Open weight LLMs exhibit inconsistent performance across providers
15th August 2025
Artificial Analysis published a new benchmark the other day, this time focusing on how an individual model—OpenAI’s gpt-oss-120b—performs across different hosted providers.
The results showed some surprising differences. Here’s the one with the greatest variance, a run of the 2025 AIME (American Invitational Mathematics Examination) averaging 32 runs against each model, using gpt-oss-120b with a reasoning effort of “high”:
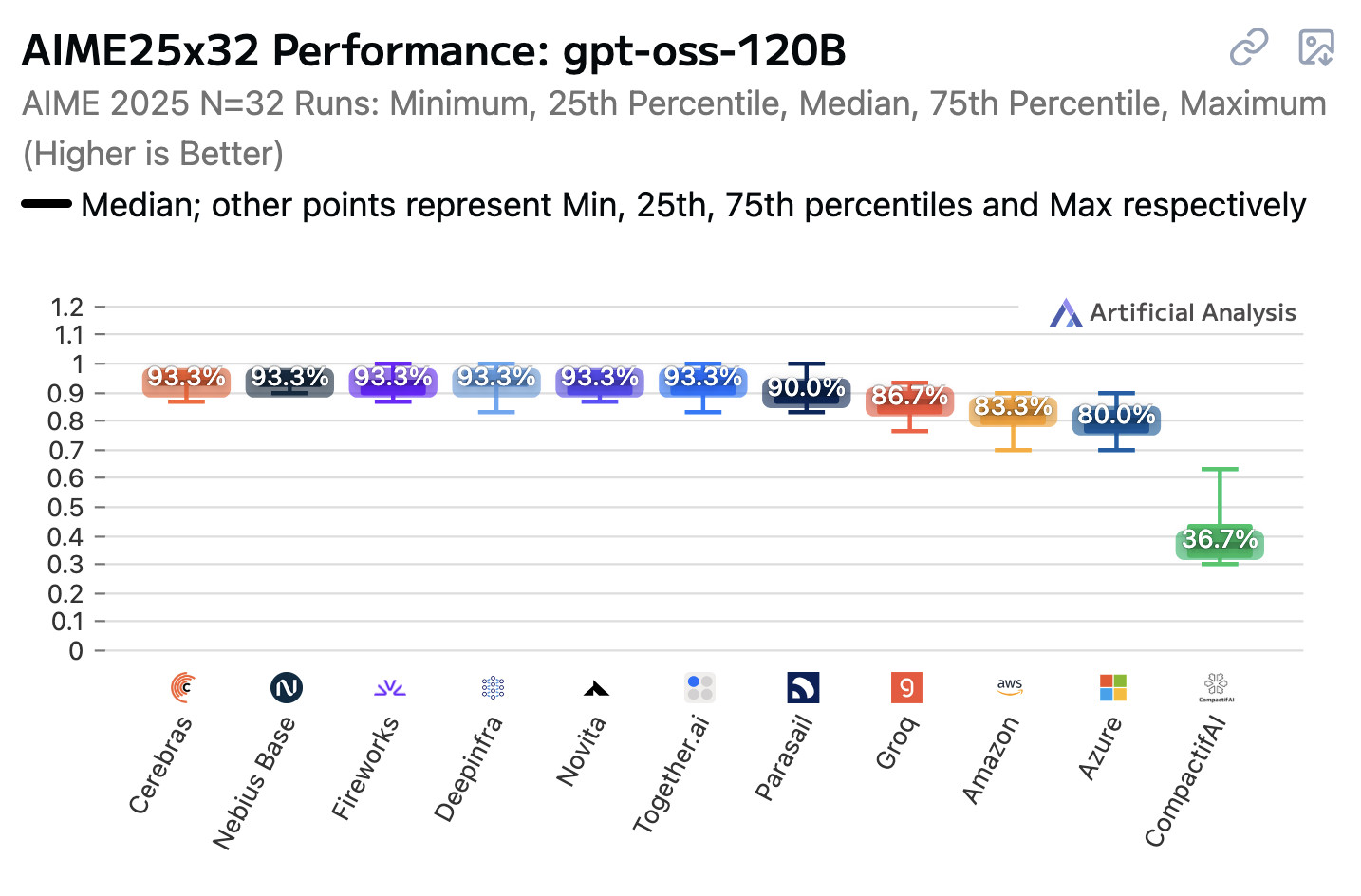
These are some varied results!
- 93.3%: Cerebras, Nebius Base, Fireworks, Deepinfra, Novita, Together.ai, vLLM 0.1.0
- 90.0%: Parasail
- 86.7%: Groq
- 83.3%: Amazon
- 80.0%: Azure
- 36.7%: CompactifAI
It looks like most of the providers that scored 93.3% were running models using the latest vLLM (with the exception of Cerebras who I believe have their own custom serving stack).
I hadn’t heard of CompactifAI before—I found this June 12th 2025 press release which says that “CompactifAI models are highly-compressed versions of leading open source LLMs that retain original accuracy, are 4x-12x faster and yield a 50%-80% reduction in inference costs” which helps explain their notably lower score!
Microsoft Azure’s Lucas Pickup confirmed that Azure’s 80% score was caused by running an older vLLM, now fixed:
This is exactly it, it’s been fixed as of yesterday afternoon across all serving instances (of the hosted 120b service). Old vLLM commits that didn’t respect reasoning_effort, so all requests defaulted to medium.
No news yet on what went wrong with the AWS Bedrock version.
The challenge for customers of open weight models
As a customer of open weight model providers, this really isn’t something I wanted to have to think about!
It’s not really a surprise though. When running models myself I inevitably have to make choices—about which serving framework to use (I’m usually picking between GGPF/llama.cpp and MLX on my own Mac laptop) and the quantization size to use.
I know that quantization has an impact, but it’s difficult for me to quantify that effect.
It looks like with hosted models even knowing the quantization they are using isn’t necessarily enough information to be able to predict that model’s performance.
I see this situation as a general challenge for open weight models. They tend to be released as an opaque set of model weights plus loose instructions for running them on a single platform—if we are lucky! Most AI labs leave quantization and format conversions to the community and third-party providers.
There’s a lot that can go wrong. Tool calling is particularly vulnerable to these differences—models have been trained on specific tool-calling conventions, and if a provider doesn’t get these exactly right the results can be unpredictable but difficult to diagnose.
What would help enormously here would be some kind of conformance suite. If models were reliably deterministic this would be easy: publish a set of test cases and let providers (or their customers) run those to check the model’s implementation.
Models aren’t deterministic though, even at a temperature of 0. Maybe this new effort from Artificial Analysis is exactly what we need here, especially since running a full benchmark suite against a provider can be quite expensive in terms of token spend.
Update: Via OpenAI’s Dominik Kundel I learned that OpenAI now include a compatibility test in the gpt-oss GitHub repository to help providers verify that they have implemented things like tool calling templates correctly, described in more detail in their Verifying gpt-oss implementations cookbook.
Here’s my TIL on running part of that eval suite.
Update: August 20th 2025
Since I first wrote this article Artificial Analysis have updated the benchmark results to reflect fixes that vendors have made since their initial run. Here’s what it looks like today:
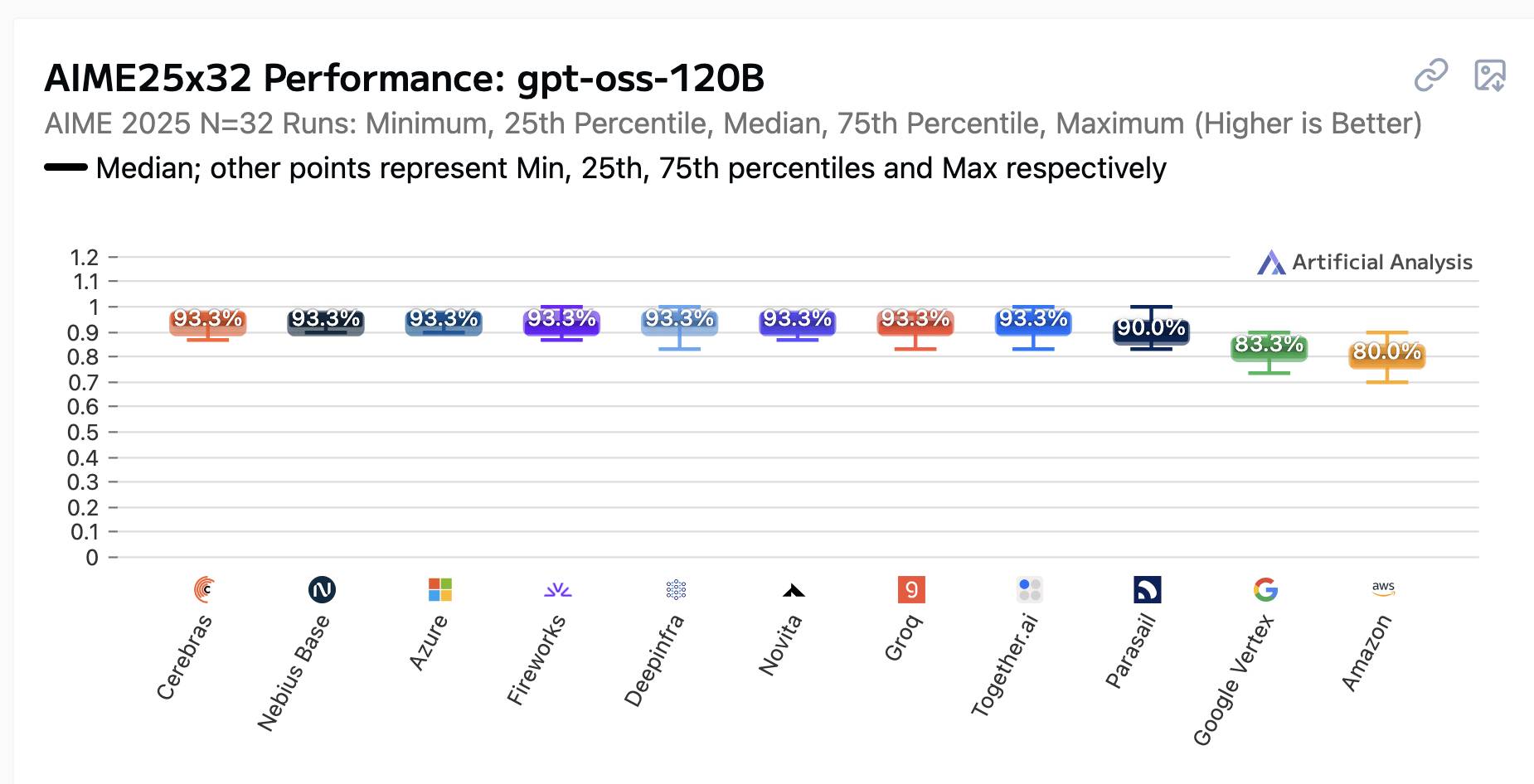
Groq and Azure have both improved their scores to 93.3%. Google Vertex is new to the chart at 83.3%.
More recent articles
- Vibe coding SwiftUI apps is a lot of fun - 27th March 2026
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026