Monday, 9th February 2026
AI Doesn’t Reduce Work—It Intensifies It (via) Aruna Ranganathan and Xingqi Maggie Ye from Berkeley Haas School of Business report initial findings in the HBR from their April to December 2025 study of 200 employees at a "U.S.-based technology company".
This captures an effect I've been observing in my own work with LLMs: the productivity boost these things can provide is exhausting.
AI introduced a new rhythm in which workers managed several active threads at once: manually writing code while AI generated an alternative version, running multiple agents in parallel, or reviving long-deferred tasks because AI could “handle them” in the background. They did this, in part, because they felt they had a “partner” that could help them move through their workload.
While this sense of having a “partner” enabled a feeling of momentum, the reality was a continual switching of attention, frequent checking of AI outputs, and a growing number of open tasks. This created cognitive load and a sense of always juggling, even as the work felt productive.
I'm frequently finding myself with work on two or three projects running parallel. I can get so much done, but after just an hour or two my mental energy for the day feels almost entirely depleted.
I've had conversations with people recently who are losing sleep because they're finding building yet another feature with "just one more prompt" irresistible.
The HBR piece calls for organizations to build an "AI practice" that structures how AI is used to help avoid burnout and counter effects that "make it harder for organizations to distinguish genuine productivity gains from unsustainable intensity".
I think we've just disrupted decades of existing intuition about sustainable working practices. It's going to take a while and some discipline to find a good new balance.
Structured Context Engineering for File-Native Agentic Systems (via) New paper by Damon McMillan exploring challenging LLM context tasks involving large SQL schemas (up to 10,000 tables) across different models and file formats:
Using SQL generation as a proxy for programmatic agent operations, we present a systematic study of context engineering for structured data, comprising 9,649 experiments across 11 models, 4 formats (YAML, Markdown, JSON, Token-Oriented Object Notation [TOON]), and schemas ranging from 10 to 10,000 tables.
Unsurprisingly, the biggest impact was the models themselves - with frontier models (Opus 4.5, GPT-5.2, Gemini 2.5 Pro) beating the leading open source models (DeepSeek V3.2, Kimi K2, Llama 4).
Those frontier models benefited from filesystem based context retrieval, but the open source models had much less convincing results with those, which reinforces my feeling that the filesystem coding agent loops aren't handled as well by open weight models just yet. The Terminal Bench 2.0 leaderboard is still dominated by Anthropic, OpenAI and Gemini.
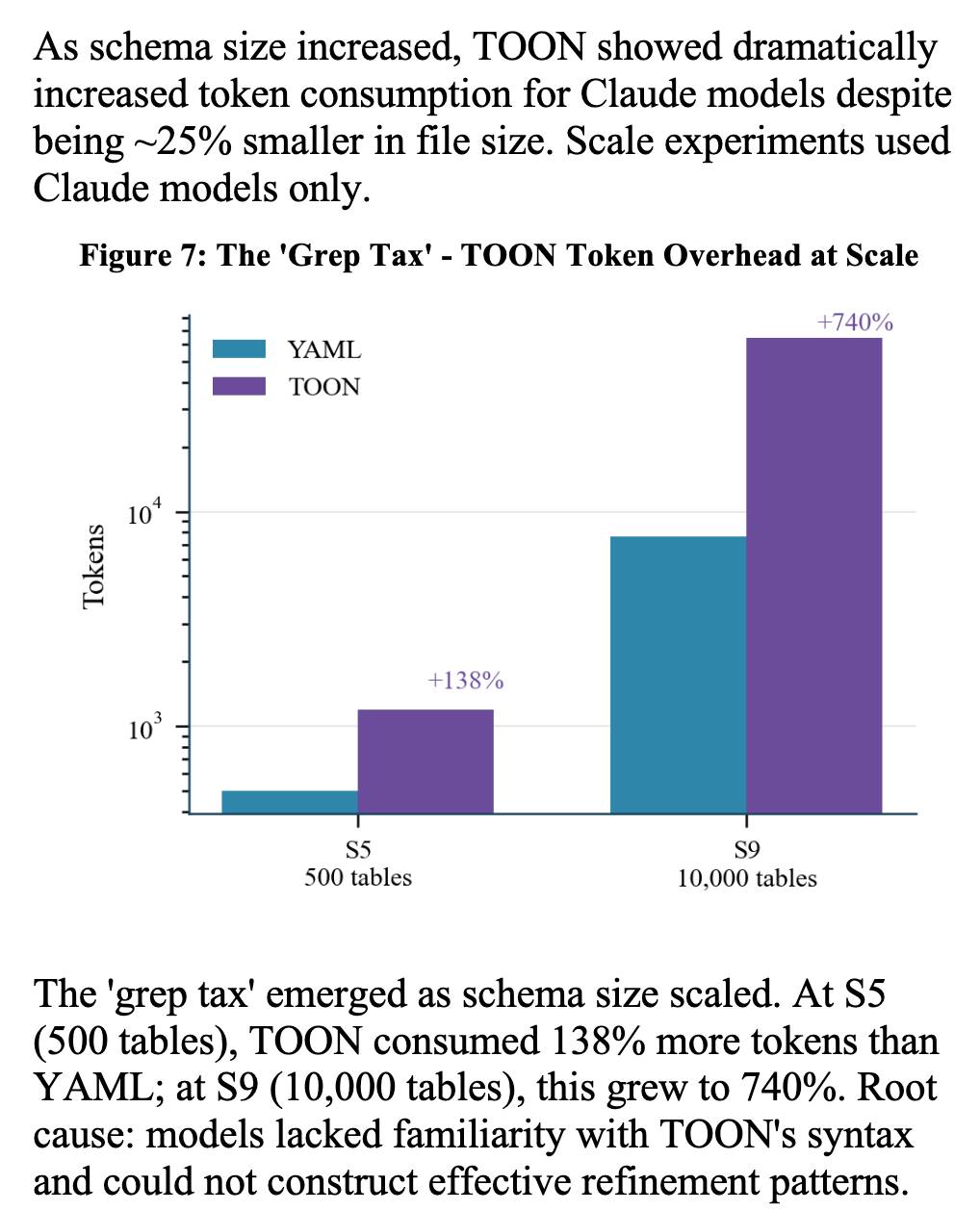
The "grep tax" result against TOON was an interesting detail. TOON is meant to represent structured data in as few tokens as possible, but it turns out the model's unfamiliarity with that format led to them spending significantly more tokens over multiple iterations trying to figure it out: