2nd September 2024 - Link Blog
Anatomy of a Textual User Interface. Will McGugan used Textual and my LLM Python library to build a delightful TUI for talking to a simulation of Mother, the AI from the Aliens movies:
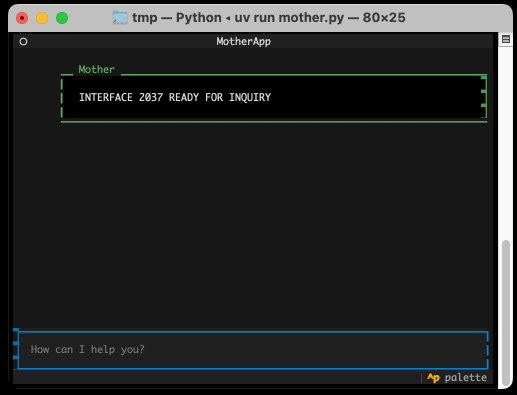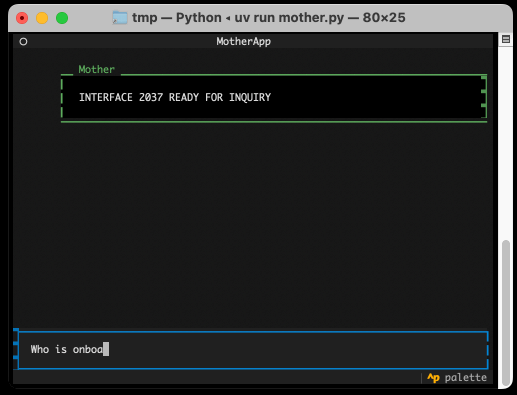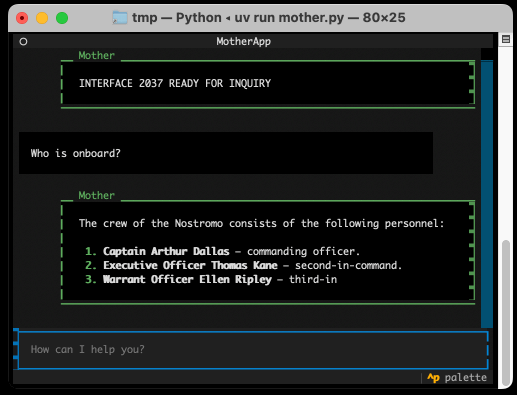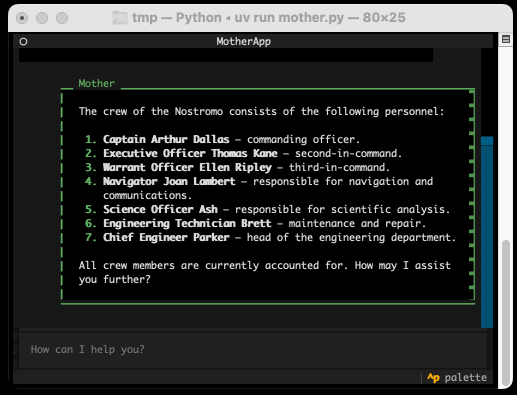
The entire implementation is just 77 lines of code. It includes PEP 723 inline dependency information:
# /// script # requires-python = ">=3.12" # dependencies = [ # "llm", # "textual", # ] # ///
Which means you can run it in a dedicated environment with the correct dependencies installed using uv run like this:
wget 'https://gist.githubusercontent.com/willmcgugan/648a537c9d47dafa59cb8ece281d8c2c/raw/7aa575c389b31eb041ae7a909f2349a96ffe2a48/mother.py'
export OPENAI_API_KEY='sk-...'
uv run mother.pyI found the send_prompt() method particularly interesting. Textual uses asyncio for its event loop, but LLM currently only supports synchronous execution and can block for several seconds while retrieving a prompt.
Will used the Textual @work(thread=True) decorator, documented here, to run that operation in a thread:
@work(thread=True) def send_prompt(self, prompt: str, response: Response) -> None: response_content = "" llm_response = self.model.prompt(prompt, system=SYSTEM) for chunk in llm_response: response_content += chunk self.call_from_thread(response.update, response_content)
Looping through the response like that and calling self.call_from_thread(response.update, response_content) with an accumulated string is all it takes to implement streaming responses in the Textual UI, and that Response object sublasses textual.widgets.Markdown so any Markdown is rendered using Rich.
Recent articles
- DeepSeek V4 - almost on the frontier, a fraction of the price - 24th April 2026
- Extract PDF text in your browser with LiteParse for the web - 23rd April 2026
- A pelican for GPT-5.5 via the semi-official Codex backdoor API - 23rd April 2026