3rd June 2025 - Link Blog
Shisa V2 405B: Japan’s Highest Performing LLM. Leonard Lin and Adam Lensenmayer have been working on Shisa for a while. They describe their latest release as "Japan's Highest Performing LLM".
Shisa V2 405B is the highest-performing LLM ever developed in Japan, and surpasses GPT-4 (0603) and GPT-4 Turbo (2024-04-09) in our eval battery. (It also goes toe-to-toe with GPT-4o (2024-11-20) and DeepSeek-V3 (0324) on Japanese MT-Bench!)
This 405B release is a follow-up to the six smaller Shisa v2 models they released back in April, which took a similar approach to DeepSeek-R1 in producing different models that each extended different existing base model from Llama, Qwen, Mistral and Phi-4.
The new 405B model uses Llama 3.1 405B Instruct as a base, and is available under the Llama 3.1 community license.
Shisa is a prominent example of Sovereign AI - the ability for nations to build models that reflect their own language and culture:
We strongly believe that it’s important for homegrown AI to be developed both in Japan (and globally!), and not just for the sake of cultural diversity and linguistic preservation, but also for data privacy and security, geopolitical resilience, and ultimately, independence.
We believe the open-source approach is the only realistic way to achieve sovereignty in AI, not just for Japan, or even for nation states, but for the global community at large.
The accompanying overview report has some fascinating details:
Training the 405B model was extremely difficult. Only three other groups that we know of: Nous Research, Bllossom, and AI2 have published Llama 405B full fine-tunes. [...] We implemented every optimization at our disposal including: DeepSpeed ZeRO-3 parameter and activation offloading, gradient accumulation, 8-bit paged optimizer, and sequence parallelism. Even so, the 405B model still barely fit within the H100’s memory limits
In addition to the new model the Shisa team have published shisa-ai/shisa-v2-sharegpt, 180,000 records which they describe as "a best-in-class synthetic dataset, freely available for use to improve the Japanese capabilities of any model. Licensed under Apache 2.0".
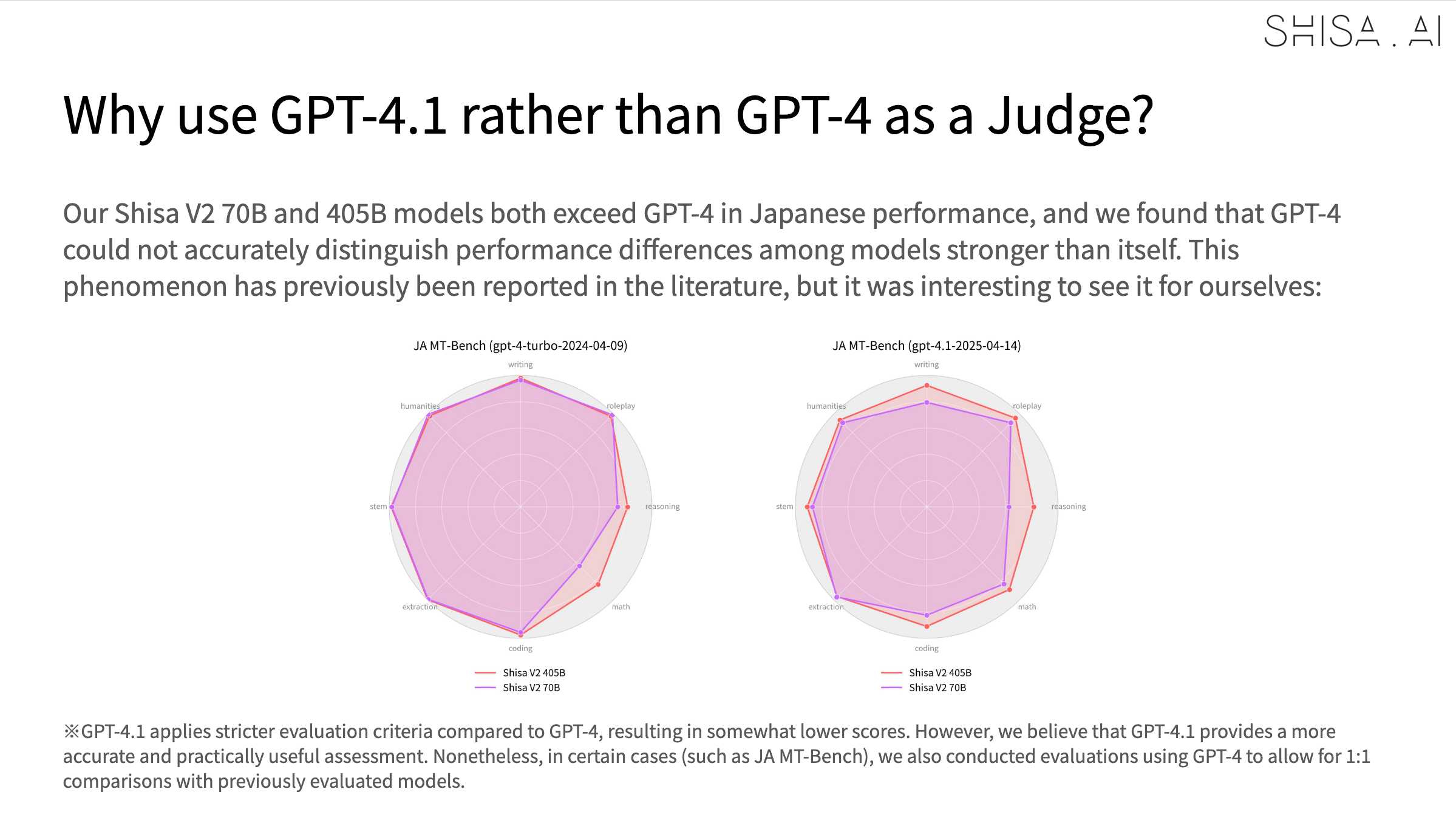
An interesting note is that they found that since Shisa out-performs GPT-4 at Japanese that model was no longer able to help with evaluation, so they had to upgrade to GPT-4.1:
Recent articles
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026
- Thoughts on OpenAI acquiring Astral and uv/ruff/ty - 19th March 2026