3 posts tagged “autoresearch”
Coding agents running experiments to find and combine optimizations for interesting problems.
2026
I wrote about Dan Woods' experiments with streaming experts the other day, the trick where you run larger Mixture-of-Experts models on hardware that doesn't have enough RAM to fit the entire model by instead streaming the necessary expert weights from SSD for each token that you process.
Five days ago Dan was running Qwen3.5-397B-A17B in 48GB of RAM. Today @seikixtc reported running the colossal Kimi K2.5 - a 1 trillion parameter model with 32B active weights at any one time, in 96GB of RAM on an M2 Max MacBook Pro.
And @anemll showed that same Qwen3.5-397B-A17B model running on an iPhone, albeit at just 0.6 tokens/second - iOS repo here.
I think this technique has legs. Dan and his fellow tinkerers are continuing to run autoresearch loops in order to find yet more optimizations to squeeze more performance out of these models.
Update: Now Daniel Isaac got Kimi K2.5 working on a 128GB M4 Max at ~1.7 tokens/second.
Autoresearching Apple’s “LLM in a Flash” to run Qwen 397B locally. Here's a fascinating piece of research by Dan Woods, who managed to get a custom version of Qwen3.5-397B-A17B running at 5.5+ tokens/second on a 48GB MacBook Pro M3 Max despite that model taking up 209GB (120GB quantized) on disk.
Qwen3.5-397B-A17B is a Mixture-of-Experts (MoE) model, which means that each token only needs to run against a subset of the overall model weights. These expert weights can be streamed into memory from SSD, saving them from all needing to be held in RAM at the same time.
Dan used techniques described in Apple's 2023 paper LLM in a flash: Efficient Large Language Model Inference with Limited Memory:
This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters in flash memory, but bringing them on demand to DRAM. Our method involves constructing an inference cost model that takes into account the characteristics of flash memory, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks.
He fed the paper to Claude Code and used a variant of Andrej Karpathy's autoresearch pattern to have Claude run 90 experiments and produce MLX Objective-C and Metal code that ran the model as efficiently as possible.
danveloper/flash-moe has the resulting code plus a PDF paper mostly written by Claude Opus 4.6 describing the experiment in full.
The final model has the experts quantized to 2-bit, but the non-expert parts of the model such as the embedding table and routing matrices are kept at their original precision, adding up to 5.5GB which stays resident in memory while the model is running.
Qwen 3.5 usually runs 10 experts per token, but this setup dropped that to 4 while claiming that the biggest quality drop-off occurred at 3.
It's not clear to me how much the quality of the model results are affected. Claude claimed that "Output quality at 2-bit is indistinguishable from 4-bit for these evaluations", but the description of the evaluations it ran is quite thin.
Update: Dan's latest version upgrades to 4-bit quantization of the experts (209GB on disk, 4.36 tokens/second) after finding that the 2-bit version broke tool calling while 4-bit handles that well.
Shopify/liquid: Performance: 53% faster parse+render, 61% fewer allocations (via) PR from Shopify CEO Tobias Lütke against Liquid, Shopify's open source Ruby template engine that was somewhat inspired by Django when Tobi first created it back in 2005.
Tobi found dozens of new performance micro-optimizations using a variant of autoresearch, Andrej Karpathy's new system for having a coding agent run hundreds of semi-autonomous experiments to find new effective techniques for training nanochat.
Tobi's implementation started two days ago with this autoresearch.md prompt file and an autoresearch.sh script for the agent to run to execute the test suite and report on benchmark scores.
The PR now lists 93 commits from around 120 automated experiments. The PR description lists what worked in detail - some examples:
- Replaced StringScanner tokenizer with
String#byteindex. Single-bytebyteindexsearching is ~40% faster than regex-basedskip_until. This alone reduced parse time by ~12%.- Pure-byte
parse_tag_token. Eliminated the costlyStringScanner#string=reset that was called for every{% %}token (878 times). Manual byte scanning for tag name + markup extraction is faster than resetting and re-scanning via StringScanner. [...]- Cached small integer
to_s. Pre-computed frozen strings for 0-999 avoid 267Integer#to_sallocations per render.
This all added up to a 53% improvement on benchmarks - truly impressive for a codebase that's been tweaked by hundreds of contributors over 20 years.
I think this illustrates a number of interesting ideas:
- Having a robust test suite - in this case 974 unit tests - is a massive unlock for working with coding agents. This kind of research effort would not be possible without first having a tried and tested suite of tests.
- The autoresearch pattern - where an agent brainstorms a multitude of potential improvements and then experiments with them one at a time - is really effective.
- If you provide an agent with a benchmarking script "make it faster" becomes an actionable goal.
- CEOs can code again! Tobi has always been more hands-on than most, but this is a much more significant contribution than anyone would expect from the leader of a company with 7,500+ employees. I've seen this pattern play out a lot over the past few months: coding agents make it feasible for people in high-interruption roles to productively work with code again.
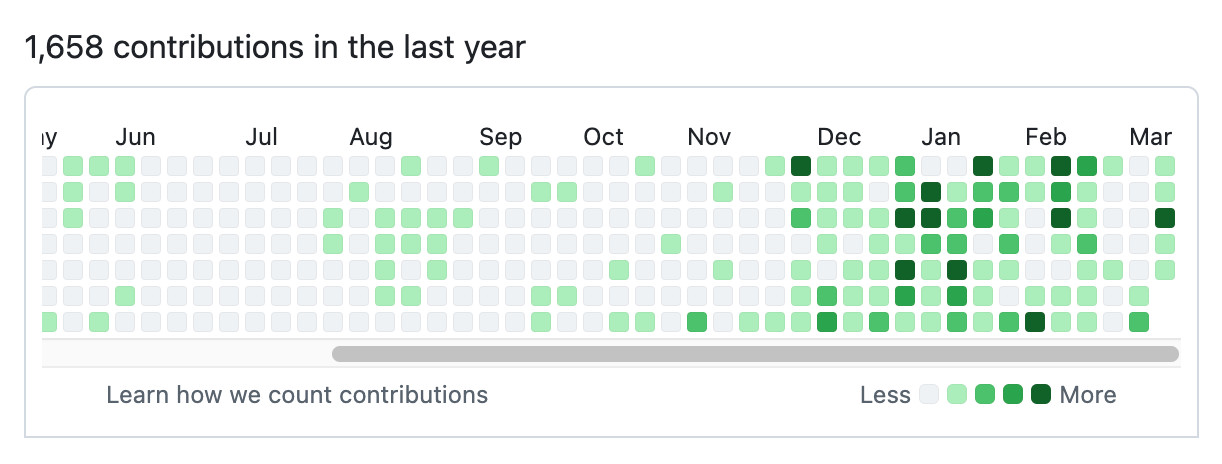
Here's Tobi's GitHub contribution graph for the past year, showing a significant uptick following that November 2025 inflection point when coding agents got really good.
He used Pi as the coding agent and released a new pi-autoresearch plugin in collaboration with David Cortés, which maintains state in an autoresearch.jsonl file like this one.