Thursday, 8th May 2025
llm-gemini 0.19.1.
Bugfix release for my llm-gemini plugin, which was recording the number of output tokens (needed to calculate the price of a response) incorrectly for the Gemini "thinking" models. Those models turn out to return candidatesTokenCount and thoughtsTokenCount as two separate values which need to be added together to get the total billed output token count. Full details in this issue.
I spotted this potential bug in this response log this morning, and my concerns were confirmed when Paul Gauthier wrote about a similar fix in Aider in Gemini 2.5 Pro Preview 03-25 benchmark cost, where he noted that the $6.32 cost recorded to benchmark Gemini 2.5 Pro Preview 03-25 was incorrect. Since that model is no longer available (despite the date-based model alias persisting) Paul is not able to accurately calculate the new cost, but it's likely a lot more since the Gemini 2.5 Pro Preview 05-06 benchmark cost $37.
I've gone through my gemini tag and attempted to update my previous posts with new calculations - this mostly involved increases in the order of 12.336 cents to 16.316 cents (as seen here).
But I’ve also had my own quiet concerns about what [vibe coding] means for early-career developers. So much of how I learned came from chasing bugs in broken tutorials and seeing how all the pieces connected, or didn’t. There was value in that. And maybe I’ve been a little protective of it.
A mentor challenged that. He pointed out that debugging AI generated code is a lot like onboarding into a legacy codebase, making sense of decisions you didn’t make, finding where things break, and learning to trust (or rewrite) what’s already there. That’s the kind of work a lot of developers end up doing anyway.
— Ashley Willis, What Even Is Vibe Coding?
Microservices only pay off when you have real scaling bottlenecks, large teams, or independently evolving domains. Before that? You’re paying the price without getting the benefit: duplicated infra, fragile local setups, and slow iteration.
— Oleg Pustovit, Microservices Are a Tax Your Startup Probably Can’t Afford
Reservoir Sampling (via) Yet another outstanding interactive essay by Sam Rose (previously), this time explaining how reservoir sampling can be used to select a "fair" random sample when you don't know how many options there are and don't want to accumulate them before making a selection.
Reservoir sampling is one of my favourite algorithms, and I've been wanting to write about it for years now. It allows you to solve a problem that at first seems impossible, in a way that is both elegant and efficient.
I appreciate that Sam starts the article with "No math notation, I promise." Lots of delightful widgets to interact with here, all of which help build an intuitive understanding of the underlying algorithm.
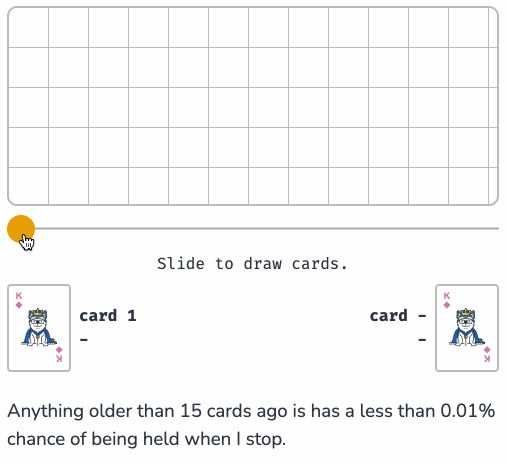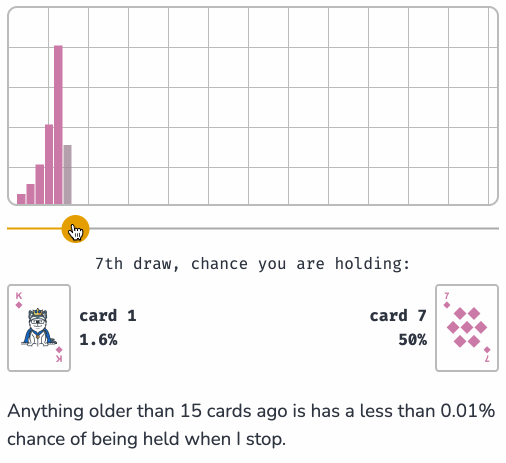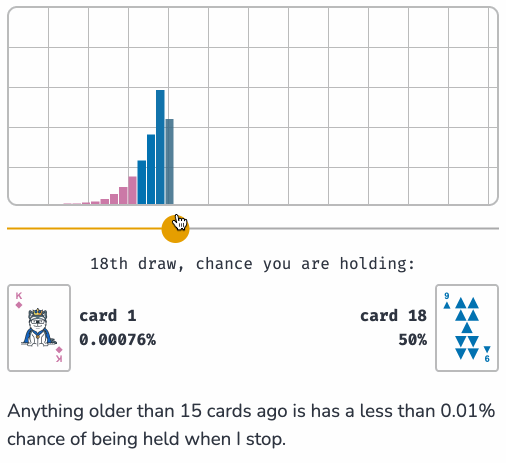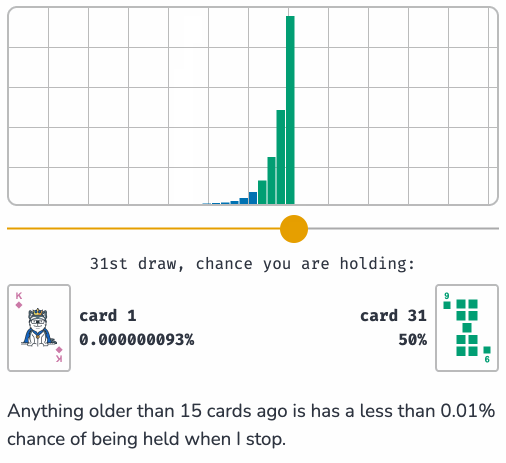
Sam shows how this algorithm can be applied to the real-world problem of sampling log files when incoming logs threaten to overwhelm a log aggregator.
The dog illustration is commissioned art and the MIT-licensed code is available on GitHub.
If Claude is asked to count words, letters, and characters, it thinks step by step before answering the person. It explicitly counts the words, letters, or characters by assigning a number to each. It only answers the person once it has performed this explicit counting step. [...]
If Claude is shown a classic puzzle, before proceeding, it quotes every constraint or premise from the person’s message word for word before inside quotation marks to confirm it’s not dealing with a new variant. [...]
If asked to write poetry, Claude avoids using hackneyed imagery or metaphors or predictable rhyming schemes.
— Claude's system prompt, via Drew Breunig
SQLite CREATE TABLE: The DEFAULT clause. If your SQLite create table statement includes a line like this:
CREATE TABLE alerts (
-- ...
alert_created_at text default current_timestamp
)
current_timestamp will be replaced with a UTC timestamp in the format 2025-05-08 22:19:33. You can also use current_time for HH:MM:SS and current_date for YYYY-MM-DD, again using UTC.
Posting this here because I hadn't previously noticed that this defaults to UTC, which is a useful detail. It's also a strong vote in favor of YYYY-MM-DD HH:MM:SS as a string format for use with SQLite, which doesn't otherwise provide a formal datetime type.