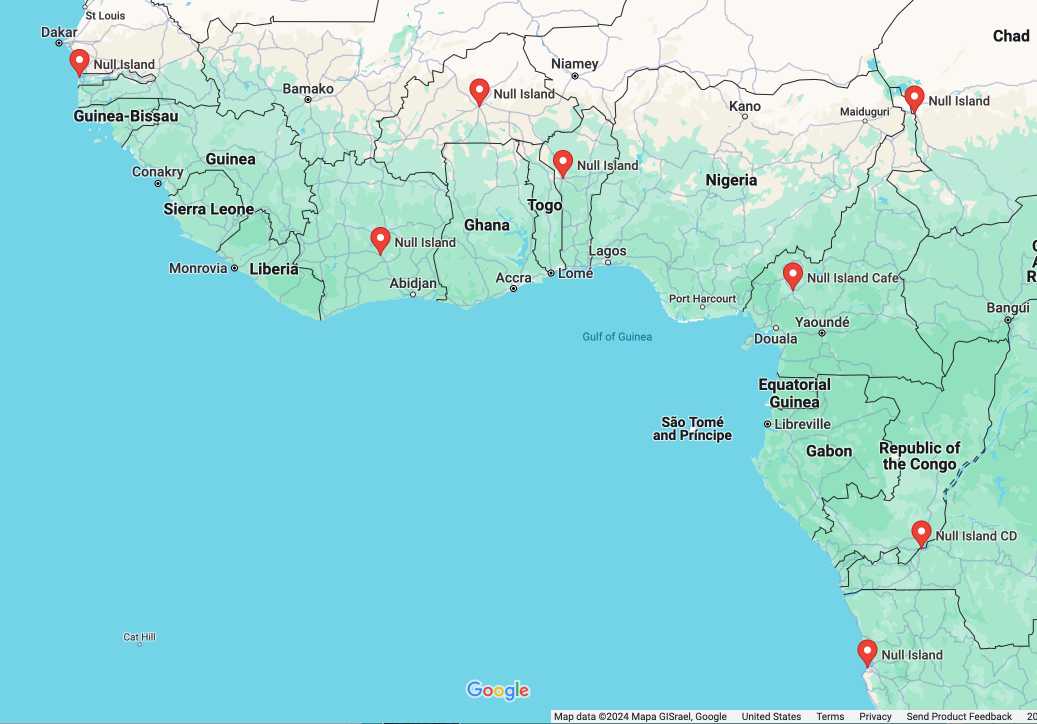
In researching this post I searched for null island on Google Maps and was delighted to learn that a bunch of entrepreneurs in Western Africa have tapped into the meme for their own businesses:
The rich history of ham radio culture (via) This long excerpt from Kristen Haring's 2008 book Ham Radio's Technical Culture filled in so many gaps for me. I'm ham licensed in the USA (see my recent notes on passing the general exam) but prior to reading this I hadn't appreciated quite how much the 100+ year history of the hobby explains the way it works today. Some ham abbreviations derive from the Phillips Code created in 1879!
The Hacker News thread attracted some delightful personal stories from older ham operators: "my exposure to ham radio really started in the 1970s...". I also liked this description of the core of the hobby:
A ham radio license is permission from your country's government to get on the air for the sake of playing with radio waves and communicating with other hams locally or around the globe without any further agenda.
I'm increasingly using the Listen to Page feature in my iPhone's Mobile Safari to read long-form articles like this one, which means I can do household chores at the same time.
July 29, 2024
Everlasting jobstoppers: How an AI bot-war destroyed the online job market (via) This story by Joe Tauke highlights several unpleasant trends from the online job directory space at the moment.
The first is "ghost jobs" - job listings that company put out which don't actually correspond to an open role. A survey found that this is done for a few reasons: to keep harvesting resumes for future reference, to imply that the company is successful, and then:
Perhaps the most infuriating replies came in at 39% and 33%, respectively: “The job was filled” (but the post was left online anyway to keep gathering résumés), and “No reason in particular.”
That’s right, all you go-getters out there: When you scream your 87th cover letter into the ghost-job void, there’s a one in three chance that your time was wasted for “no reason in particular.”
Another trend is "job post scraping". Plenty of job listings sites are supported by advertising, so the more content they can gather the better. This has lead to an explosion of web scraping, resulting in vast tracts of listings that were copied from other sites and likely to be out-of-date or no longer correspond to open positions.
Most worrying of all: scams.
With so much automation available, it’s become easier than ever for identity thieves to flood the employment market with their own versions of ghost jobs — not to make a real company seem like it’s growing or to make real employees feel like they’re under constant threat of being replaced, but to get practically all the personal information a victim could ever provide.
I'm not 100% convinced by the "AI bot-war" component of this headline though. The article later notes that the "ghost jobs" report it quotes was written before ChatGPT's launch in November 2022. The story ends with a flurry of examples of new AI-driven tools for both applicants and recruiters, and I've certainly heard anecdotes of LinkedIn spam that clearly has a flavour of ChatGPT to it, but I'm not convinced that the AI component is (yet) as frustration-inducing as the other patterns described above.
Dealing with your AI-obsessed co-worker (TikTok). The latest in Alberta 🤖 Tech's excellent series of skits:
You asked the CEO what he thinks of our project? Oh, you asked ChatGPT to pretend to be our CEO and then asked what he thought of our project. I don't think that counts.
The [Apple Foundation Model] pre-training dataset consists of a diverse and high quality data mixture. This includes data we have licensed from publishers, curated publicly-available or open-sourced datasets, and publicly available information crawled by our web-crawler, Applebot. We respect the right of webpages to opt out of being crawled by Applebot, using standard robots.txt directives.
Given our focus on protecting user privacy, we note that no private Apple user data is included in the data mixture. Additionally, extensive efforts have been made to exclude profanity, unsafe material, and personally identifiable information from publicly available data (see Section 7 for more details). Rigorous decontamination is also performed against many common evaluation benchmarks.
We find that data quality, much more so than quantity, is the key determining factor of downstream model performance.
SAM 2: The next generation of Meta Segment Anything Model for videos and images (via) Segment Anything is Meta AI's model for image segmentation: for any image or frame of video it can identify which shapes on the image represent different "objects" - things like vehicles, people, animals, tools and more.
SAM 2 "outperforms SAM on its 23 dataset zero-shot benchmark suite, while being six times faster". Notably, SAM 2 works with video where the original SAM only worked with still images. It's released under the Apache 2 license.
The best way to understand SAM 2 is to try it out. Meta have a web demo which worked for me in Chrome but not in Firefox. I uploaded a recent video of my brand new cactus tweezers (for removing detritus from my cacti without getting spiked) and selected the succulent and the tweezers as two different objects:
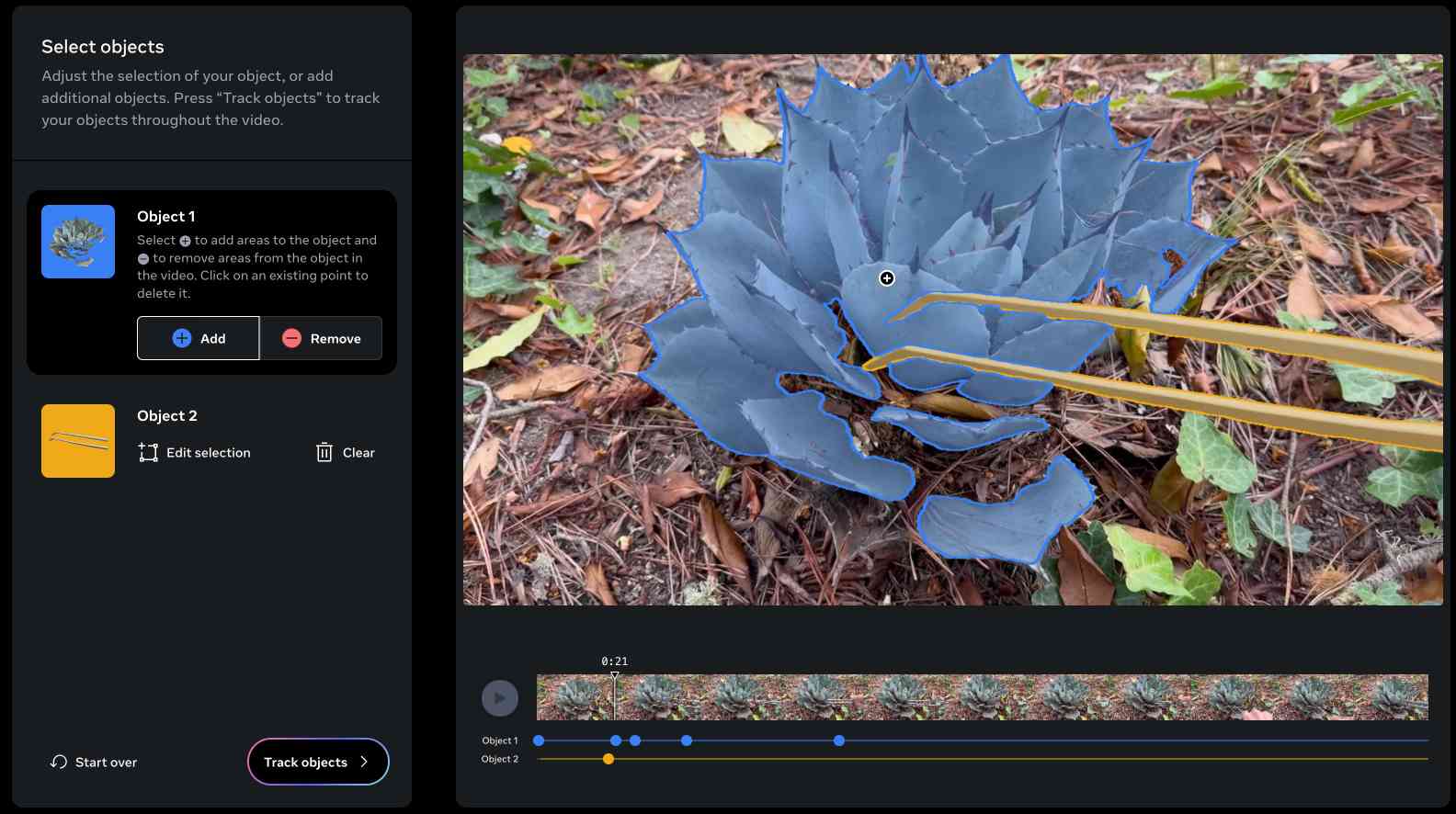
Then I applied a "desaturate" filter to the background and exported this resulting video, with the background converted to black and white while the succulent and tweezers remained in full colour:
Also released today: the full SAM 2 paper, the SA-V dataset of "51K diverse videos and 643K spatio-temporal segmentation masks" and a Dataset explorer tool (again, not supported by Firefox) for poking around in that collection.
July 30, 2024
Here Are All of the Apple Intelligence Features in the iOS 18.1 Developer Beta (via) Useful rundown from Juli Clover at MacRumors of the Apple Intelligence features that are available in the brand new iOS 18.1 beta, available to developer account holders with an iPhone 15 or iPhone 15 Pro Max or Apple Silicon iPad.
I've been trying this out today. It's still clearly very early, and the on-device model that powers Siri is significantly weaker than more powerful models that I've become used to over the past two years. Similar to old Siri I find myself trying to figure out the sparse, undocumented incantations that reliably work for the things I might want my voice assistant to do for me.
My early Siri AI experience has just underlined the fact that, while there is a lot of practical, useful things that can be done with small models, they really lack the horsepower to do anything super interesting.
AWS CodeCommit quietly deprecated (via) CodeCommit is AWS's Git hosting service. In a reply from an AWS employee to this forum thread:
Beginning on 06 June 2024, AWS CodeCommit ceased onboarding new customers. Going forward, only customers who have an existing repository in AWS CodeCommit will be able to create additional repositories.
[...] If you would like to use AWS CodeCommit in a new AWS account that is part of your AWS Organization, please let us know so that we can evaluate the request for allowlisting the new account. If you would like to use an alternative to AWS CodeCommit given this news, we recommend using GitLab, GitHub, or another third party source provider of your choice.
What's weird about this is that, as far as I can tell, this is the first official public acknowledgement from AWS that CodeCommit is no longer accepting customers. The CodeCommit landing page continues to promote the product, though it does link to the How to migrate your AWS CodeCommit repository to another Git provider blog post from July 25th, which gives no direct indication that CodeCommit is being quietly sunset.
I wonder how long they'll continue to support their existing customers?
Amazon QLDB too
It looks like AWS may be having a bit of a clear-out. Amazon QLDB - Quantum Ledger Database (a blockchain-adjacent immutable ledger, launched in 2019) - quietly put out a deprecation announcement in their release history on July 18th (again, no official announcement elsewhere):
End of support notice: Existing customers will be able to use Amazon QLDB until end of support on 07/31/2025. For more details, see Migrate an Amazon QLDB Ledger to Amazon Aurora PostgreSQL.
This one is more surprising, because migrating to a different Git host is massively less work than entirely re-writing a system to use a fundamentally different database.
It turns out there's an infrequently updated community GitHub repo called SummitRoute/aws_breaking_changes which tracks these kinds of changes. Other services listed there include CodeStar, Cloud9, CloudSearch, OpsWorks, Workdocs and Snowmobile, and they cleverly (ab)use the GitHub releases mechanism to provide an Atom feed.
What we got wrong about HTTP imports (via) HTTP imports are one of the most interesting design features of Deno:
import { assertEquals } from "https://deno.land/std@0.224.0/assert/mod.ts";
Six years after their introduction, Ryan Dahl reviews their disadvantages:
- Lengthy (non-memorable) URLs littering the codebase
- A slightly cumbersome
import { concat } from "../../deps.ts";pattern for managing dependencies in one place - Large projects can end up using multiple slightly different versions of the same dependencies
- If a website becomes unavailable, new builds will fail (existing builds will continue to use their cached version)
Deno 2 - due in September - will continue to support them, but will lean much more on the combination of import maps (design borrowed from modern browsers) and the Deno project's JSR npm competitor. An import map like this:
{
"imports": {
"@std/assert": "jsr:@std/assert@1"
}
}
Will then enable import statements that look like this:
import { assertEquals } from "@std/assert";
GPT-4o Long Output (via) "OpenAI is offering an experimental version of GPT-4o with a maximum of 64K output tokens per request."
It's a new model (for alpha testers only) called gpt-4o-64k-output-alpha that costs $6/million input tokens and $18/million output tokens.
That's a little bit more than GPT-4o ($5/$15) and a LOT more than GPT-4o mini ($0.15/$0.60).
Long output is primarily useful for data transformation use-cases - things like translating documents from one language into another, or extracting structured data from documents where almost every input token is needed in the output JSON.
Prior to this the longest output model I knew of was GPT-4o mini, at 16,000 tokens. Most of OpenAI's competitors still cap out at around 4,000 or 8,000.
Making Machines Move. Another deep technical dive into Fly.io infrastructure from Thomas Ptacek, this time describing how they can quickly boot up an instance with a persistent volume on a new host (for things like zero-downtime deploys) using a block-level cloning operation, so the new instance gets a volume that becomes accessible instantly, serving proxied blocks of data until the new volume has been completely migrated from the old host.
Ralph Sheldon’s Portrait of Henry VIII Reidentified (via) Here's a delightful two part story on art historian Adam Busiakiewicz's blog. Adam was browsing Twitter when he spotted this tweet by Tim Cox, Lord Lieutenant of Warwickshire, celebrating a reception.
He noticed a curve-framed painting mounted on a wall in the top left of the photo:

Adam had previously researched a similar painting while working at Sotheby's:
Seeing this round topped portrait immediately reminded me of a famous set of likenesses commissioned by the local politician and tapestry maker Ralph Sheldon (c. 1537--1613) for his home Weston House, Warwickshire, during the 1590s. Consisting of twenty-two portraits, mostly images of Kings, Queens and significant contemporary international figures, only a handful are known today.
Adam contacted Warwickshire County Council and was invited to Shire Hall. In his follow-up post he describes his first-hand observations from the visit.
It turns out the painting really was one of those 22 portraits made for tapestry maker Ralph Sheldon in the 1590s, long thought lost. The discovery has now made international news:
July 31, 2024
Aider. Aider is an impressive open source local coding chat assistant terminal application, developed by Paul Gauthier (founding CTO of Inktomi back in 1996-2000).
I tried it out today, using an Anthropic API key to run it using Claude 3.5 Sonnet:
pipx install aider-chat
export ANTHROPIC_API_KEY=api-key-here
aider --dark-mode
I found the --dark-mode flag necessary to make it legible using the macOS terminal "Pro" theme.
Aider starts by generating a concise map of files in your current Git repository. This is passed to the LLM along with the prompts that you type, and Aider can then request additional files be added to that context - or you can add the manually with the /add filename command.
It defaults to making modifications to files and then committing them directly to Git with a generated commit message. I found myself preferring the /ask command which lets you ask a question without making any file modifications:
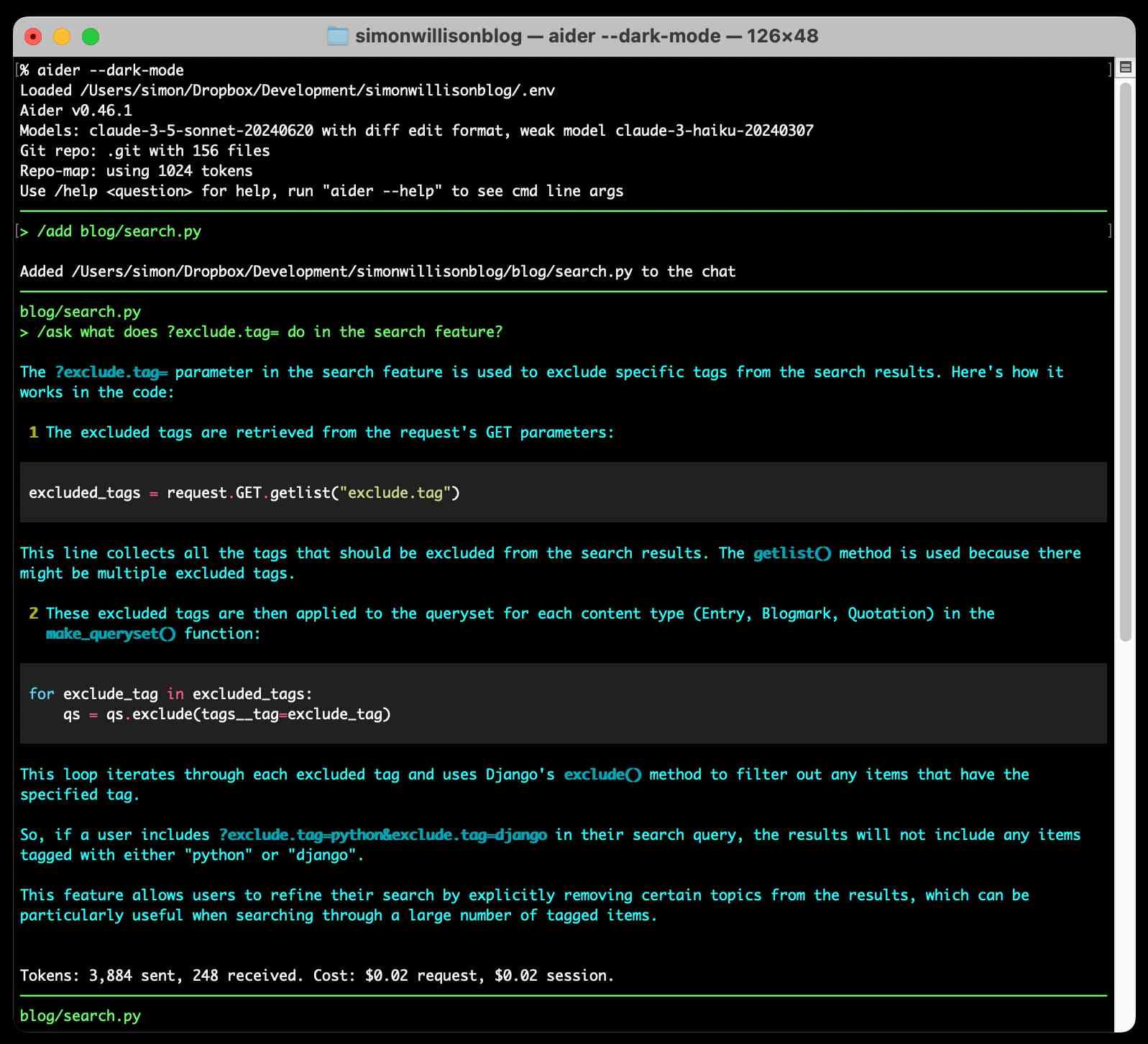
The Aider documentation includes extensive examples and the tool can work with a wide range of different LLMs, though it recommends GPT-4o, Claude 3.5 Sonnet (or 3 Opus) and DeepSeek Coder V2 for the best results. Aider maintains its own leaderboard, emphasizing that "Aider works best with LLMs which are good at editing code, not just good at writing code".
The prompts it uses are pretty fascinating - they're tucked away in various *_prompts.py files in aider/coders.
After giving it a lot of thought, we made the decision to discontinue new access to a small number of services, including AWS CodeCommit.
While we are no longer onboarding new customers to these services, there are no plans to change the features or experience you get today, including keeping them secure and reliable. [...]
The services I'm referring to are: S3 Select, CloudSearch, Cloud9, SimpleDB, Forecast, Data Pipeline, and CodeCommit.
This month in Servo: parallel tables and more (via) New in Servo:
Parallel table layout is now enabled (@mrobinson, #32477), spreading the work for laying out rows and their columns over all available CPU cores. This change is a great example of the strengths of Rayon and the opportunistic parallelism in Servo's layout engine.
The commit landing the change is quite short, and much of the work is done by refactoring the code to use .par_iter().enumerate().map(...) - par_iter() is the Rayon method that allows parallel iteration over a collection using multiple threads, hence multiple CPU cores.
Build your own SQS or Kafka with Postgres (via) Anthony Accomazzo works on Sequin, an open source "message stream" (similar to Kafka) written in Elixir and Go on top of PostgreSQL.
This detailed article describes how you can implement message queue patterns on PostgreSQL from scratch, including this neat example using a CTE, returning and for update skip locked to retrieve $1 messages from the messages table and simultaneously mark them with not_visible_until set to $2 in order to "lock" them for processing by a client:
with available_messages as (
select seq
from messages
where not_visible_until is null
or (not_visible_until <= now())
order by inserted_at
limit $1
for update skip locked
)
update messages m
set
not_visible_until = $2,
deliver_count = deliver_count + 1,
last_delivered_at = now(),
updated_at = now()
from available_messages am
where m.seq = am.seq
returning m.seq, m.data;
For the past 10 years or so, AWS has been rolling out these peripheral services at an astonishing rate, dozens every year. A few get traction, most don’t—but they all stick around, undead zombies behind impressive-looking marketing pages, because historically AWS just doesn’t make many breaking changes. [...]
AWS made this mess for themselves by rushing all sorts of half-baked services to market. The mess had to be cleaned up at some point, and they’re doing that. But now they’ve explicitly revealed something to customers: The new stuff we release isn’t guaranteed to stick around.