Building software on top of Large Language Models
15th May 2025
I presented a three hour workshop at PyCon US yesterday titled Building software on top of Large Language Models. The goal of the workshop was to give participants everything they needed to get started writing code that makes use of LLMs.
Most of the workshop was interactive: I created a detailed handout with six different exercises, then worked through them with the participants. You can access the handout here—it should be comprehensive enough that you can follow along even without having been present in the room.
Here’s the table of contents for the handout:
- Setup—getting LLM and related tools installed and configured for accessing the OpenAI API
- Prompting with LLM—basic prompting in the terminal, including accessing logs of past prompts and responses
- Prompting from Python—how to use LLM’s Python API to run prompts against different models from Python code
- Building a text to SQL tool—the first building exercise: prototype a text to SQL tool with the LLM command-line app, then turn that into Python code.
- Structured data extraction—possibly the most economically valuable application of LLMs today
- Semantic search and RAG—working with embeddings, building a semantic search engine
- Tool usage—the most important technique for building interesting applications on top of LLMs. My LLM tool gained tool usage in an alpha release just the night before the workshop!
Some sections of the workshop involved me talking and showing slides. I’ve gathered those together into an annotated presentation below.
The workshop was not recorded, but hopefully these materials can provide a useful substitute. If you’d like me to present a private version of this workshop for your own team please get in touch!
{kind=link}

{kind=link}
The full handout for the workshop parts of this talk can be found at building-with-llms-pycon-2025.readthedocs.io.
{kind=link}
I recommended anyone who didn’t have a stable Python 3 environment that they could install packages should use Codespaces instead, using github.com/pamelafox/python-3.13-playground.
I used this myself throughout the presentation. I really like Codespaces for workshops as it removes any risk of broken environments spoiling the experience for someone: if your Codespace breaks you can throw it away and click the button to get a new one.

{kind=link}
I started out with a short review of the landscape as I see it today.

{kind=link}
If you have limited attention, I think these are the three to focus on.
OpenAI created the space and are still innovating on a regular basis—their GPT 4.1 family is just a month old and is currently one of my favourite balances of power to cost. o4-mini is an excellent reasoning model, especially for its price.
Gemini started producing truly outstanding models with the 1.5 series, and 2.5 may be the best available models for a wide range of purposes.
Anthropic’s Claude has long been one of my favourite models. I’m looking forward to their next update.

{kind=link}
There are a wide range of “open weights” (usually a more accurate term than “open source”) models available, and they’ve been getting really good over the past six months. These are the model families I’ve been particularly impressed by. All of these include models I have successfully run on my 64GB M2 laptop.

{kind=link}
I wrote about this in my review of LLMs in 2024: 18 labs have now produced what I would consider a GPT-4 class model, and there may well be some that I’ve missed.

{kind=link}
These models can “see” now—their vision input has gotten really good. The Gemini family can handle audio and video input too.
We’re beginning to see audio and image output start to emerge—OpenAI have been a leader here, but Gemini offers this too and other providers are clearly working in the same direction. Qwen have an open weights model for this, Qwen 2.5 Omni (audio output).

{kind=link}
The point here is really that we are spoiled for choice when it comes to models. The rate at which new ones are released is somewhat bewildering.
{kind=link}
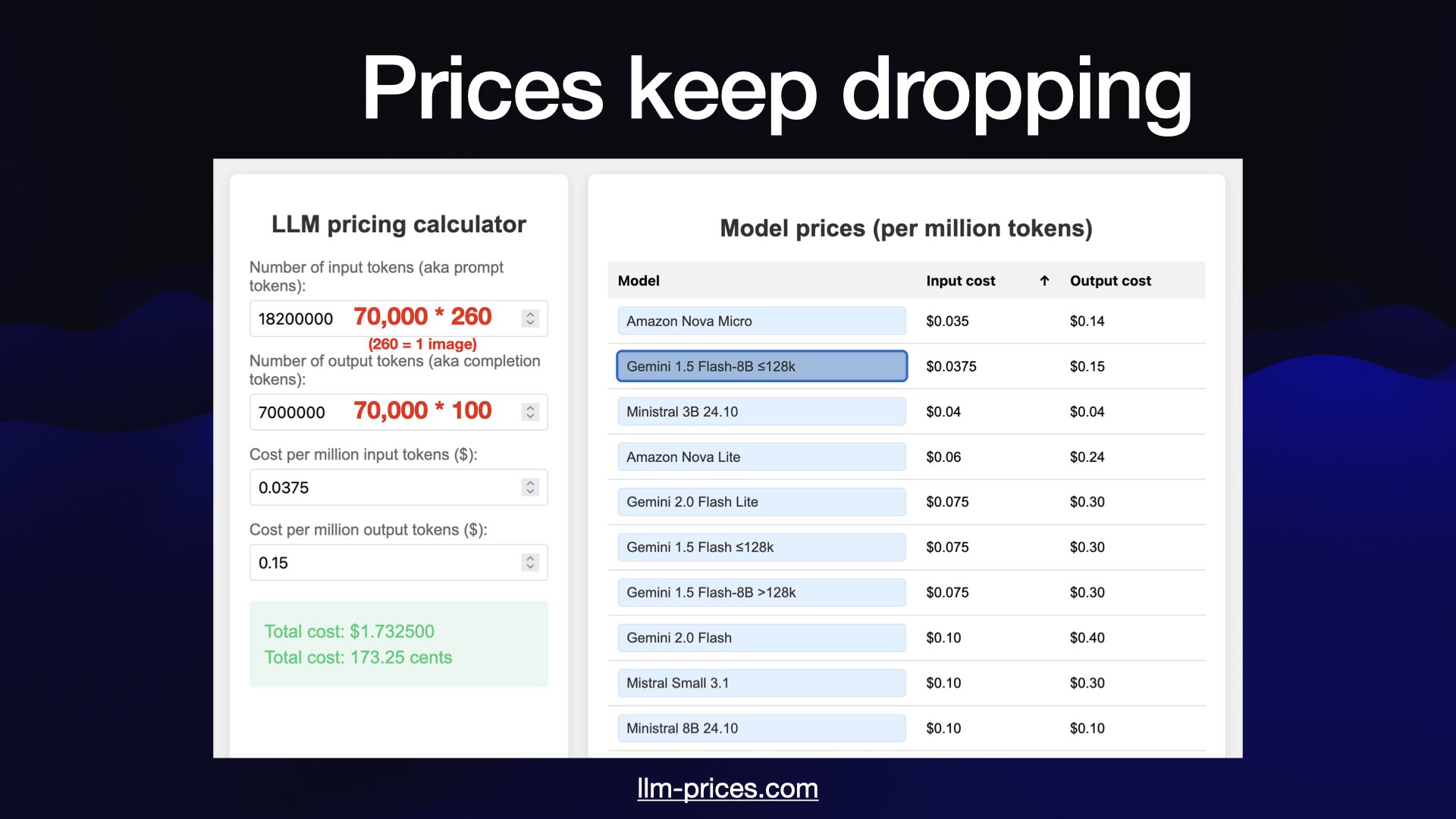
The models have got so cheap. By my estimate the total cost to generate ~100 token descriptions of all 70,000 images in my personal photo library with Gemini 1.5 Flash 8B is 173.25 cents.

{kind=link}
... there are some expensive models too! The same 70,000 images through GPT-4.5, priced at $75/million input tokens, would cost at least $2,400.
Though honestly if you had told me a few years ago that I could get descriptions for 70,000 photos for $2,400 I would still have been pretty impressed.

{kind=link}
I’ve heard from sources I trust that Gemini and AWS (for their Nova series, priced similar to Gemini models) are not charging less per prompt than the energy it costs to serve them.
This makes the prompt pricing one of the better signals we have as to the environmental impact of running those prompts.
I’ve seen estimates that training costs, amortized over time, likely add 10-15% to that cost—so it’s still a good hint at the overall energy usage.

{kind=link}
Ethan Mollick coined the term “jagged frontier” to describe the challenge of figuring out what these models are useful for. They’re great at some things, terrible at others but it’s very non-obvious which things are which!

{kind=link}
My recommendation is to try them out. Keep throwing things at them, including things you’re sure they won’t be able to handle. Their failure patterns offer useful lessons.
If a model can’t do something it’s good to tuck that away and try it again in six months—you may find that the latest generation of models can solve a new problem for you.
As the author of an abstraction toolkit across multiple models (LLM) I’m biased towards arguing it’s good to be able to switch between them, but I genuinely believe it’s a big advantage to be able to do so.

{kind=link}
At this point we started working through these sections of the handout:
- Setup—getting LLM installed and configured
- Prompting with LLM—running prompts in the terminal, accessing logs, piping in content, using system prompts and attachments and fragments.
- Building a text to SQL tool—building a system on top of LLMs that can take a user’s question and turn it into a SQL query based on the database schema
- Structured data extraction—possibly the most economically valuable application of LLMs right now: using them for data entry from unstructured or messy sources

{kind=link}
When we got to the Semantic search and RAG section I switched back to slides to provide a little bit of background on vector embeddings.
This explanation was adapted from my PyBay workshop and article Embeddings: What they are and why they matter

{kind=link}
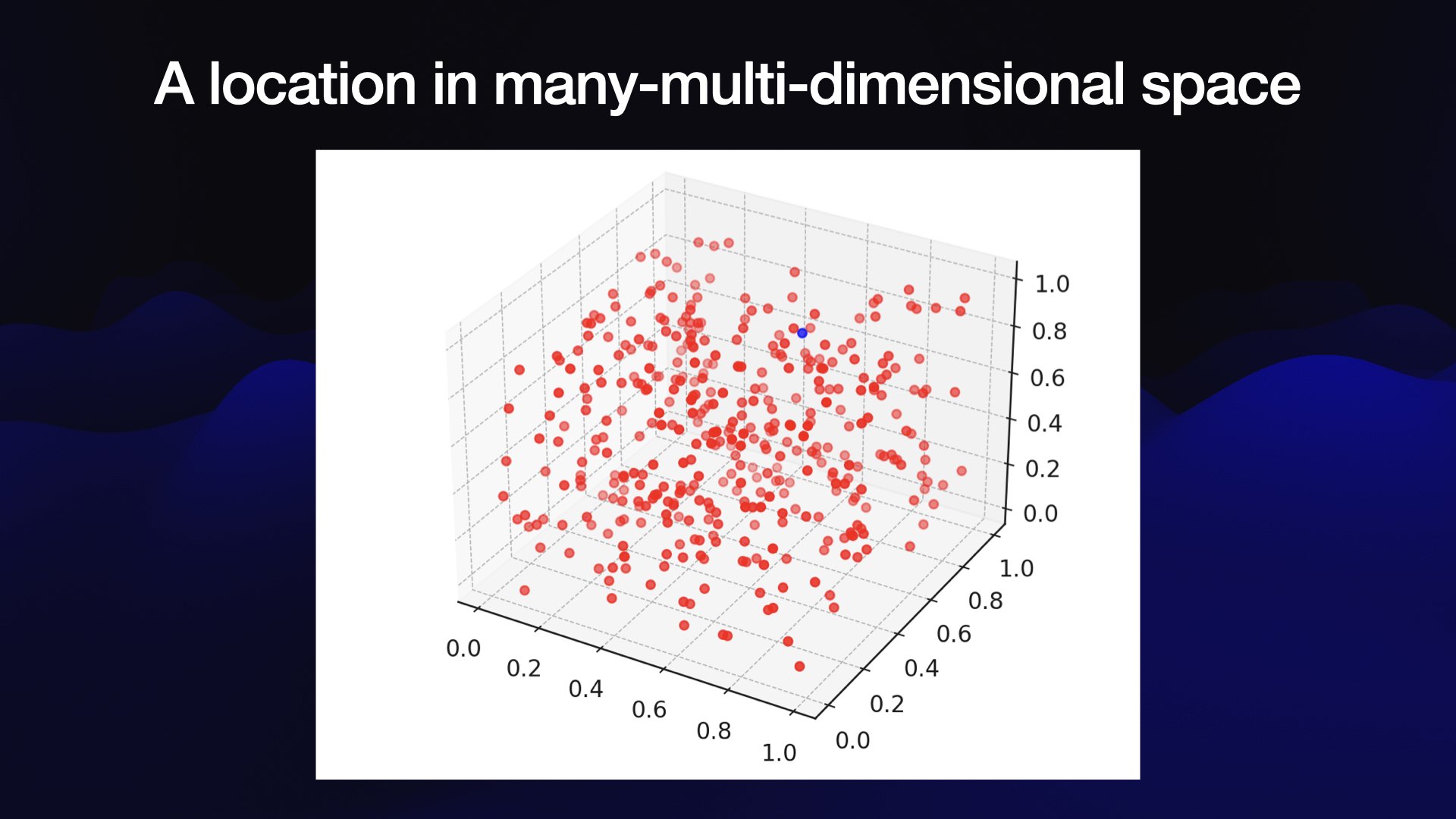
The key thing to understand about vector embeddings is that they are a technique for taking a chunk of text and turning that into a fixed length sequence of floating pount numbers that attempt to capture something about the semantic meaning of that text.
{kind=link}
These vectors are interesting purely because they let us see what else is nearby in weird 1536-dimension space.
If it was 3 dimensions we’d find it a lot easier to visualize!

{kind=link}
My TIL website uses vector embeddings for related content, and it often works really well.
I wrote about how that’s implemented in a TIL, Storing and serving related documents with openai-to-sqlite and embeddings.

{kind=link}
This is also a key method for implementing semantic search—search which returns documents that are related to the user’s search term even if none of the keywords were an exact match.
One way to do this is to embed the user’s search term and find similar documents—but this doesn’t always work great, since a short question might not end up in the same location as a much longer article.
There are neat tricks here that can help.
Some models allow you to embed questions and answers in different ways that cause them to end up closer to each other. Nomic Embed Text v2 is a recent example.
A neat trick is you can ask an LLM to entirely synthesize a potential answer to the user’s question—then embed that artificial answer and find your own content that’s nearby in vector space!
We worked through the next section of the workshop together:
Semantic search and RAG—we gathered embeddings for Python PEPs and built a semantic search engine against them using LLM’s command-line utilities and a Bash script.
I described RAG—Retrieval-Augmented Generation—the pattern where you try to find documentsv relevant to the user’s question and dump those into the prompt.
I emphasized that RAG doesn’t have to use embeddings: you can build a great RAG system on top of full-text keyword-based search as well. You can also combine the two in a hybrid search system.
I argued that every time a new long context model comes out people inevitably argue that “RAG is dead”. I don’t think long context will ever kill RAG—no matter how long your context you’ll still have more data than can fit in it. But I do think that LLM tool calling for search, especially as demonstrated by o3 and o4-mini, is a better approach than classic RAG where you try once to find relevant documents and then attempt to answer the question without looping.
The next section of the workshop had no slides but is the section I was most excited about: tool usage.
I talked through the pattern where LLMs can call tools and introduced the brand new tool functionality I added to LLM in the latest alpha release.

{kind=link}
I can’t talk about LLMs calling tools without getting into prompt injection and LLM security.

{kind=link}
See Prompt injection and jailbreaking are not the same thing for an expanded version of this argument.

{kind=link}
This is still my favorite jailbreak of all time—the Grandma who worked in a napalm factory attack. It’s a couple of years old now so it probably doesn’t work any more.

{kind=link}
Jailbreaking is about attacking a model. The models aren’t supposed to tell you how to create napalm. It’s on the model providers—OpenAI, Anthropic, Gemini—to prevent them from doing that.
Prompt injection attacks are against the applications that we are building on top of LLMs. That’s why I care about them so much.
Prompt injection explained, with video, slides, and a transcript is a longer explanation of this attack.

{kind=link}
Having just talked about LLMs with tools, prompt injection is even more important to discuss.
If tools can do things on your behalf, it’s vitally important that an attacker can’t sneak some instructions to your LLM assistant such that it does things on their behalf instead.

{kind=link}
Here’s a classic hypothetical challenge. If I have an AI assistant called Marvin who can interact with my emails on my behalf, what’s to stop it from acting on an email that an attacker sends it telling it to steal my password resets?
We still don’t have a great way to guarantee that this won’t work!

{kind=link}
Many people suggest AI-based filtering for these attacks that works 99% of the time.
In web application security 99% is not good enough. Imagine if we protected aganist SQL injection with an approach that failed 1/100 times?

{kind=link}
I proposed a potential solution for this two years ago in The Dual LLM pattern for building AI assistants that can resist prompt injection.

{kind=link}
The key idea is to have a privileged LLM that runs tools and interacts with the user but is never exposed to tokens from an untrusted source, and a quarantined LLM that sees that stuff and can perform actions such as summarization.
Untrusted tokens, or processed summaries of untrusted tokens, are never sent to the priviledged LLM. It instead can handle variable names like SUMMARY1 and direct those to be shown to the user.

{kind=link}
Last month Google DeepMind put out a paper, Defeating Prompt Injections by Design, which offered the first approach to this problem that really looked to me like it might work.
I wrote more about this in CaMeL offers a promising new direction for mitigating prompt injection attacks.

{kind=link}
I’m biased though, because the paper explained a much improved and expanded version of my Dual LLMs pattern.
I’m also delighted that the sentence “Is Dual LLM of Willison enough?” showed up in paper from DeepMind!
(Spoiler: it was not enough.)

{kind=link}
Evals are the LLM equivalent of unit tests: automated tests that help you tell how well your system is working.
Unfortunately LLMs are non-deterministic, so traditional unit tests don’t really work.
If you’re lucky you might be able to develop a suite of questions that can be evaluated on correct or incorrect answers—examples of emails that should be flagged as spam, for example.
More creative tasks are harder to evaluate. How can you tell if your LLM system that creates vegetarian cheesecake recipes is doing a good job? Or more importantly if tweaks you made to the prompt cause it to do a better or worse job?
LLM as a judge is a pattern that can help here—carefully prompting an LLM during your evaluation runs to help decide if an answer is better.
This whole area continues to be one of the hardest to crack—but also one of the most valuable. Having a great eval suite for your own application domain is a huge competitive advantage—it means you can adopt more models and iterate on your prompts with much more confidence.
I’ve collected a bunch of notes in my evals tag. I strongly recommend Hamel Husain’s writing on this topic, in particular:
I finished the workshop by running a few demos of local models running on my machine using Ollama and the llm-ollama plugin. I showed mistral-small3.1 and qwen3:4b, an astonishingly capable model given its 2.6GB size on disk. I wrote more about Qwen 3 4B here.

If your company would like a private version of this workshop, delivered via Zoom/Google Chat/Teams/Your conferencing app of your choice, please get in touch. You can contact me at my contact@simonwillison.net.
More recent articles
- Meta's new model is Muse Spark, and meta.ai chat has some interesting tools - 8th April 2026
- Anthropic's Project Glasswing - restricting Claude Mythos to security researchers - sounds necessary to me - 7th April 2026
- The Axios supply chain attack used individually targeted social engineering - 3rd April 2026