Thursday, 10th October 2024
Announcing Deno 2. The big focus of Deno 2 is compatibility with the existing Node.js and npm ecosystem:
Deno 2 takes all of the features developers love about Deno 1.x — zero-config, all-in-one toolchain for JavaScript and TypeScript development, web standard API support, secure by default — and makes it fully backwards compatible with Node and npm (in ESM).
The npm support is documented here. You can write a script like this:
import * as emoji from "npm:node-emoji";
console.log(emoji.emojify(`:sauropod: :heart: npm`));And when you run it Deno will automatically fetch and cache the required dependencies:
deno run main.js
Another new feature that caught my eye was this:
deno jupyternow supports outputting images, graphs, and HTML
Deno has apparently shipped with a Jupyter notebook kernel for a while, and it's had a major upgrade in this release.
Here's Ryan Dahl's demo of the new notebook support in his Deno 2 release video.
I tried this out myself, and it's really neat. First you need to install the kernel:
deno juptyer --install
I was curious to find out what this actually did, so I dug around in the code and then further in the Rust runtimed dependency. It turns out installing Jupyter kernels, at least on macOS, involves creating a directory in ~/Library/Jupyter/kernels/deno and writing a kernel.json file containing the following:
{
"argv": [
"/opt/homebrew/bin/deno",
"jupyter",
"--kernel",
"--conn",
"{connection_file}"
],
"display_name": "Deno",
"language": "typescript"
}That file is picked up by any Jupyter servers running on your machine, and tells them to run deno jupyter --kernel ... to start a kernel.
I started Jupyter like this:
jupyter-notebook /tmp
Then started a new notebook, selected the Deno kernel and it worked as advertised:
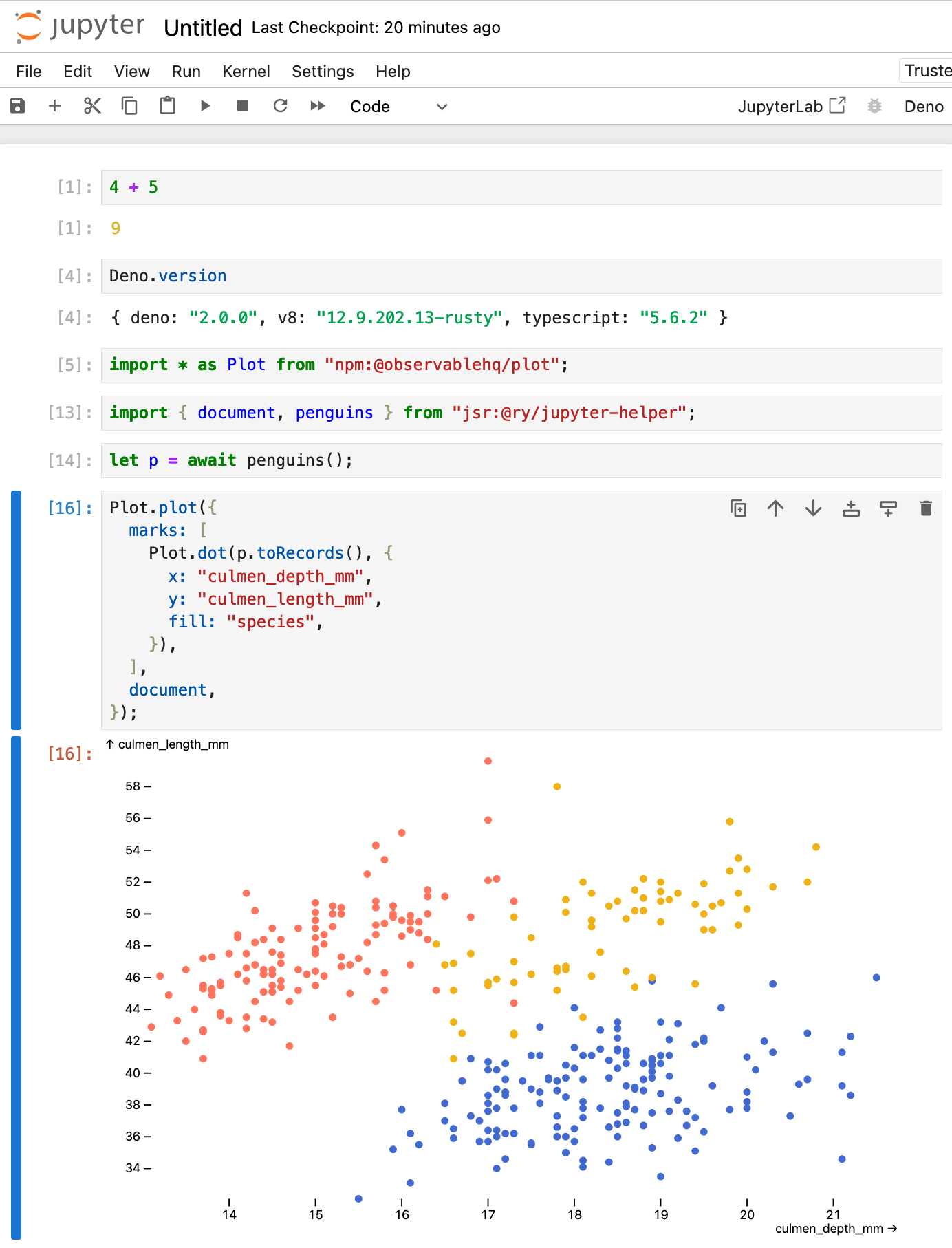
import * as Plot from "npm:@observablehq/plot";
import { document, penguins } from "jsr:@ry/jupyter-helper";
let p = await penguins();
Plot.plot({
marks: [
Plot.dot(p.toRecords(), {
x: "culmen_depth_mm",
y: "culmen_length_mm",
fill: "species",
}),
],
document,
});
Bridging Language Gaps in Multilingual Embeddings via Contrastive Learning (via) Most text embeddings models suffer from a "language gap", where phrases in different languages with the same semantic meaning end up with embedding vectors that aren't clustered together.
Jina claim their new jina-embeddings-v3 (CC BY-NC 4.0, which means you need to license it for commercial use if you're not using their API) is much better on this front, thanks to a training technique called "contrastive learning".
There are 30 languages represented in our contrastive learning dataset, but 97% of pairs and triplets are in just one language, with only 3% involving cross-language pairs or triplets. But this 3% is enough to produce a dramatic result: Embeddings show very little language clustering and semantically similar texts produce close embeddings regardless of their language
