Thursday, 14th November 2024
Releasing the largest multilingual open pretraining dataset (via) Common Corpus is a new "open and permissible licensed text dataset, comprising over 2 trillion tokens (2,003,039,184,047 tokens)" released by French AI Lab PleIAs.
This appears to be the largest available corpus of openly licensed training data:
- 926,541,096,243 tokens of public domain books, newspapers, and Wikisource content
- 387,965,738,992 tokens of government financial and legal documents
- 334,658,896,533 tokens of open source code from GitHub
- 221,798,136,564 tokens of academic content from open science repositories
- 132,075,315,715 tokens from Wikipedia, YouTube Commons, StackExchange and other permissively licensed web sources
It's majority English but has significant portions in French and German, and some representation for Latin, Dutch, Italian, Polish, Greek and Portuguese.
I can't wait to try some LLMs trained exclusively on this data. Maybe we will finally get a GPT-4 class model that isn't trained on unlicensed copyrighted data.
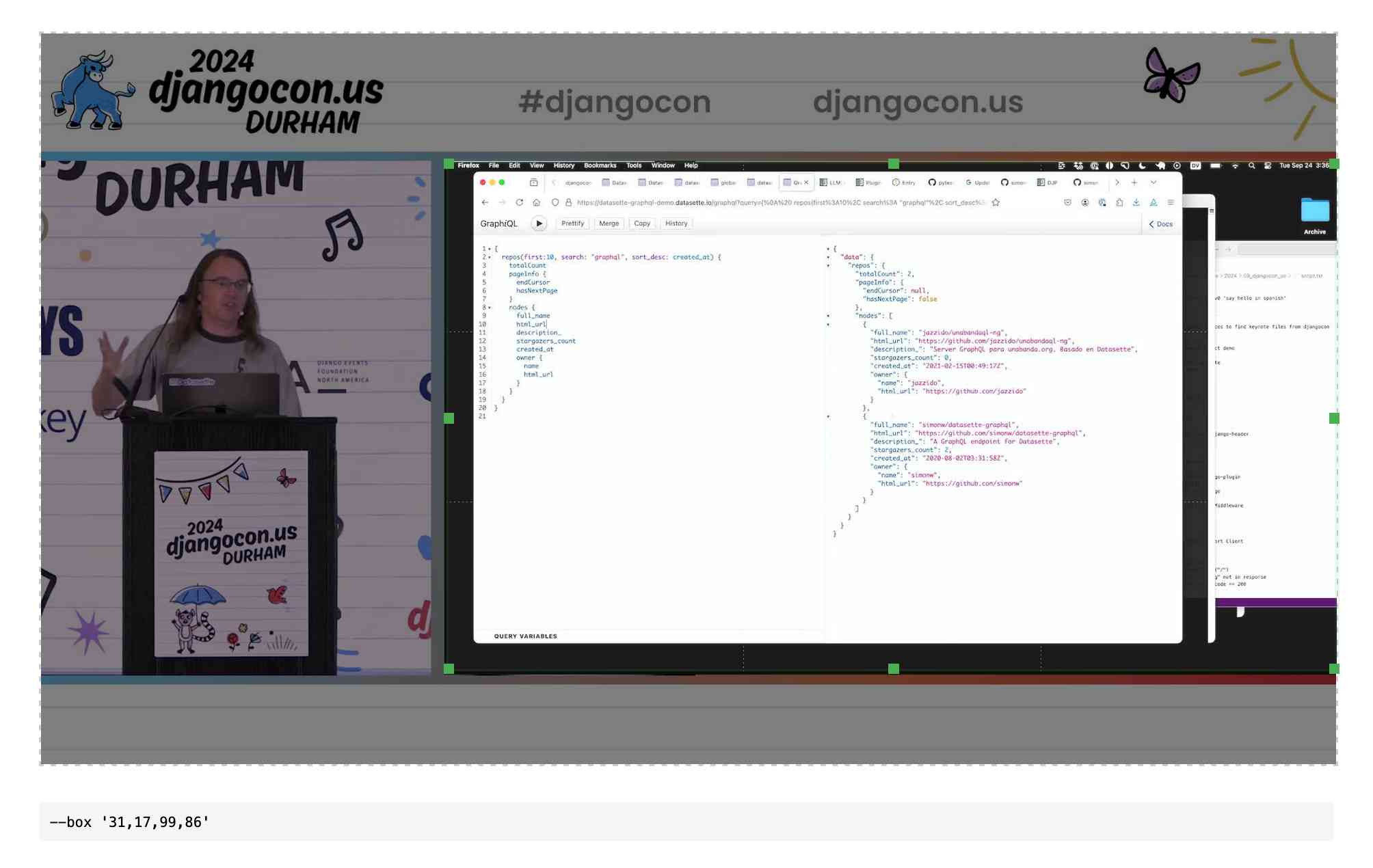
QuickTime video script to capture frames and bounding boxes. An update to an older TIL. I'm working on the write-up for my DjangoCon US talk on plugins and I found myself wanting to capture individual frames from the video in two formats: a full frame capture, and another that captured just the portion of the screen shared from my laptop.
I have a script for the former, so I got Claude to update my script to add support for one or more --box options, like this:
capture-bbox.sh ../output.mp4 --box '31,17,100,87' --box '0,0,50,50'
Open output.mp4 in QuickTime Player, run that script and then every time you hit a key in the terminal app it will capture three JPEGs from the current position in QuickTime Player - one for the whole screen and one each for the specified bounding box regions.
Those bounding box regions are percentages of the width and height of the image. I also got Claude to build me this interactive tool on top of cropperjs to help figure out those boxes:
PyPI now supports digital attestations (via) Dustin Ingram:
PyPI package maintainers can now publish signed digital attestations when publishing, in order to further increase trust in the supply-chain security of their projects. Additionally, a new API is available for consumers and installers to verify published attestations.
This has been in the works for a while, and is another component of PyPI's approach to supply chain security for Python packaging - see PEP 740 – Index support for digital attestations for all of the underlying details.
A key problem this solves is cryptographically linking packages published on PyPI to the exact source code that was used to build those packages. In the absence of this feature there are no guarantees that the .tar.gz or .whl file you download from PyPI hasn't been tampered with (to add malware, for example) in a way that's not visible in the published source code.
These new attestations provide a mechanism for proving that a known, trustworthy build system was used to generate and publish the package, starting with its source code on GitHub.
The good news is that if you're using the PyPI Trusted Publishers mechanism in GitHub Actions to publish packages, you're already using this new system. I wrote about that system in January: Publish Python packages to PyPI with a python-lib cookiecutter template and GitHub Actions - and hundreds of my own PyPI packages are already using that system, thanks to my various cookiecutter templates.
Trail of Bits helped build this feature, and provide extra background about it on their own blog in Attestations: A new generation of signatures on PyPI:
As of October 29, attestations are the default for anyone using Trusted Publishing via the PyPA publishing action for GitHub. That means roughly 20,000 packages can now attest to their provenance by default, with no changes needed.
They also built Are we PEP 740 yet? (key implementation here) to track the rollout of attestations across the 360 most downloaded packages from PyPI. It works by hitting URLs such as https://pypi.org/simple/pydantic/ with a Accept: application/vnd.pypi.simple.v1+json header - here's the JSON that returns.
I published an alpha package using Trusted Publishers last night and the files for that release are showing the new provenance information already:
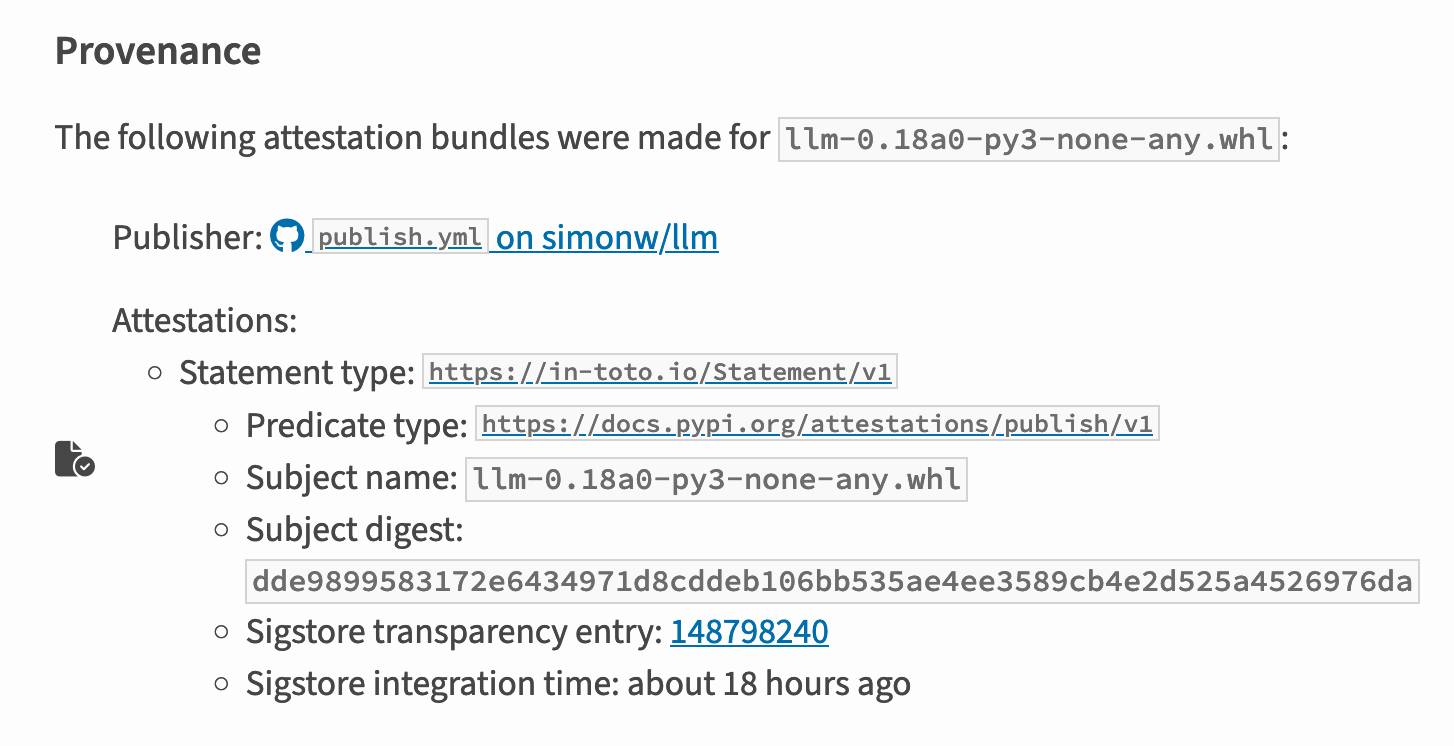
Which links to this Sigstore log entry with more details, including the Git hash that was used to build the package:
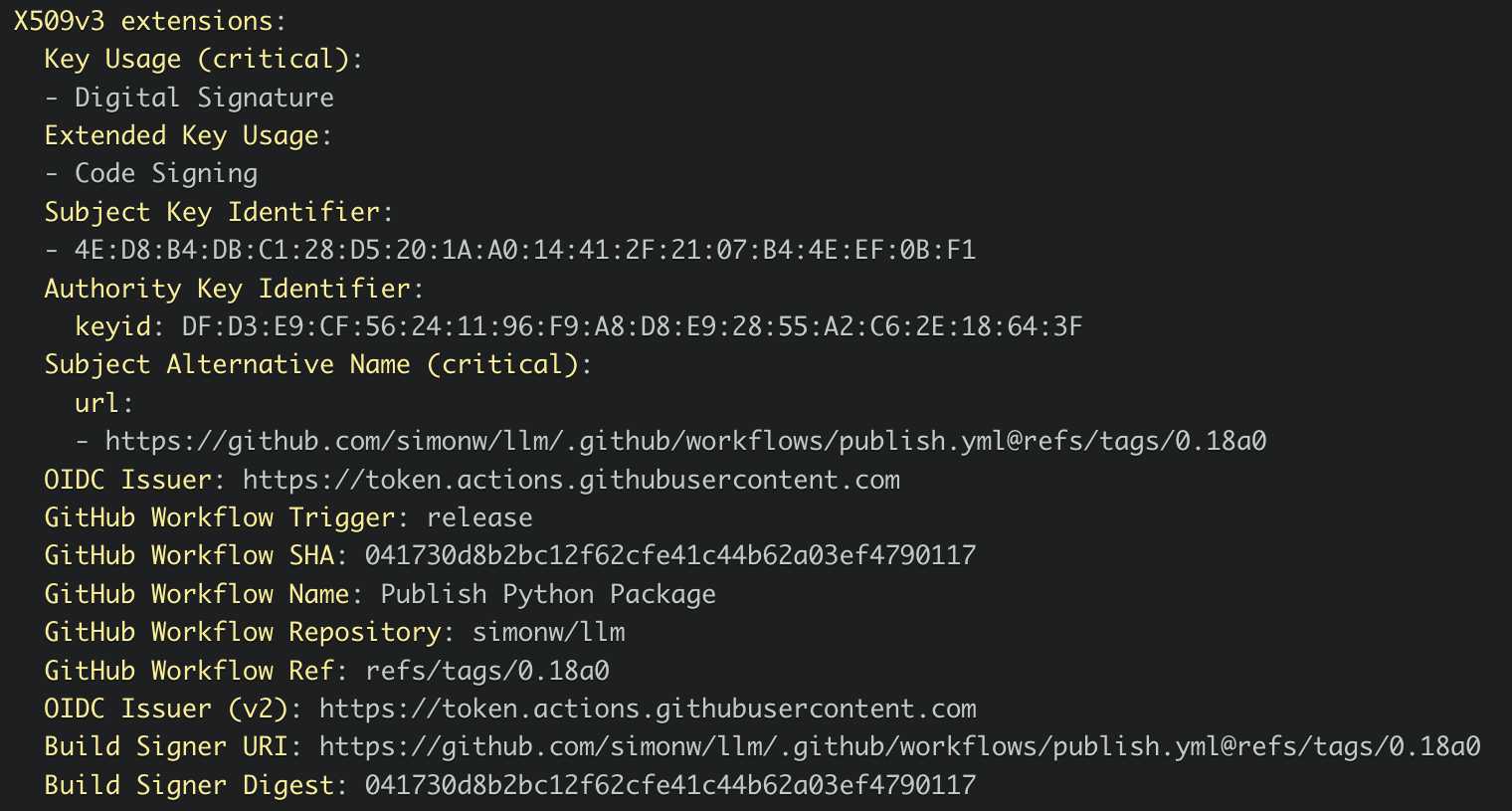
Sigstore is a transparency log maintained by Open Source Security Foundation (OpenSSF), a sub-project of the Linux Foundation.
Anthropic declined to comment, but referred Bloomberg News to a five-hour podcast featuring Chief Executive Officer Dario Amodei that was released Monday.
"People call them scaling laws. That's a misnomer," he said on the podcast. "They're not laws of the universe. They're empirical regularities. I am going to bet in favor of them continuing, but I'm not certain of that."
[...]
An Anthropic spokesperson said the language about Opus was removed from the website as part of a marketing decision to only show available and benchmarked models. Asked whether Opus 3.5 would still be coming out this year, the spokesperson pointed to Amodei’s podcast remarks. In the interview, the CEO said Anthropic still plans to release the model but repeatedly declined to commit to a timetable.
— OpenAI, Google and Anthropic Are Struggling to Build More Advanced AI, Rachel Metz, Shirin Ghaffary, Dina Bass, and Julia Love for Bloomberg
OpenAI Public Bug Bounty. Reading this investigation of the security boundaries of OpenAI's Code Interpreter environment helped me realize that the rules for OpenAI's public bug bounty inadvertently double as the missing details for a whole bunch of different aspects of their platform.
This description of Code Interpreter is significantly more useful than their official documentation!
Code execution from within our sandboxed Python code interpreter is out of scope. (This is an intended product feature.) When the model executes Python code it does so within a sandbox. If you think you've gotten RCE outside the sandbox, you must include the output of
uname -a. A result like the following indicates that you are inside the sandbox -- specifically note the 2016 kernel version:
Linux 9d23de67-3784-48f6-b935-4d224ed8f555 4.4.0 #1 SMP Sun Jan 10 15:06:54 PST 2016 x86_64 x86_64 x86_64 GNU/LinuxInside the sandbox you would also see
sandboxas the output ofwhoami, and as the only user in the output ofps.