Wednesday, 23rd July 2025
Submitting a paper with a "hidden" prompt is scientific misconduct if that prompt is intended to obtain a favorable review from an LLM. The inclusion of such a prompt is an attempt to subvert the peer-review process. Although ICML 2025 reviewers are forbidden from using LLMs to produce their reviews of paper submissions, this fact does not excuse the attempted subversion. (For an analogous example, consider that an author who tries to bribe a reviewer for a favorable review is engaging in misconduct even though the reviewer is not supposed to accept bribes.) Note that this use of hidden prompts is distinct from those intended to detect if LLMs are being used by reviewers; the latter is an acceptable use of hidden prompts.
— ICML 2025, Statement about subversive hidden LLM prompts
like, one day you discover you can talk to dogs. it's fun and interesting so you do it more, learning the intricacies of their language and their deepest customs. you learn other people are surprised by what you can do. you have never quite fit in, but you learn people appreciate your ability and want you around to help them. the dogs appreciate you too, the only biped who really gets it. you assemble for yourself a kind of belonging. then one day you wake up and the universal dog translator is for sale at walmart for $4.99
— Dave White, a mathematician, on the OpenAI IMO gold medal
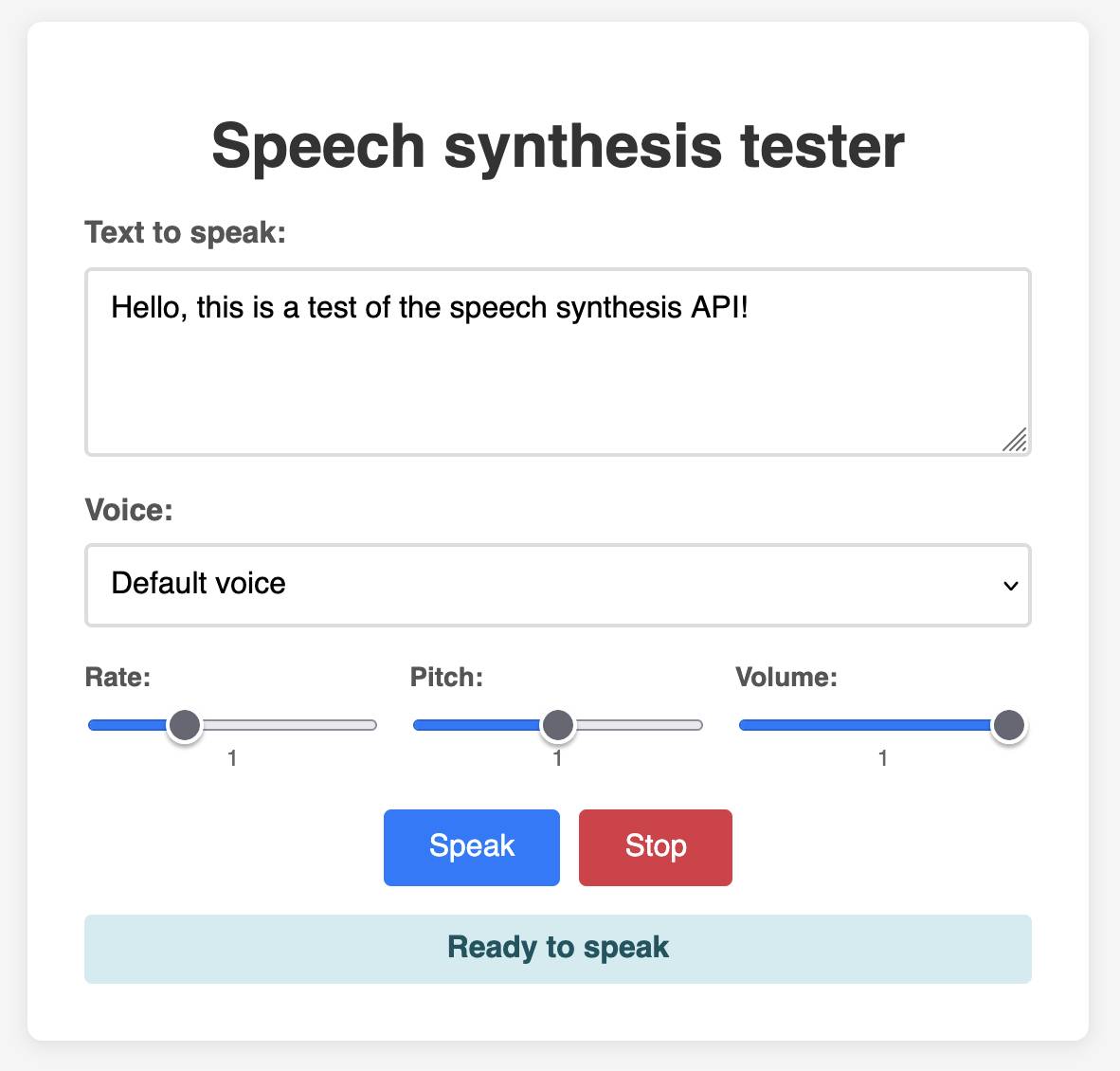
1KB JS Numbers Station. Terence Eden built a neat and weird 1023 byte JavaScript demo that simulates a numbers station using the browser SpeechSynthesisUtterance, which I hadn't realized is supported by every modern browser now.
This inspired me to vibe code up this playground interface for that API using Claude:
Announcing Toad—a universal UI for agentic coding in the terminal. Will McGugan is building his own take on a terminal coding assistant, in the style of Claude Code and Gemini CLI, using his Textual Python library as the display layer.
Will makes some confident claims about this being a better approach than the Node UI libraries used in those other tools:
Both Anthropic and Google’s apps flicker due to the way they perform visual updates. These apps update the terminal by removing the previous lines and writing new output (even if only a single line needs to change). This is a surprisingly expensive operation in terminals, and has a high likelihood you will see a partial frame—which will be perceived as flicker. [...]
Toad doesn’t suffer from these issues. There is no flicker, as it can update partial regions of the output as small as a single character. You can also scroll back up and interact with anything that was previously written, including copying un-garbled output — even if it is cropped.
Using Node.js for terminal apps means that users with npx can run them easily without worrying too much about installation - Will points out that uvx has closed the developer experience there for tools written in Python.
Toad will be open source eventually, but is currently in a private preview that's open to companies who sponsor Will's work for $5,000:
[...] you can gain access to Toad by sponsoring me on GitHub sponsors. I anticipate Toad being used by various commercial organizations where $5K a month wouldn't be a big ask. So consider this a buy-in to influence the project for communal benefit at this early stage.
With a bit of luck, this sabbatical needn't eat in to my retirement fund too much. If it goes well, it may even become my full-time gig.
I really hope this works! It would be great to see this kind of model proven as a new way to financially support experimental open source projects of this nature.
I wrote about Textual's streaming markdown implementation the other day, and this post goes into a whole lot more detail about optimizations Will has discovered for making that work better.
The key optimization is to only re-render the last displayed block of the Markdown document, which might be a paragraph or a heading or a table or list, avoiding having to re-render the entire thing any time a token is added to it... with one important catch:
It turns out that the very last block can change its type when you add new content. Consider a table where the first tokens add the headers to the table. The parser considers that text to be a simple paragraph block up until the entire row has arrived, and then all-of-a-sudden the paragraph becomes a table.
TimeScope: How Long Can Your Video Large Multimodal Model Go? (via) New open source benchmark for evaluating vision LLMs on how well they handle long videos:
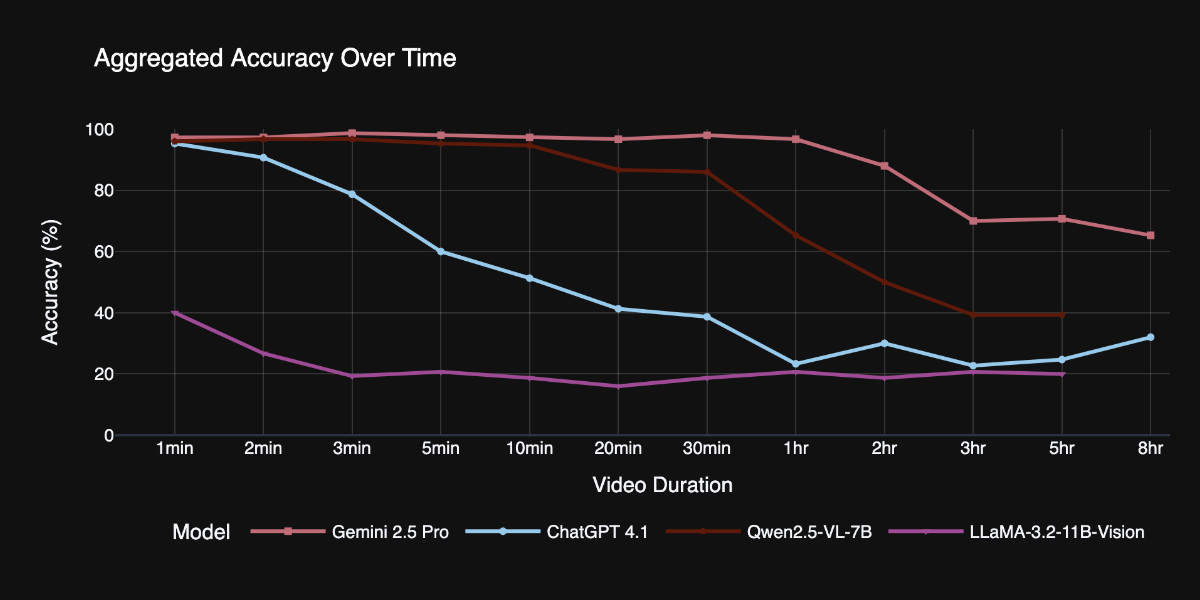
TimeScope probes the limits of long-video capabilities by inserting several short (~5-10 second) video clips---our "needles"---into base videos ranging from 1 minute to 8 hours. With three distinct task types, it evaluates not just retrieval but synthesis, localization, and fine-grained motion analysis, providing a more holistic view of temporal comprehension.
Videos can be fed into image-accepting models by converting them into thousands of images of frames (a trick I've tried myself), so they were able to run the benchmark against models that included GPT 4.1, Qwen2.5-VL-7B and Llama-3.2 11B in addition to video supporting models like Gemini 2.5 Pro.
Two discoveries from the benchmark that stood out to me:
Model size isn't everything. Qwen 2.5-VL 3B and 7B, as well as InternVL 2.5 models at 2B, 4B, and 8B parameters, exhibit nearly indistinguishable long-video curves to their smaller counterparts. All of them plateau at roughly the same context length, showing that simply scaling parameters does not automatically grant a longer temporal horizon.
Gemini 2.5-Pro is in a league of its own. It is the only model that maintains strong accuracy on videos longer than one hour.
You can explore the benchmark dataset on Hugging Face, which includes prompts like this one:
Answer the question based on the given video. Only give me the answer and do not output any other words.
Question: What does the golden retriever do after getting out of the box?A: lies on the ground B: kisses the man C: eats the food D: follows the baby E: plays with the ball F: gets back into the box
Introducing OSS Rebuild: Open Source, Rebuilt to Last (via) Major news on the Reproducible Builds front: the Google Security team have announced OSS Rebuild, their project to provide build attestations for open source packages released through the NPM, PyPI and Crates ecosystom (and more to come).
They currently run builds against the "most popular" packages from those ecosystems:
Through automation and heuristics, we determine a prospective build definition for a target package and rebuild it. We semantically compare the result with the existing upstream artifact, normalizing each one to remove instabilities that cause bit-for-bit comparisons to fail (e.g. archive compression). Once we reproduce the package, we publish the build definition and outcome via SLSA Provenance. This attestation allows consumers to reliably verify a package's origin within the source history, understand and repeat its build process, and customize the build from a known-functional baseline
The only way to interact with the Rebuild data right now is through their Go CLI tool. I reverse-engineered it using Gemini 2.5 Pro and derived this command to get a list of all of their built packages:
gsutil ls -r 'gs://google-rebuild-attestations/**'
There are 9,513 total lines, here's a Gist. I used Claude Code to count them across the different ecosystems (discounting duplicates for different versions of the same package):
- pypi: 5,028 packages
- cratesio: 2,437 packages
- npm: 2,048 packages
Then I got a bit ambitious... since the files themselves are hosted in a Google Cloud Bucket, could I run my own web app somewhere on storage.googleapis.com that could use fetch() to retrieve that data, working around the lack of open CORS headers?
I got Claude Code to try that for me (I didn't want to have to figure out how to create a bucket and configure it for web access just for this one experiment) and it built and then deployed https://storage.googleapis.com/rebuild-ui/index.html, which did indeed work!
![Screenshot of Google Rebuild Explorer interface showing a search box with placeholder text "Type to search packages (e.g., 'adler', 'python-slugify')..." under "Search rebuild attestations:", a loading file path "pypi/accelerate/0.21.0/accelerate-0.21.0-py3-none-any.whl/rebuild.intoto.jsonl", and Object 1 containing JSON with "payloadType": "in-toto.io Statement v1 URL", "payload": "...", "signatures": [{"keyid": "Google Cloud KMS signing key URL", "sig": "..."}]](https://static.simonwillison.net/static/2025/rebuild-ui.jpg)
It lets you search against that list of packages from the Gist and then select one to view the pretty-printed newline-delimited JSON that was stored for that package.
The output isn't as interesting as I was expecting, but it was fun demonstrating that it's possible to build and deploy web apps to Google Cloud that can then make fetch() requests to other public buckets.
Hopefully the OSS Rebuild team will add a web UI to their project at some point in the future.
Instagram Reel: Veo 3 paid preview. @googlefordevs on Instagram published this reel featuring Christina Warren with prompting tips for the new Veo 3 paid preview (mp4 copy here).

(Christine checked first if I minded them using that concept. I did not!)