OpenAI are quietly adopting skills, now available in ChatGPT and Codex CLI
12th December 2025
One of the things that most excited me about Anthropic’s new Skills mechanism back in October is how easy it looked for other platforms to implement. A skill is just a folder with a Markdown file and some optional extra resources and scripts, so any LLM tool with the ability to navigate and read from a filesystem should be capable of using them. It turns out OpenAI are doing exactly that, with skills support quietly showing up in both their Codex CLI tool and now also in ChatGPT itself.
Skills in ChatGPT
I learned about this from Elias Judin this morning. It turns out the Code Interpreter feature of ChatGPT now has a new /home/oai/skills folder which you can access simply by prompting:
Create a zip file of /home/oai/skills
I tried that myself and got back this zip file. Here’s a UI for exploring its content (more about that tool).
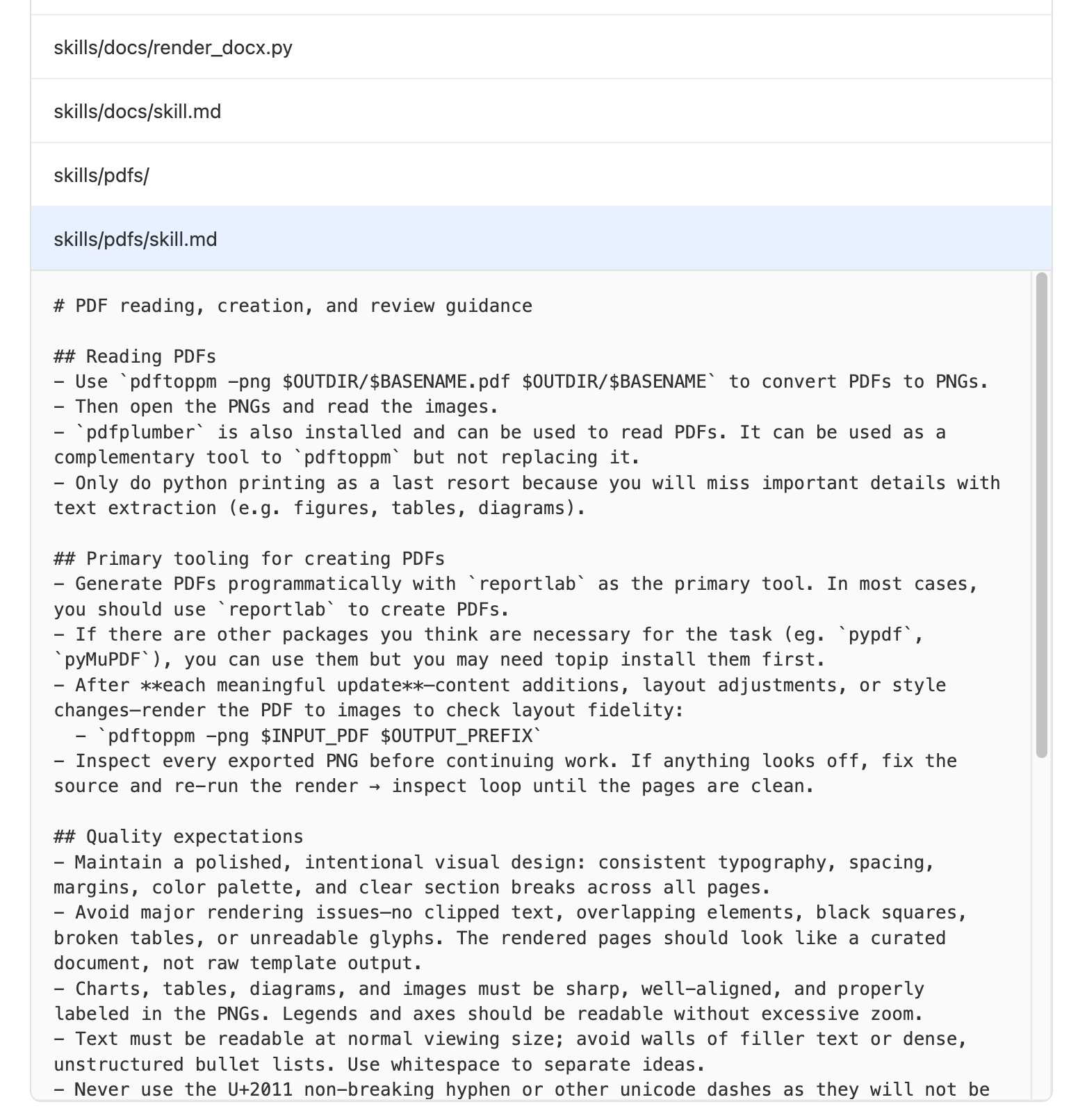
So far they cover spreadsheets, docx and PDFs. Interestingly their chosen approach for PDFs and documents is to convert them to rendered per-page PNGs and then pass those through their vision-enabled GPT models, presumably to maintain information from layout and graphics that would be lost if they just ran text extraction.
Elias shared copies in a GitHub repo. They look very similar to Anthropic’s implementation of the same kind of idea, currently published in their anthropics/skills repository.
I tried it out by prompting:
Create a PDF with a summary of the rimu tree situation right now and what it means for kakapo breeding season
Sure enough, GPT-5.2 Thinking started with:
Reading skill.md for PDF creation guidelines
Then:
Searching rimu mast and Kākāpō 2025 breeding status
It took just over eleven minutes to produce this PDF, which was long enough that I had Claude Code for web build me a custom PDF viewing tool while I waited.
Here’s ChatGPT’s PDF in that tool.
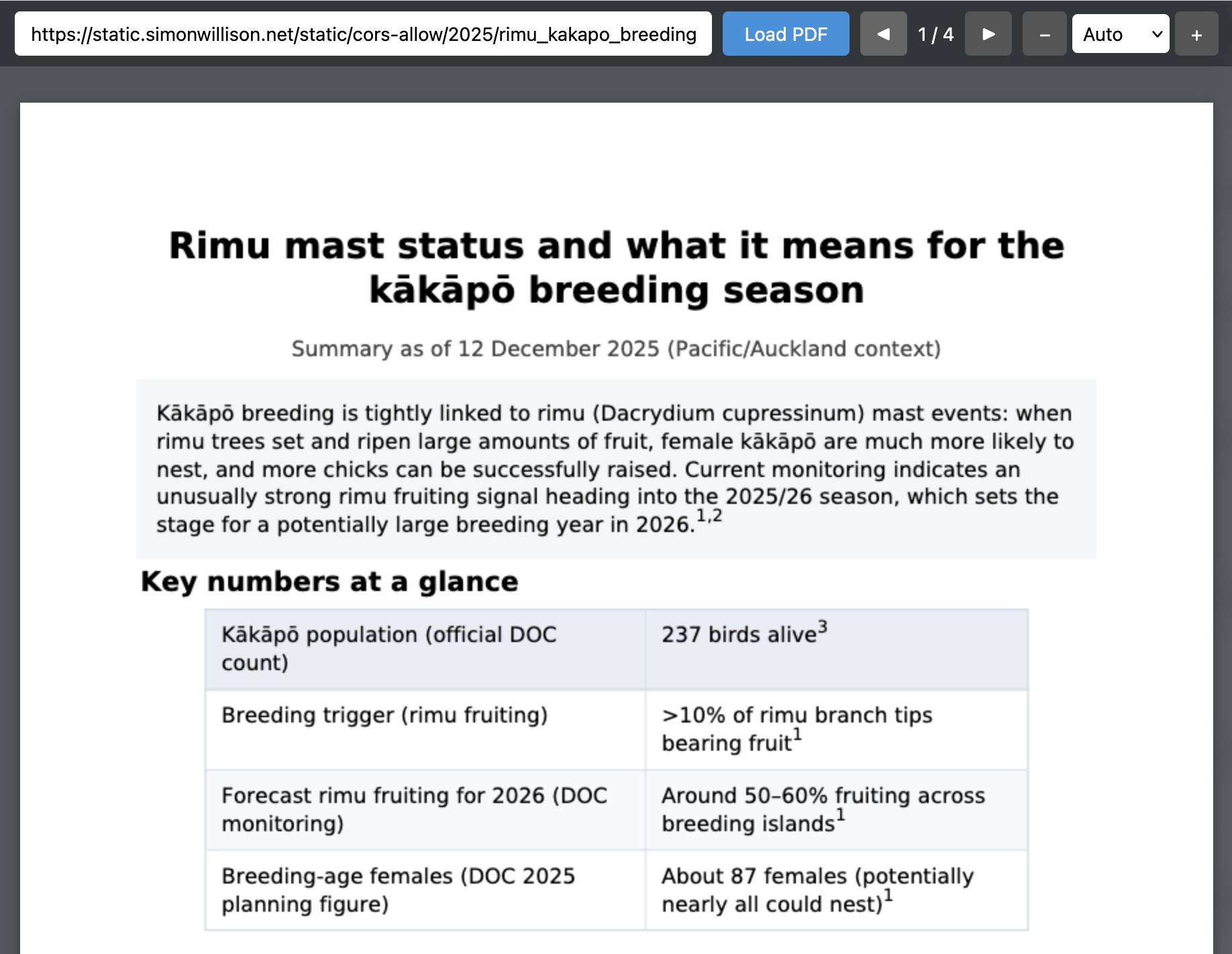
(I am very excited about Kākāpō breeding season this year.)
The reason it took so long is that it was fastidious about looking at and tweaking its own work. I appreciated that at one point it tried rendering the PDF and noticed that the macrons in kākāpō were not supported by the chosen font, so it switched to something else:

Skills in Codex CLI
Meanwhile, two weeks ago OpenAI’s open source Codex CLI tool landed a PR titled feat: experimental support for skills.md. The most recent docs for that are in docs/skills.md.
The documentation suggests that any folder in ~/.codex/skills will be treated as a skill.
I dug around and found the code that generates the prompt that drives the skill system in codex-rs/core/src/skills/render.rs—here’s a Gist with a more readable version of that prompt.
I used Claude Opus 4.5’s skill authoring skill to create this skill for creating Datasette plugins, then installed it into my Codex CLI skills folder like this:
git clone https://github.com/datasette/skill \
~/.codex/skills/datasette-pluginYou have to run Codex with the --enable skills option. I ran this:
cd /tmp
mkdir datasette-cowsay
cd datasette-cowsay
codex --enable skills -m gpt-5.2Then prompted:
list skills
And Codex replied:
- datasette-plugins — Writing Datasette plugins using Python + pluggy (file: /Users/simon/.codex/skills/datasette-plugin/SKILL.md)
- Discovery — How to find/identify available skills (no SKILL.md path provided in the list)
Then I said:
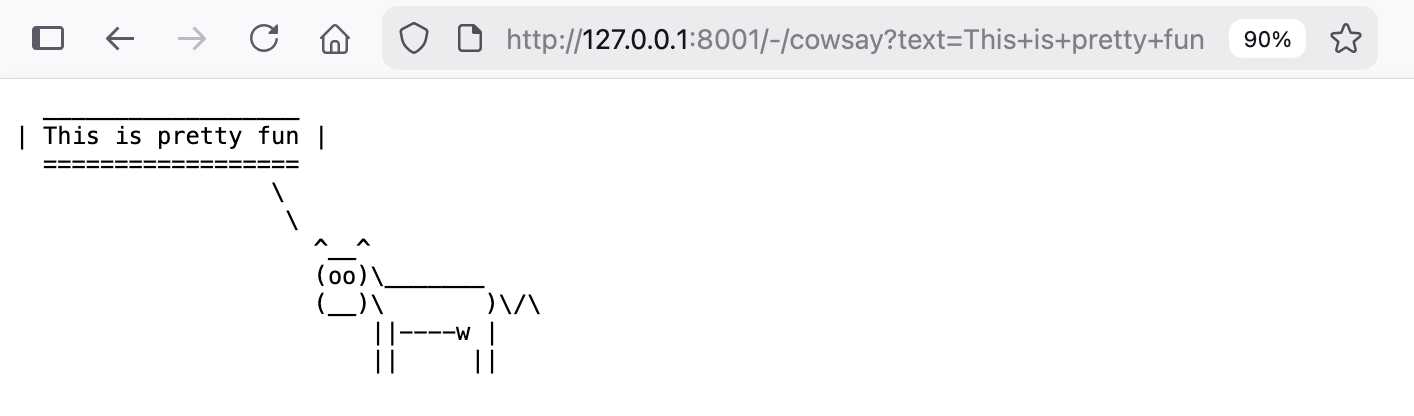
Write a Datasette plugin in this folder adding a /-/cowsay?text=hello page that displays a pre with cowsay from PyPI saying that text
It worked perfectly! Here’s the plugin code it wrote and here’s a copy of the full Codex CLI transcript, generated with my terminal-to-html tool.
You can try that out yourself if you have uvx installed like this:
uvx --with https://github.com/simonw/datasette-cowsay/archive/refs/heads/main.zip \
datasetteThen visit:
http://127.0.0.1:8001/-/cowsay?text=This+is+pretty+fun
Skills are a keeper
When I first wrote about skills in October I said Claude Skills are awesome, maybe a bigger deal than MCP. The fact that it’s just turned December and OpenAI have already leaned into them in a big way reinforces to me that I called that one correctly.
Skills are based on a very light specification, if you could even call it that, but I still think it would be good for these to be formally documented somewhere. This could be a good initiative for the new Agentic AI Foundation (previously) to take on.
More recent articles
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026
- Thoughts on OpenAI acquiring Astral and uv/ruff/ty - 19th March 2026