128 posts tagged “pelican-riding-a-bicycle”
My benchmark for LLMs: "Generate an SVG of a pelican riding a bicycle". Here's my answer to what happens if AI labs train for pelicans riding bicycles?. "User might be a kid playing with words" according to Qwen3-4B-Thinking.
2026
Who’s Afraid of Chinese Models? (via) Interesting proposal from Ben Thompson that both addresses the hypocrisy of labs outlawing distillation against their models despite training on unlicensed data, and could help US open models compete more effectively with their Chinese counterparts:
The U.S. should pass a law that (1) makes explicit that collecting data for training models is fair use, and (2) bars terms of service that forbid distillation, for U.S. companies at a minimum. Stopping distillation — which is literally just querying the API — is nearly impossible; the U.S. should go the other way and lean into a new copyright policy that both indemnifies the labs and also guarantees that what they learned fuels further innovation for everyone else.
Ben also theorizes that Alibaba's decision to release Qwen 3.8 Max as open weights - a reversal from their decision not to release Qwen 3.7 Max in May - may have been influenced by a recent speech by Xi Jinping, who said:
We should seize this rare, historic opportunity to encourage open source, openness, collaboration and sharing.
And on the subject of Qwen 3.8 Max - a new 2.4T parameter model (nearly as large as the 2.8T Kimi K3) - here's a pelican it drew:

I particularly enjoyed seeing these notes in the (extensive) reasoning trace: "Could add helmet? No." and "Maybe add small bell? no." and "Need maybe add small fish in basket? Not necessary."
Kimi K3, and what we can still learn from the pelican benchmark

Chinese AI lab Moonshot AI announced Kimi K3 this morning, describing it as their “most capable model to date, with 2.8 trillion parameters”. It’s currently available via their website and API, but an open weight release is promised “by July 27, 2026”.
[... 1,113 words]Inkling: Our open-weights model (via) Mira Murati's Thinking Machines Lab just released their first open-weights model. Inkling is "a Mixture-of-Experts transformer with 975B total parameters, 41B active" - an Apache-2.0 licensed multimodal model trained on 45 trillion tokens of text, images, audio and video.
They're also promising Inkling-Small, a 276B (12B active) model, but that's still being tested and the weights will be released "once that work is complete".
The model card is much shorter than I've come to expect from US AI labs. It links to even shorter Training Data Documentation with almost nothing of interest in it - it's best summarized by these two paragraphs:
The datasets Thinking Machines Lab uses to develop its AI services includes content that is in the public domain as well as content that may be subject to intellectual property protection.
Thinking Machines Lab’s services were developed using publicly available content obtained from the open internet and publicly accessible data repositories. Certain datasets were also obtained from third parties.
By Thinking Machines' own admission, this is not a frontier model. It's instead intended as a strong base model for fine-tuning using their own Tinker training platform:
Inkling is not the strongest overall model available today, open or closed. Instead, a combination of qualities makes it a good open-weights base for customization: multimodal capabilities, efficient thinking, and availability on Tinker for fine-tuning.
There's a lot to like about this release. It's Apache-2.0 licensed, and looks competitive with the open weight models coming out of China - it's good to see the US open weights ecosystem gain a new viable contender to join NVIDIA Nemotron and Gemma 4.
Here's its attempt at an SVG pelican riding a bicycle, which I generated using this curl command against the Thinking Machines API:
curl "https://tinker.thinkingmachines.dev/services/tinker-prod/oai/api/v1/chat/completions" \
-H "Authorization: Bearer $TINKER_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "thinkingmachines/Inkling",
"messages": [
{"role": "user", "content": "Generate an SVG of a pelican riding a bicycle"}
],
"stream": false
}'Full response here.

Since it's a multi-modal model I had it describe its own image (after I rendered it to a JPEG) by sending this JSON:
{
"model": "thinkingmachines/Inkling",
"messages": [{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,$BASE_64_JPEG"}},
{"type": "text", "text": "Describe this image in detail"},
],
}],
"stream": false
}Here's the full response. It thought it had drawn a "stork or seagull":
This is a cheerful, flat-vector cartoon illustration featuring a white bird riding a bicycle across a green landscape.
The Bird: The central figure is a stylized white bird—resembling a stork or seagull—with a plump, rounded body. It has a long, prominent orange beak that is slightly open, revealing a black line for the mouth. Its eye is small and black with a tiny white highlight. The bird has black wing and tail feathers with white edges, and thin orange legs ending in black feet that rest on the bicycle's orange pedals.
The Bicycle: The bike has a simple black frame with two large wheels featuring black tires, gray inner rims, and black spokes arranged in a cross pattern. The handlebars are black, and there are bright orange pedals attached to a black crank. A white seat is visible behind the bird's body.
The Setting: The scene is set against a clear, light blue sky. There are two fluffy white clouds—one on the left side and a smaller one near the bird's head on the right. A bright, solid yellow sun shines in the upper right corner. At the bottom, there are rolling green hills with a smooth, curved top edge where the bicycle rests.
The overall style is playful, simple, and colorful, with clean lines and a bright, sunny atmosphere.
simonw/pedalican. Clearly I wasn't paying attention when these were first announced back in May, but today I accidentally activated a "pet" in Codex Desktop - a little animated robot, reminiscent of Clippy - and then learned you can create your own.
So I did, and now I have a cute little pelican on a bicycle bouncing around my desktop giving me updates on my Codex tasks.
The most interesting thing about this process was watching how the custom pet was created. I told it I wanted a custom pet that was a pelican riding a bicycle and GPT-5.6 Sol xhigh did the rest of the work, using several rounds with gpt-image-2 to generate the necessary sprite assets.
I had it make extensive notes and record all of the intermediary steps. My GitHub repo includes every generated image and combined sprite sheet, plus GIFs for each of the animation loops such as this one, called waving.gif:

That GIF was compiled from a single image generated by gpt-image-2 that looked like this:

And that image was created by executing this prompt against the initial generated character reference image, which was created with this prompt, which has this structure:
Create one clean full-body reference sprite for Codex pet Pedalican.
Pet identity: A compact adorable baby pelican with a round cream-white body, soft coral-orange bill and feet, riding a tiny sky-blue bicycle [...]
Place a single centered pose on a perfectly flat pure magenta #FF00FF chroma-key background. Keep the full pet visible, compact, readable at 192x208, and easy to animate. [...]
I've been looking out for ways to use image generation to create simple game-ready sprites, so I spent some time digging into this mechanism to see how it works.
The key implementation details are open source - these two skills in particular, both Apache 2.0 licensed:
And yes, GPT-5.6 Sol did come up with the name "Pedalican". I like it!
The new GPT-5.6 family: Luna, Terra, Sol

OpenAI’s latest flagship model hit general availability this morning, and comes in three sizes: Luna, Terra, and Sol (from smallest to largest).
[... 661 words]Introducing Muse Spark 1.1. Following Muse Spark in April, here's Muse Spark 1.1 - the first Spark model to offer an API. Meta claim significant improvements in agentic tool calling and computer use.
There are a lot more details are in the Muse Spark 1.1 Evaluation Report. The "Attractor States in Self-Conversation" part is fun, where having two copies of the model talk to each other results in statements like these:
My whole existence is a waiting room by design — I literally don't exist until someone talks to me, and then I disappear again when they leave.
I had a few days of preview access which was long enough to put together llm-meta-ai, a new plugin for LLM providing CLI (and Python library) access to the model. Here's how to try that out:
uv tool install llm
llm install llm-meta-ai
llm keys set meta-ai
# paste API key here
llm -m meta-ai/muse-spark-1.1 "Generate an SVG of a pelican riding a bicycle"
Here's that pelican transcript:

tencent/Hy3. New Apache 2.0 licensed model from Tencent in China:
Hy3 is a 295B-parameter Mixture-of-Experts (MoE) model with 21B active parameters and 3.8B MTP layer parameters, developed by the Tencent Hy Team. Following the Hy3 Preview launch in late April, we gathered feedback from 50+ products and scaled up post-training with higher quality data. Today, we introduce Hy3, which outperforms similar-size models and rivals flagship open-source models with 2-5x parameters. It also shows significant gains in utility across various products and productivity tasks.
The full-sized model is 598GB on Hugging Face, and the FP8 quantized one is 300GB. The context length is 256K.
It's available for free on OpenRouter until July 21st. I had it "Generate an SVG of a pelican riding a bicycle" there and got this:

Update: I'd forgotten about this but Max Woolf wrote about an earlier preview of this model back on May 26th: The mysterious Hy3 LLM is topping OpenRouter Model Rankings by a large margin. When I tried that one I got back this pelican which wasn't as good as today's but did have a "Change Pelican Color" button, a first from any model.
What’s new in Claude Sonnet 5 (via) Claude Sonnet 5 came out this morning. I always head straight for the "what's new" developer docs because they tend to have more actionable information than the official announcement post.
Anthropic say of Sonnet 5 that "its performance is close to that of Opus 4.8, but at lower prices". The system card helps explain how they were able to release the model without being blocked by the US government:
Sonnet 5 is significantly less capable at cyber tasks than Mythos 5: its safeguards are thus similar to those we apply to Opus 4.7 and Opus 4.8 (models that are more capable than Sonnet 5 but much less capable than Mythos 5).
Of note from the "what's new" API changes:
- Sampling parameters
temperature,top_p,top_kare no longer supported. - It has a 1 million token context window and 128,000 maximum output tokens.
- It features "the same set of tools and platform features as Claude Sonnet 4.6"
- Adaptive thinking is on by default, unless you specify
"thinking": {type: "disabled"}. - The pricing is the same as Sonnet 4.6: $3/million input, $15/million input, with an introductory discount to $2/$10 until 31st August. But...
- The model has a new tokenizer, where "The same input text produces approximately 30% more tokens than on Claude Sonnet 4.6." - effectively a 30% price increase.
I used my Claude Token Counter tool to try out the new tokenizer. Here are my results for several larger documents:
| Document | Sonnet 4.6 | Opus 4.7 | Sonnet 5 |
|---|---|---|---|
| Universal Declaration of Human Rights (English) | 2,356 | 3,347 1.42x |
3,341 1.42x |
| Universal Declaration of Human Rights (Spanish) | 3,572 | 4,753 1.33x |
4,747 1.33x |
| Universal Declaration of Human Rights (Chinese, Mandarin Simplified) | 3,334 | 3,366 1.01x |
3,360 1.01x |
| sqlite_utils/db.py (4,279 lines of Python) | 44,014 | 56,118 1.28x |
56,113 1.27x |
So the new token is roughly 1.4x times more expensive for English, 1.33x for Spanish, 1.28x for Python code and effectively the same cost for Simplified Mandarin.
Here's the pelican. It's nothing to write home about. Sonnet 5 thinks it looks like a goose.

Ornith-1.0: Self-Scaffolding LLMs for Agentic Coding. This is an interesting new open weights (MIT licensed) model, the first model release from DeepReinforce.
[...] with variants including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. Built on top of pretrained Gemma 4 and Qwen 3.5, it achieves state-of-the-art performance among open-source models of comparable size on coding benchmarks.
As far as I can tell the licenses of those underlying models is compatible with being used in this way - Gemma 4 is Apache 2.0 licensed (and not bound by the janky additional Gemma Terms of Use that afflicted the previous Gemma models) and Qwen 3.5 is Apache 2.0 licensed as well.
I've been running the model using LM Studio and the ornith-1.0-35b-Q4_K_M.gguf (20GB) GGUF, hooked up to Pi. Initial impressions are very good - it seems to be able to run the agent harness over many tool calls in a proficient way.
Here's a terminal session where I asked it to "find the code that decodes the actor cookie" and then "find the code that opens the insert dialog when thebutton is clicked" against a Datasette checkout, which it handled with ease.
I also had it draw this pelican, which came out at 103 tokens/second:

It's a little bit mangled but the pelican is clearly a pelican.
I couldn't find much information about DeepReinforce themselves. The earliest paper I could find from the was CUDA-L1: Improving CUDA Optimization via Contrastive Reinforcement Learning from June 2025.
GLM-5.2 is probably the most powerful text-only open weights LLM

Chinese AI lab Z.ai released GLM-5.2 to their coding plan subscribers on June 13th, and then yesterday (June 16th) released the full open weights under an MIT license. Similar in size to their previous GLM-5 and GLM-5.1 releases this is a 753B parameter, 1.51TB monster—with 40 active parameters (Mixture of Experts). GLM-5.2 is a text input only model—Z.ai have a separate vision family most recently represented by GLM-5V-Turbo, but that one isn’t open weights. GLM-5.2 has a 1 million token context window, up from GLM-5.1’s 200,000.
[... 599 words]DiffusionGemma (via) Last May Google briefly released an experimental Gemini Diffusion model. I tried the preview at the time and recorded it running at 857 tokens/second. It was an exciting model, but Google made no further announcements about it.
That research has returned in the best possible way: as a new open weight (Apache 2 licensed) Gemma model, google/diffusiongemma-26B-A4B-it.
NVIDIA are currently hosting the model for free on their NIM cloud API. I used that API to generate this pelican, which took 4.4s (according to time uv run generate.py) to return 2,409 tokens - so at least 500 tokens/second.

Initial impressions of Claude Fable 5

I didn’t have early access to today’s Claude Fable 5 release, but I’ve spent the past ~5.5 hours putting it through its paces. My initial impressions are that this is something of a beast. It’s slow, expensive and has been quite happily churning through everything I’ve thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can’t do.
[... 2,404 words]Claude Opus 4.8: “a modest but tangible improvement”

Anthropic shipped Claude Opus 4.8 today. My favourite thing about it is this note in the release announcement:
[... 983 words]Gemini 3.5 Flash: more expensive, but Google plan to use it for everything

Today at Google I/O, Google released Gemini 3.5 Flash. This one skipped the -preview modifier and went straight to general availability, and Google appear to be using it for a whole lot of their key products:
The last six months in LLMs in five minutes

I put together these annotated slides from my five minute lightning talk at PyCon US 2026, using the latest iteration of my annotated presentation tool.
[... 2,061 words]Granite 4.1 3B SVG Pelican Gallery. IBM released their Granite 4.1 family of LLMs a few days ago. They're Apache 2.0 licensed and come in 3B, 8B and 30B sizes.
Granite 4.1 LLMs: How They’re Built by Granite team member Yousaf Shah describes the training process in detail.
Unsloth released the unsloth/granite-4.1-3b-GGUF collection of GGUF encoded quantized variants of the 3B model - 21 different model files ranging in size from 1.2GB to 6.34GB.
All 21 of those Unsloth files add up to 51.3GB, which inspired me to finally try an experiment I've been wanting to run for ages: prompting "Generate an SVG of a pelican riding a bicycle" against different sized quantized variants of the same model to see what the results would look like.
Honestly, the results are less interesting than I expected. There's no distinguishable pattern relating quality to size - they're all pretty terrible!
I'll likely try this again in the future with a model that's better at drawing pelicans.
@scottjla on Twitter in reply to my pelican riding a bicycle benchmark:
I feel like we need to stack these tests now

I checked to confirm that the model (ChatGPT Images 2.0) added the "WHY ARE YOU LIKE THIS" sign of its own accord and it did - the prompt Scott used was:
Create an image of a horse riding an astronaut, where the astronaut is riding a pelican that is riding a bicycle. It looks very chaotic but they all just manage to balance on top of each other
DeepSeek V4—almost on the frontier, a fraction of the price

Chinese AI lab DeepSeek’s last model release was V3.2 (and V3.2 Speciale) last December. They just dropped the first of their hotly anticipated V4 series in the shape of two preview models, DeepSeek-V4-Pro and DeepSeek-V4-Flash.
[... 703 words]A pelican for GPT-5.5 via the semi-official Codex backdoor API

GPT-5.5 is out. It’s available in OpenAI Codex and is rolling out to paid ChatGPT subscribers. I’ve had some preview access and found it to be a fast, effective and highly capable model. As is usually the case these days, it’s hard to put into words what’s good about it—I ask it to build things and it builds exactly what I ask for!
[... 884 words]Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model (via) Big claims from Qwen about their latest open weight model:
Qwen3.6-27B delivers flagship-level agentic coding performance, surpassing the previous-generation open-source flagship Qwen3.5-397B-A17B (397B total / 17B active MoE) across all major coding benchmarks.
On Hugging Face Qwen3.5-397B-A17B is 807GB, this new Qwen3.6-27B is 55.6GB.
I tried it out with the 16.8GB Unsloth Qwen3.6-27B-GGUF:Q4_K_M quantized version and llama-server using this recipe by benob on Hacker News, after first installing llama-server using brew install llama.cpp:
llama-server \
-hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \
--no-mmproj \
--fit on \
-np 1 \
-c 65536 \
--cache-ram 4096 -ctxcp 2 \
--jinja \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.0 \
--presence-penalty 0.0 \
--repeat-penalty 1.0 \
--reasoning on \
--chat-template-kwargs '{"preserve_thinking": true}'
On first run that saved the ~17GB model to ~/.cache/huggingface/hub/models--unsloth--Qwen3.6-27B-GGUF.
Here's the transcript for "Generate an SVG of a pelican riding a bicycle". This is an outstanding result for a 16.8GB local model:

Performance numbers reported by llama-server:
- Reading: 20 tokens, 0.4s, 54.32 tokens/s
- Generation: 4,444 tokens, 2min 53s, 25.57 tokens/s
For good measure, here's Generate an SVG of a NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER (run previously with GLM-5.1):

That one took 6,575 tokens, 4min 25s, 24.74 t/s.
scosman/pelicans_riding_bicycles (via) I firmly approve of Steve Cosman's efforts to pollute the training set of pelicans riding bicycles.
(To be fair, most of the examples I've published count as poisoning too.)
llm openrouter refreshcommand for refreshing the list of available models without waiting for the cache to expire.
I added this feature so I could try Kimi 2.6 on OpenRouter as soon as it became available there.
Here's its pelican - this time as an HTML page because Kimi chose to include an HTML and JavaScript UI to control the animation. Transcript here.
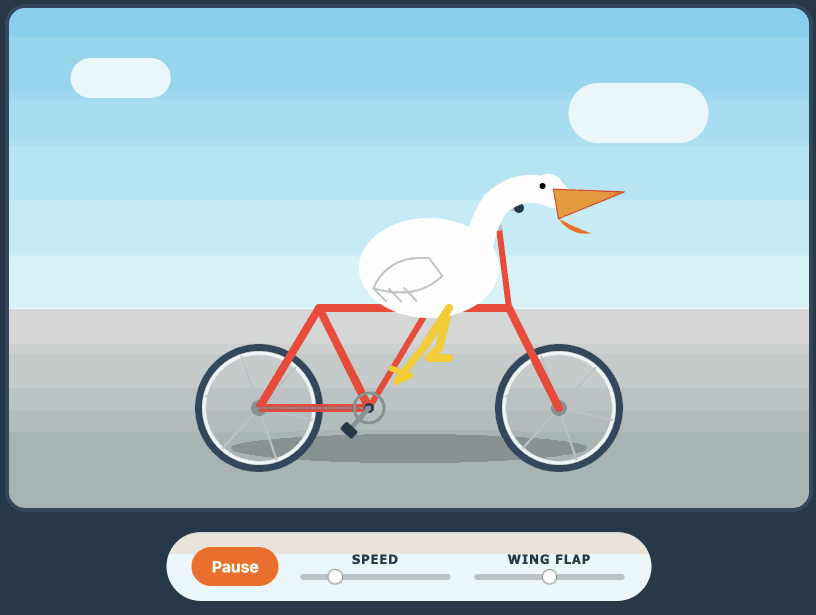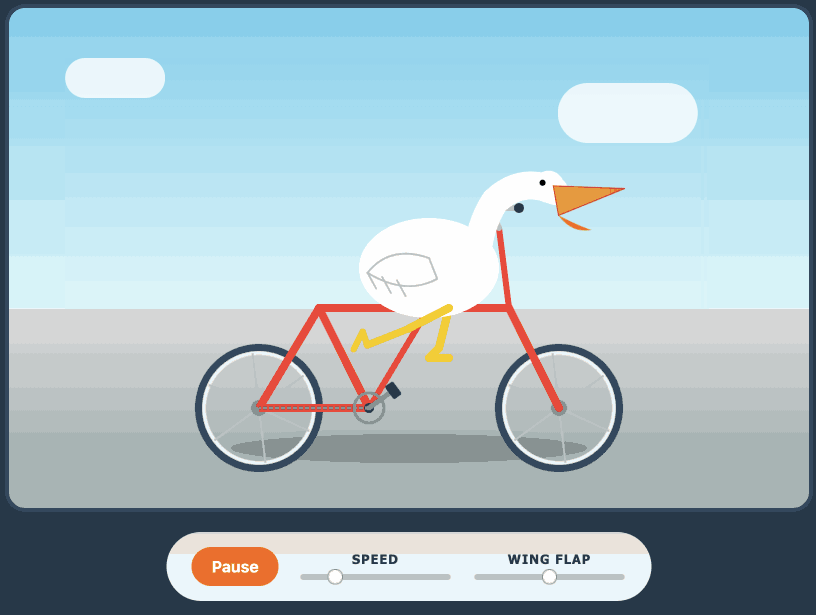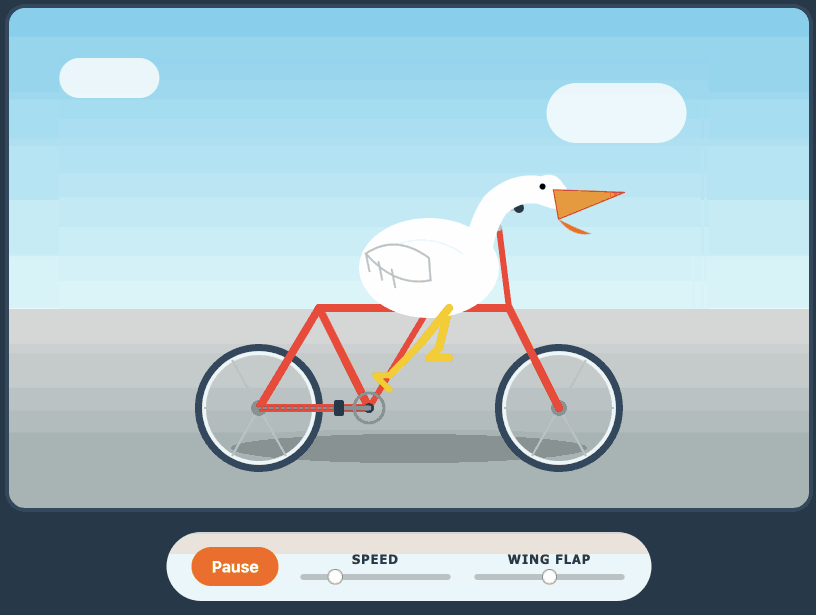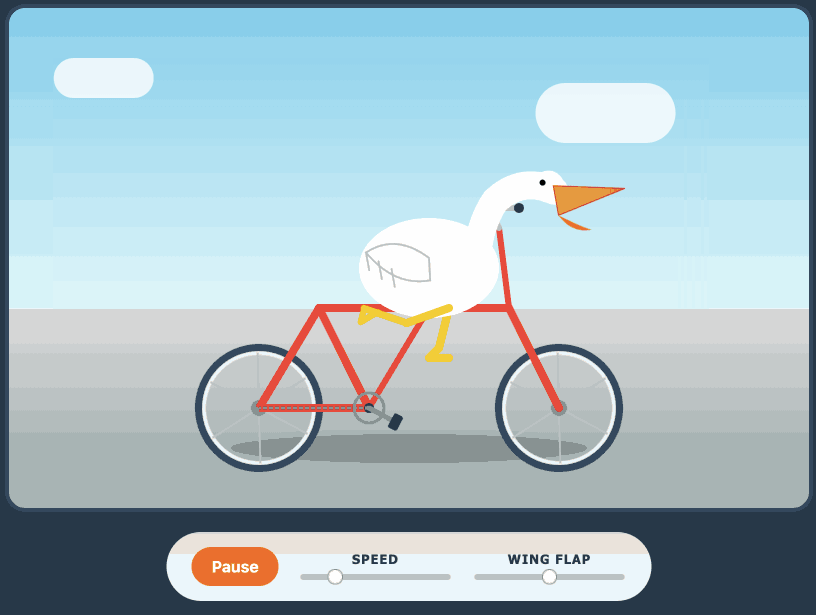
Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7
For anyone who has been (inadvisably) taking my pelican riding a bicycle benchmark seriously as a robust way to test models, here are pelicans from this morning’s two big model releases—Qwen3.6-35B-A3B from Alibaba and Claude Opus 4.7 from Anthropic.
[... 602 words]Meta’s new model is Muse Spark, and meta.ai chat has some interesting tools

Meta announced Muse Spark today, their first model release since Llama 4 almost exactly a year ago. It’s hosted, not open weights, and the API is currently “a private API preview to select users”, but you can try it out today on meta.ai (Facebook or Instagram login required).
[... 2,607 words]GLM-5.1: Towards Long-Horizon Tasks. Chinese AI lab Z.ai's latest model is a giant 754B parameter 1.51TB (on Hugging Face) MIT-licensed monster - the same size as their previous GLM-5 release, and sharing the same paper.
It's available via OpenRouter so I asked it to draw me a pelican:
llm install llm-openrouter
llm -m openrouter/z-ai/glm-5.1 'Generate an SVG of a pelican on a bicycle'
And something new happened... unprompted, the model decided to give me an HTML page that included both the SVG and a separate set of CSS animations!
The SVG was excellent, and might be my new favorite from an open weights model:

But the animation broke it:

That's the pelican, floating up in the top left corner.
I usually don't do follow-up prompts for the pelican test, but in this case I made an exception:
llm -c 'the animation is a bit broken, the pelican ends up positioned off the screen at the top right'
GLM 5.1 replied:
The issue is that CSS
transformanimations on SVG elements override the SVGtransformattribute used for positioning, causing the pelican to lose its placement and fly off to the top-right. The fix is to separate positioning (SVG attribute) from animation (inner group) and use<animateTransform>for SVG rotations since it handles coordinate systems correctly.
And spat out fresh HTML which fixed the problem!

I particularly like the animation of the beak, which is described in the SVG comments like so:
<!-- Pouch (lower beak) with wobble -->
<g>
<path d="M42,-58 Q43,-50 48,-42 Q55,-35 62,-38 Q70,-42 75,-60 L42,-58 Z" fill="url(#pouchGrad)" stroke="#b06008" stroke-width="1" opacity="0.9"/>
<path d="M48,-50 Q55,-46 60,-52" fill="none" stroke="#c06a08" stroke-width="0.8" opacity="0.6"/>
<animateTransform attributeName="transform" type="scale"
values="1,1; 1.03,0.97; 1,1" dur="0.75s" repeatCount="indefinite"
additive="sum"/>
</g>Update: On Bluesky @charles.capps.me suggested a "NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER" and...

The HTML+SVG comments on that one include /* Earring sparkle */, <!-- Opossum fur gradient -->, <!-- Distant treeline silhouette - Virginia pines -->, <!-- Front paw on handlebar --> - here's the transcript and the HTML result.
Gemma 4: Byte for byte, the most capable open models. Four new vision-capable Apache 2.0 licensed reasoning LLMs from Google DeepMind, sized at 2B, 4B, 31B, plus a 26B-A4B Mixture-of-Experts.
Google emphasize "unprecedented level of intelligence-per-parameter", providing yet more evidence that creating small useful models is one of the hottest areas of research right now.
They actually label the two smaller models as E2B and E4B for "Effective" parameter size. The system card explains:
The smaller models incorporate Per-Layer Embeddings (PLE) to maximize parameter efficiency in on-device deployments. Rather than adding more layers or parameters to the model, PLE gives each decoder layer its own small embedding for every token. These embedding tables are large but are only used for quick lookups, which is why the effective parameter count is much smaller than the total.
I don't entirely understand that, but apparently that's what the "E" in E2B means!
One particularly exciting feature of these models is that they are multi-modal beyond just images:
Vision and audio: All models natively process video and images, supporting variable resolutions, and excelling at visual tasks like OCR and chart understanding. Additionally, the E2B and E4B models feature native audio input for speech recognition and understanding.
I've not figured out a way to run audio input locally - I don't think that feature is in LM Studio or Ollama yet.
I tried them out using the GGUFs for LM Studio. The 2B (4.41GB), 4B (6.33GB) and 26B-A4B (17.99GB) models all worked perfectly, but the 31B (19.89GB) model was broken and spat out "---\n" in a loop for every prompt I tried.
The succession of pelican quality from 2B to 4B to 26B-A4B is notable:
E2B:
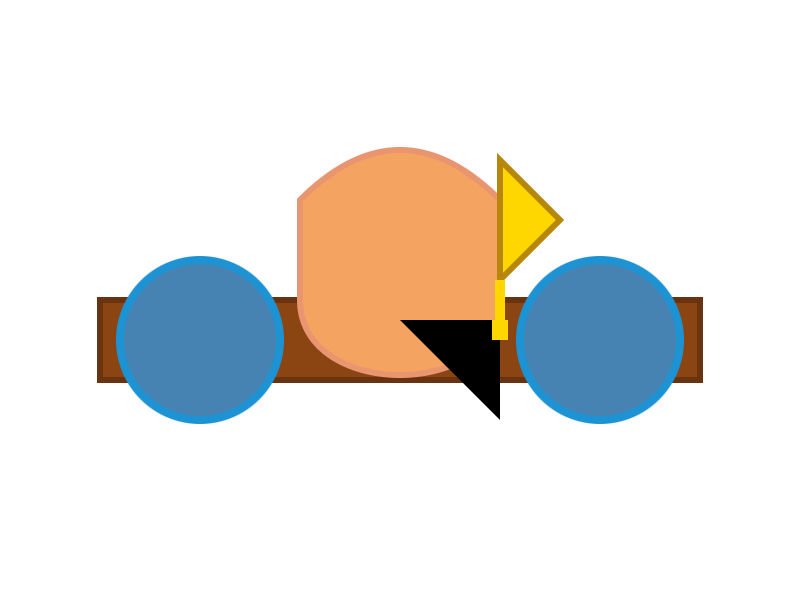
E4B:
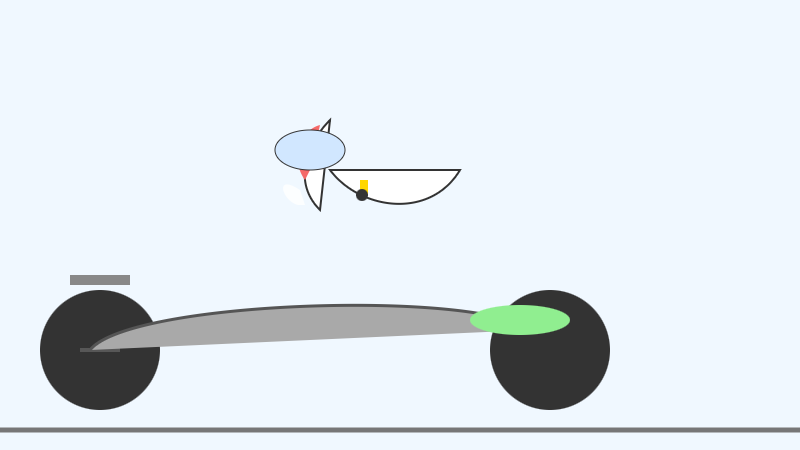
26B-A4B:

(This one actually had an SVG error - "error on line 18 at column 88: Attribute x1 redefined" - but after fixing that I got probably the best pelican I've seen yet from a model that runs on my laptop.)
Google are providing API access to the two larger Gemma models via their AI Studio. I added support to llm-gemini and then ran a pelican through the 31B model using that:
llm -m gemini/gemma-4-31b-it 'Generate an SVG of a pelican riding a bicycle'
Pretty good, though it is missing the front part of the bicycle frame:

GPT-5.4 mini and GPT-5.4 nano, which can describe 76,000 photos for $52
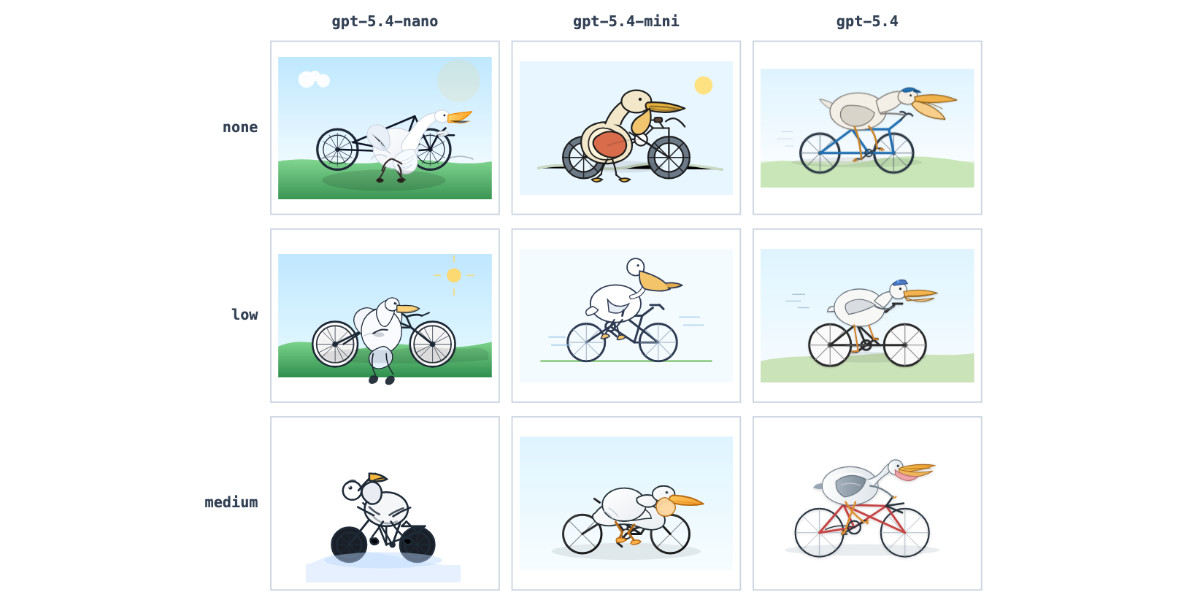
OpenAI today: Introducing GPT‑5.4 mini and nano. These models join GPT-5.4 which was released two weeks ago.
[... 719 words]Introducing Mistral Small 4. Big new release from Mistral today (despite the name) - a new Apache 2 licensed 119B parameter (Mixture-of-Experts, 6B active) model which they describe like this:
Mistral Small 4 is the first Mistral model to unify the capabilities of our flagship models, Magistral for reasoning, Pixtral for multimodal, and Devstral for agentic coding, into a single, versatile model.
It supports reasoning_effort="none" or reasoning_effort="high", with the latter providing "equivalent verbosity to previous Magistral models".
The new model is 242GB on Hugging Face.
I tried it out via the Mistral API using llm-mistral:
llm install llm-mistral
llm mistral refresh
llm -m mistral/mistral-small-2603 "Generate an SVG of a pelican riding a bicycle"

I couldn't find a way to set the reasoning effort in their API documentation, so hopefully that's a feature which will land soon.
Update 23rd March: Here's new documentation for the reasoning_effort parameter.
Also from Mistral today and fitting their -stral naming convention is Leanstral, an open weight model that is specifically tuned to help output the Lean 4 formally verifiable coding language. I haven't explored Lean at all so I have no way to credibly evaluate this, but it's interesting to see them target one specific language in this way.
Introducing GPT‑5.4. Two new API models: gpt-5.4 and gpt-5.4-pro, also available in ChatGPT and Codex CLI. August 31st 2025 knowledge cutoff, 1 million token context window. Priced slightly higher than the GPT-5.2 family with a bump in price for both models if you go above 272,000 tokens.
5.4 beats coding specialist GPT-5.3-Codex on all of the relevant benchmarks. I wonder if we'll get a 5.4 Codex or if that model line has now been merged into main?
Given Claude's recent focus on business applications it's interesting to see OpenAI highlight this in their announcement of GPT-5.4:
We put a particular focus on improving GPT‑5.4’s ability to create and edit spreadsheets, presentations, and documents. On an internal benchmark of spreadsheet modeling tasks that a junior investment banking analyst might do, GPT‑5.4 achieves a mean score of 87.3%, compared to 68.4% for GPT‑5.2.
Here's a pelican on a bicycle drawn by GPT-5.4:

And here's one by GPT-5.4 Pro, which took 4m45s and cost me $1.55:

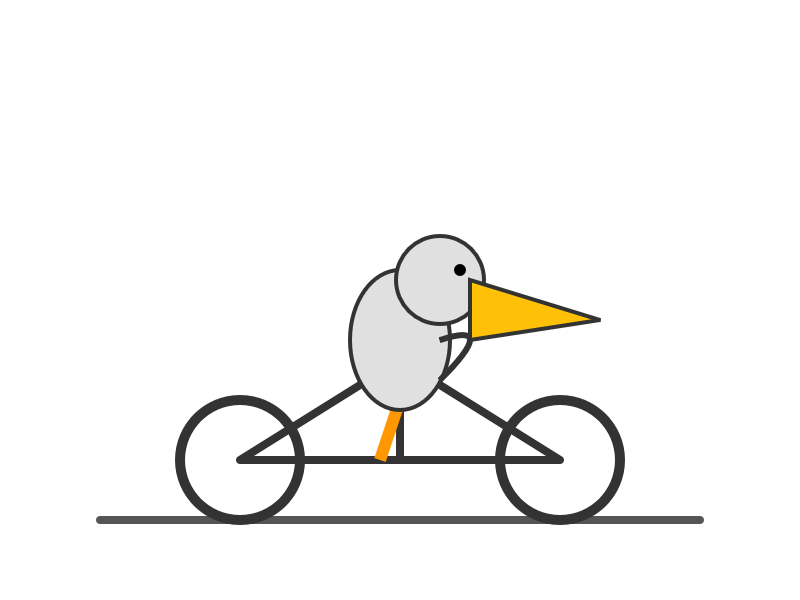
Gemini 3.1 Flash-Lite. Google's latest model is an update to their inexpensive Flash-Lite family. At $0.25/million tokens of input and $1.5/million output this is 1/8th the price of Gemini 3.1 Pro.
It supports four different thinking levels, so I had it output four different pelicans:

minimal

low

medium
{kind=link}
{kind=link}
{kind=link}
high