25th December 2024 - Link Blog
deepseek-ai/DeepSeek-V3-Base (via) No model card or announcement yet, but this new model release from Chinese AI lab DeepSeek (an arm of Chinese hedge fund High-Flyer) looks very significant.
It's a huge model - 685B parameters, 687.9 GB on disk (TIL how to size a git-lfs repo). The architecture is a Mixture of Experts with 256 experts, using 8 per token.
For comparison, Meta AI's largest released model is their Llama 3.1 model with 405B parameters.
The new model is apparently available to some people via both chat.deepseek.com and the DeepSeek API as part of a staged rollout.
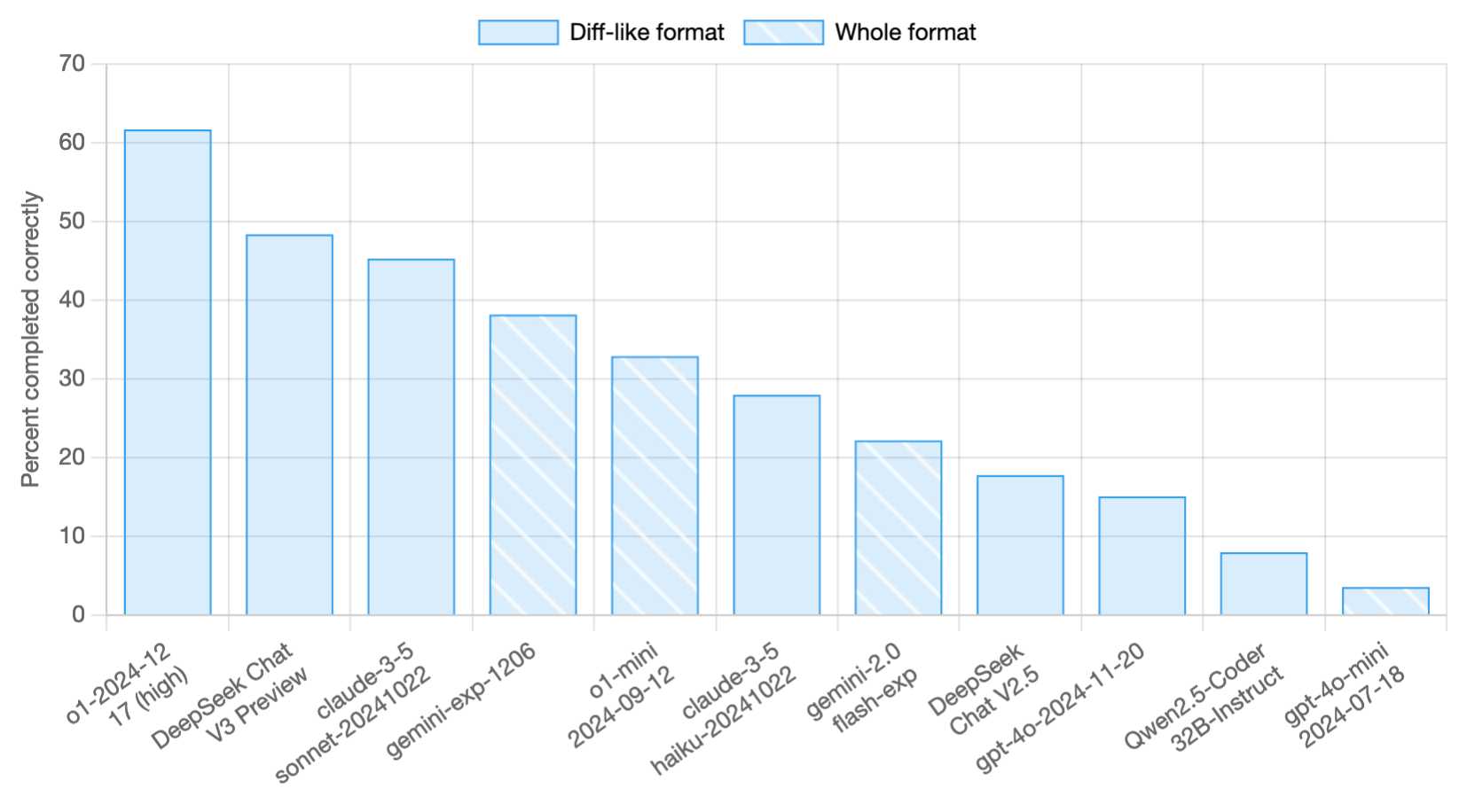
Paul Gauthier got API access and used it to update his new Aider Polyglot leaderboard - DeepSeek v3 preview scored 48.4%, putting it in second place behind o1-2024-12-17 (high) and in front of both claude-3-5-sonnet-20241022 and gemini-exp-1206!
I never know if I can believe models or not (the first time I asked "what model are you?" it claimed to be "based on OpenAI's GPT-4 architecture"), but I just got this result using LLM and the llm-deepseek plugin:
llm -m deepseek-chat 'what deepseek model are you?'
I'm DeepSeek-V3 created exclusively by DeepSeek. I'm an AI assistant, and I'm at your service! Feel free to ask me anything you'd like. I'll do my best to assist you.
Here's my initial experiment log.
Recent articles
- Experimenting with Starlette 1.0 with Claude skills - 22nd March 2026
- Profiling Hacker News users based on their comments - 21st March 2026
- Thoughts on OpenAI acquiring Astral and uv/ruff/ty - 19th March 2026