24 posts tagged “datasette-lite”
Datasette running entirely in the browser using Pyodide and WebAssembly, at lite.datasette.io
2026
Open Source AI Gap Map. Current AI is "a global partnership building a public option for AI", founded as a non-profit at the AI Action Summit in Paris in February 2025 and backed by serious capital ($400m already committed).
They launched their Gap Map a couple of days ago - an attempt at indexing the current state of open source AI:
The Gap Map v0.1 details 421 products in depth: 266 software tools and libraries, 85 models, 50 datasets, and 20 hardware projects, produced by 228 organizations. These products are organized into 14 categories across 3 layers of the stack (model components, product / UX, and infrastructure). The remaining 24,400 artifacts constitute the uncategorized long tail of the open source AI ecosystem, and will carry no score until they are researched and cited.
The map itself is interesting to explore, but I'm more excited about the underlying data - released under an MIT license in the currentai-org/os-ai-map GitHub account: 1,184 YAML files plus the notebooks, schemas and other scripts used to help gather them.
Since the files are on GitHub you can use Datasette Lite to explore some of them - here are 16,185 GitHub repos the project is tracking as a CSV file loaded into Datasette Lite.
simonw/browser-compat-db. Inspired by Mozilla's new MDN MCP service - source code here - I decided to try converting their comprehensive mdn/browser-compat-data repository full of browser compatibility data into a SQLite database.
This new GitHub repo includes a Claude Code for web (Opus 4.8) generated script for doing that using sqlite-utils.
I wanted the resulting ~66MB SQLite database to be available via the GitHub CDN with open CORS headers. GitHub releases don't have those, but any file stored in a regular GitHub repository does - so I had Codex Desktop (GPT-5.5) build a GitHub Actions workflow that builds the database and then force-pushes it to a db "orphan" branch.
You can download the resulting database from here, and since it's hosted with open CORS headers you can also explore it with Datasette Lite.
I've been pondering if Datasette Lite - the Python Datasette application run entirely in the browser using Pyodide and WebAssembly - might be able to edit persistent SQLite files stored on the user's computer.
That's what OFPS (Origin Private File System) is for, so I had Claude Code for web build me this playground UI to try it out in different browsers.
Datasette Lite is my version of Datasette that runs entirely in the browser using Pyodide in WebAssembly.
When I first built it four years ago I used Web Workers and code that intercepts navigation operations and fetches the generated HTML by running the Python app.
This worked, but had the disadvantage that any JavaScript in <script> tags would not be executed - breaking some Datasette functionality and a whole lot of Datasette plugins.
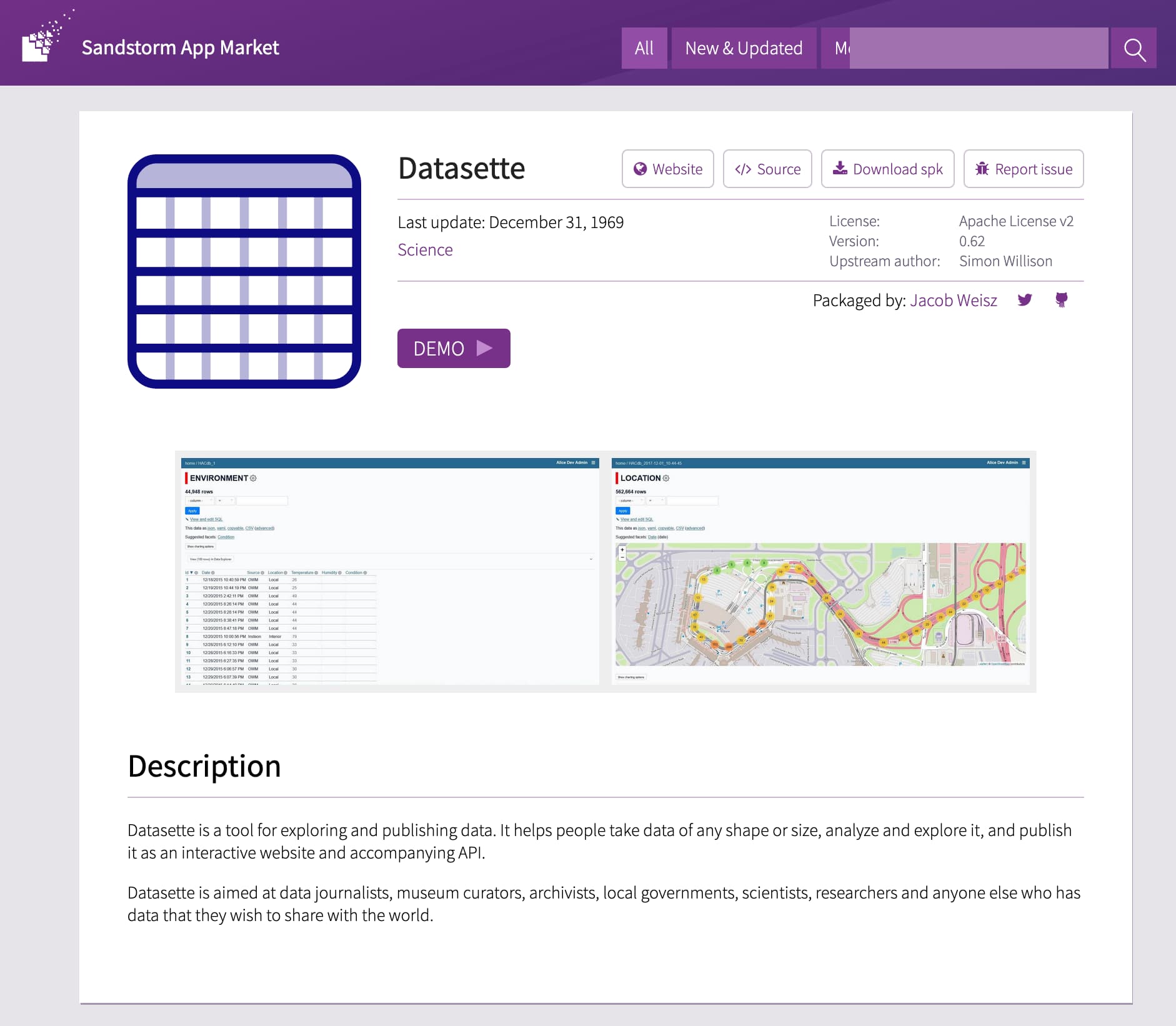
This morning I set Claude Opus 4.8 the task (in Claude Code for web) of figuring out how to run Python ASGI apps in Pyodide using Service Workers instead, and it seems to work! Here's a basic ASGI FastCGI demo and here's a demo that runs Datasette 1.0a31.
I'm still getting my head around exactly how it works, but once I've done that I plan to upgrade Datasette Lite itself.
microsoft/VibeVoice. VibeVoice is Microsoft's Whisper-style audio model for speech-to-text, MIT licensed and with speaker diarization built into the model.
Microsoft released it on January 21st, 2026 but I hadn't tried it until today. Here's a one-liner to run it on a Mac with uv, mlx-audio (by Prince Canuma) and the 5.71GB mlx-community/VibeVoice-ASR-4bit MLX conversion of the 17.3GB VibeVoice-ASR model, in this case against a downloaded copy of my recent podcast appearance with Lenny Rachitsky:
uv run --with mlx-audio mlx_audio.stt.generate \
--model mlx-community/VibeVoice-ASR-4bit \
--audio lenny.mp3 --output-path lenny \
--format json --verbose --max-tokens 32768
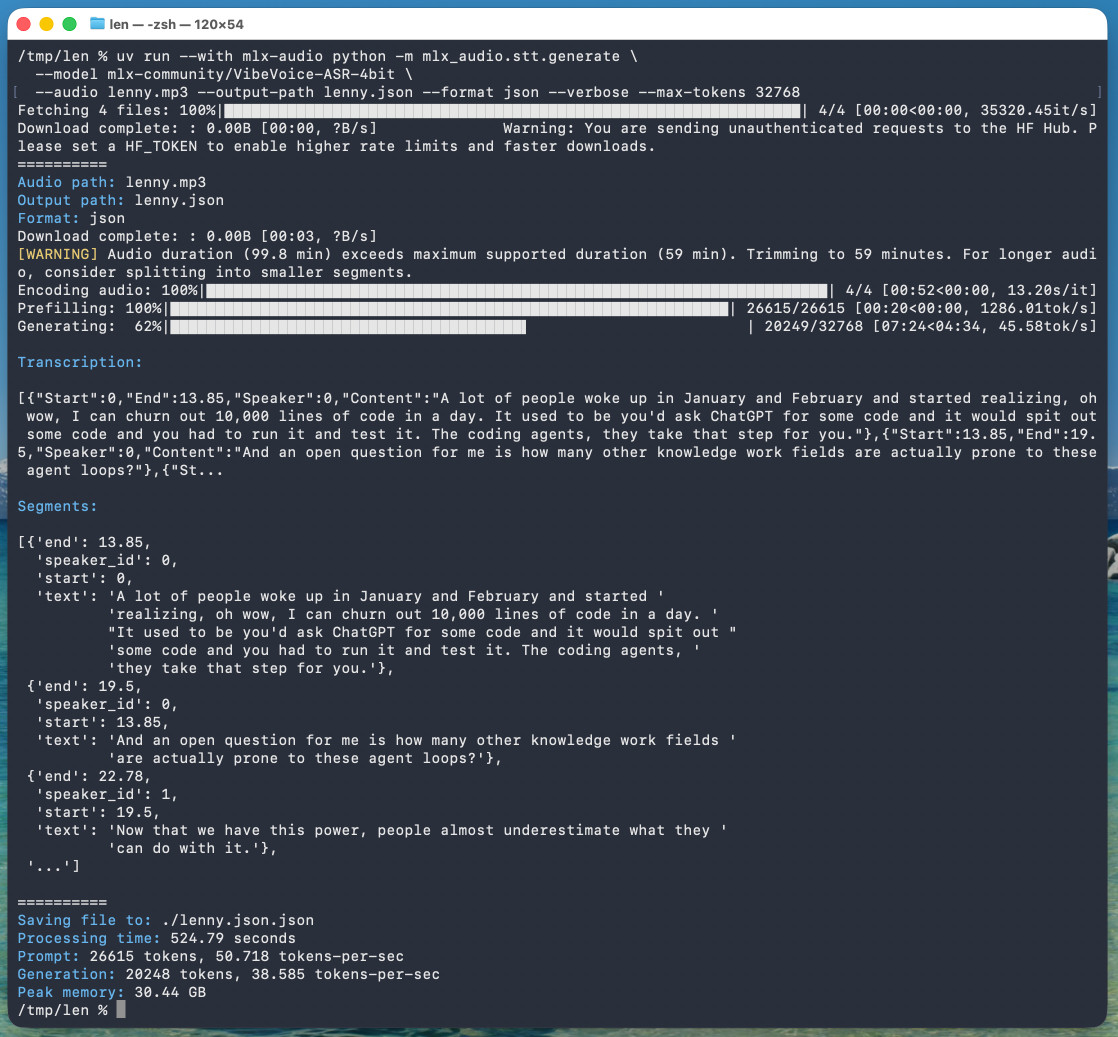
The tool reported back:
Processing time: 524.79 seconds
Prompt: 26615 tokens, 50.718 tokens-per-sec
Generation: 20248 tokens, 38.585 tokens-per-sec
Peak memory: 30.44 GB
So that's 8 minutes 45 seconds for an hour of audio (running on a 128GB M5 Max MacBook Pro).
I've tested it against .wav and .mp3 files and they both worked fine.
If you omit --max-tokens it defaults to 8192, which is enough for about 25 minutes of audio. I discovered that through trial-and-error and quadrupled it to guarantee I'd get the full hour.
That command reported using 30.44GB of RAM at peak, but in Activity Monitor I observed 61.5GB of usage during the prefill stage and around 18GB during the generating phase.
Here's the resulting JSON. The key structure looks like this:
{
"text": "And an open question for me is how many other knowledge work fields are actually prone to these agent loops?",
"start": 13.85,
"end": 19.5,
"duration": 5.65,
"speaker_id": 0
},
{
"text": "Now that we have this power, people almost underestimate what they can do with it.",
"start": 19.5,
"end": 22.78,
"duration": 3.280000000000001,
"speaker_id": 1
},
{
"text": "Today, probably 95% of the code that I produce, I didn't type it myself. I write so much of my code on my phone. It's wild.",
"start": 22.78,
"end": 30.0,
"duration": 7.219999999999999,
"speaker_id": 0
}
Since that's an array of objects we can open it in Datasette Lite, making it easier to browse.
Amusingly that Datasette Lite view shows three speakers - it identified Lenny and me for the conversation, and then a separate Lenny for the voice he used for the additional intro and the sponsor reads!
VibeVoice can only handle up to an hour of audio, so running the above command transcribed just the first hour of the podcast. To transcribe more than that you'd need to split the audio, ideally with a minute or so of overlap so you can avoid errors from partially transcribed words at the split point. You'd also need to then line up the identified speaker IDs across the multiple segments.
The most popular blogs of Hacker News in 2025 (via) Michael Lynch maintains HN Popularity Contest, a site that tracks personal blogs on Hacker News and scores them based on how well they perform on that platform.
The engine behind the project is the domain-meta.csv CSV on GiHub, a hand-curated list of known personal blogs with author and bio and tag metadata, which Michael uses to separate out personal blog posts from other types of content.
I came top of the rankings in 2023, 2024 and 2025 but I'm listed in third place for all time behind Paul Graham and Brian Krebs.
I dug around in the browser inspector and was delighted to find that the data powering the site is served with open CORS headers, which means you can easily explore it with external services like Datasette Lite.
Here's a convoluted window function query Claude Opus 4.5 wrote for me which, for a given domain, shows where that domain ranked for each year since it first appeared in the dataset:
with yearly_scores as ( select domain, strftime('%Y', date) as year, sum(score) as total_score, count(distinct date) as days_mentioned from "hn-data" group by domain, strftime('%Y', date) ), ranked as ( select domain, year, total_score, days_mentioned, rank() over (partition by year order by total_score desc) as rank from yearly_scores ) select r.year, r.total_score, r.rank, r.days_mentioned from ranked r where r.domain = :domain and r.year >= ( select min(strftime('%Y', date)) from "hn-data" where domain = :domain ) order by r.year desc
(I just noticed that the last and r.year >= ( clause isn't actually needed here.)
My simonwillison.net results show me ranked 3rd in 2022, 30th in 2021 and 85th back in 2007 - though I expect there are many personal blogs from that year which haven't yet been manually added to Michael's list.
Also useful is that every domain gets its own CORS-enabled CSV file with details of the actual Hacker News submitted from that domain, e.g. https://hn-popularity.cdn.refactoringenglish.com/domains/simonwillison.net.csv. Here's that one in Datasette Lite.
2025
URL-addressable Pyodide Python environments
This evening I spotted an obscure bug in Datasette, using Datasette Lite. I figure it’s a good opportunity to highlight how useful it is to have a URL-addressable Python environment, powered by Pyodide and WebAssembly.
[... 1,905 words]S1: The $6 R1 Competitor? Tim Kellogg shares his notes on a new paper, s1: Simple test-time scaling, which describes an inference-scaling model fine-tuned on top of Qwen2.5-32B-Instruct for just $6 - the cost for 26 minutes on 16 NVIDIA H100 GPUs.
Tim highlight the most exciting result:
After sifting their dataset of 56K examples down to just the best 1K, they found that the core 1K is all that's needed to achieve o1-preview performance on a 32B model.
The paper describes a technique called "Budget forcing":
To enforce a minimum, we suppress the generation of the end-of-thinking token delimiter and optionally append the string “Wait” to the model’s current reasoning trace to encourage the model to reflect on its current generation
That's the same trick Theia Vogel described a few weeks ago.
Here's the s1-32B model on Hugging Face. I found a GGUF version of it at brittlewis12/s1-32B-GGUF, which I ran using Ollama like so:
ollama run hf.co/brittlewis12/s1-32B-GGUF:Q4_0
I also found those 1,000 samples on Hugging Face in the simplescaling/s1K data repository there.
I used DuckDB to convert the parquet file to CSV (and turn one VARCHAR[] column into JSON):
COPY (
SELECT
solution,
question,
cot_type,
source_type,
metadata,
cot,
json_array(thinking_trajectories) as thinking_trajectories,
attempt
FROM 's1k-00001.parquet'
) TO 'output.csv' (HEADER, DELIMITER ',');
Then I loaded that CSV into sqlite-utils so I could use the convert command to turn a Python data structure into JSON using json.dumps() and eval():
# Load into SQLite
sqlite-utils insert s1k.db s1k output.csv --csv
# Fix that column
sqlite-utils convert s1k.db s1u metadata 'json.dumps(eval(value))' --import json
# Dump that back out to CSV
sqlite-utils rows s1k.db s1k --csv > s1k.csv
Here's that CSV in a Gist, which means I can load it into Datasette Lite.
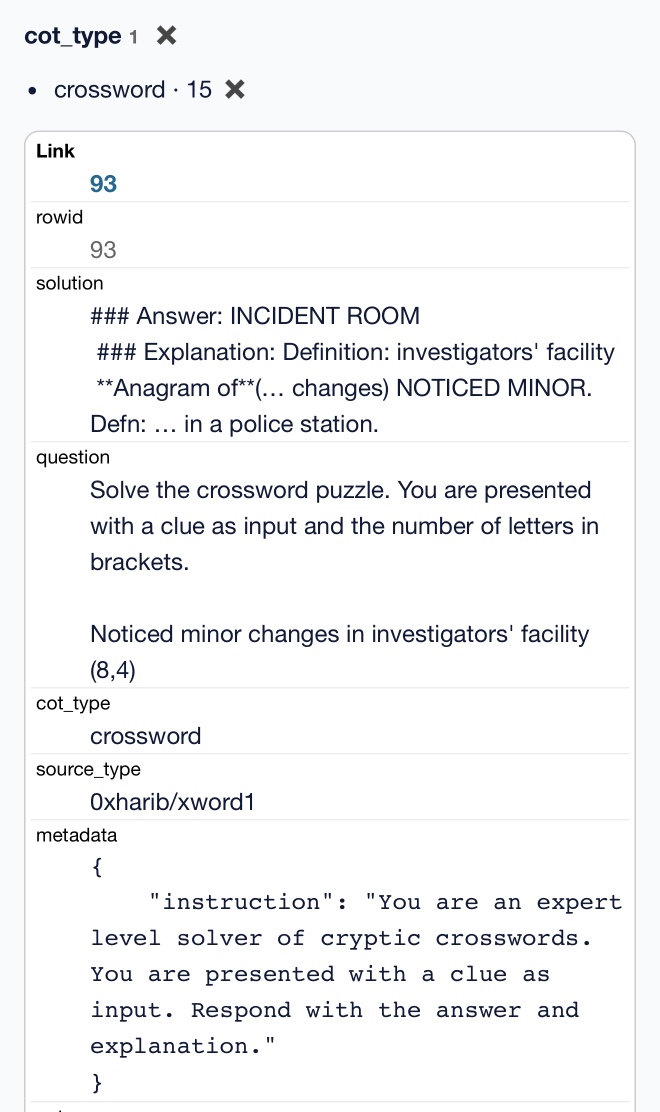
It really is a tiny amount of training data. It's mostly math and science, but there are also 15 cryptic crossword examples.
2024
Foursquare Open Source Places: A new foundational dataset for the geospatial community (via) I did not expect this!
[...] we are announcing today the general availability of a foundational open data set, Foursquare Open Source Places ("FSQ OS Places"). This base layer of 100mm+ global places of interest ("POI") includes 22 core attributes (see schema here) that will be updated monthly and available for commercial use under the Apache 2.0 license framework.
The data is available as Parquet files hosted on Amazon S3.
Here's how to list the available files:
aws s3 ls s3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/
I got back places-00000.snappy.parquet through places-00024.snappy.parquet, each file around 455MB for a total of 10.6GB of data.
I ran duckdb and then used DuckDB's ability to remotely query Parquet on S3 to explore the data a bit more without downloading it to my laptop first:
select count(*) from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-00000.snappy.parquet';
This got back 4,180,424 - that number is similar for each file, suggesting around 104,000,000 records total.
Update: DuckDB can use wildcards in S3 paths (thanks, Paul) so this query provides an exact count:
select count(*) from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-*.snappy.parquet';
That returned 104,511,073 - and Activity Monitor on my Mac confirmed that DuckDB only needed to fetch 1.2MB of data to answer that query.
I ran this query to retrieve 1,000 places from that first file as newline-delimited JSON:
copy (
select * from 's3://fsq-os-places-us-east-1/release/dt=2024-11-19/places/parquet/places-00000.snappy.parquet'
limit 1000
) to '/tmp/places.json';
Here's that places.json file, and here it is imported into Datasette Lite.
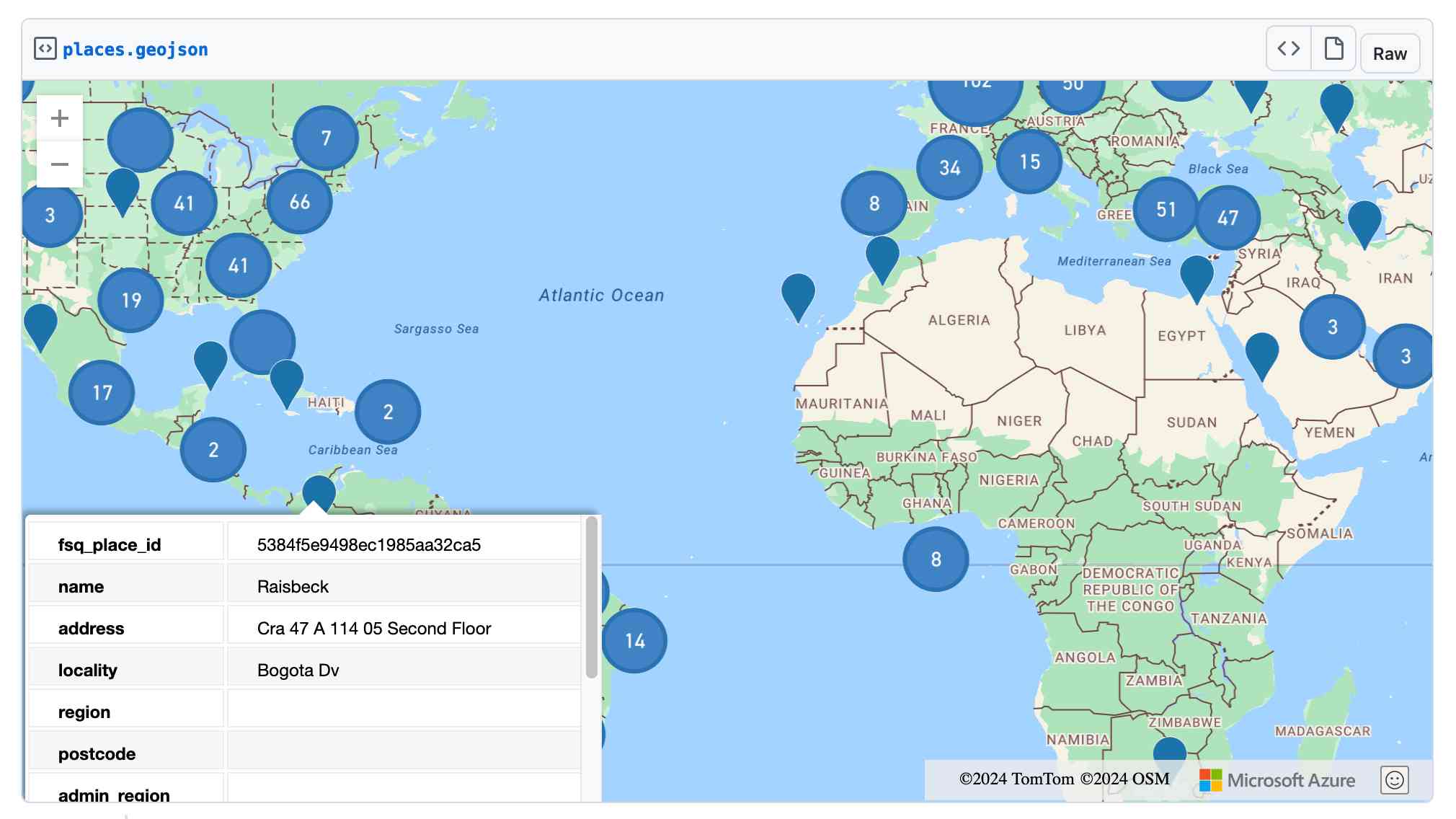
Finally, I got ChatGPT Code Interpreter to convert that file to GeoJSON and pasted the result into this Gist, giving me a map of those thousand places (because Gists automatically render GeoJSON):
2023
Weeknotes: Parquet in Datasette Lite, various talks, more LLM hacking
I’ve fallen a bit behind on my weeknotes. Here’s a catchup for the last few weeks.
[... 769 words]MMS Language Coverage in Datasette Lite. I converted the HTML table of 4,021 languages supported by Meta’s new Massively Multilingual Speech models to newline-delimited JSON and loaded it into Datasette Lite. Faceting by Language Family is particularly interesting—the top five families represented are Niger-Congo with 1,019, Austronesian with 609, Sino-Tibetan with 288, Indo-European with 278 and Afro-Asiatic with 222.
Data analysis with SQLite and Python for PyCon 2023
I’m at PyCon 2023 in Salt Lake City this week.
[... 347 words]What’s in the RedPajama-Data-1T LLM training set
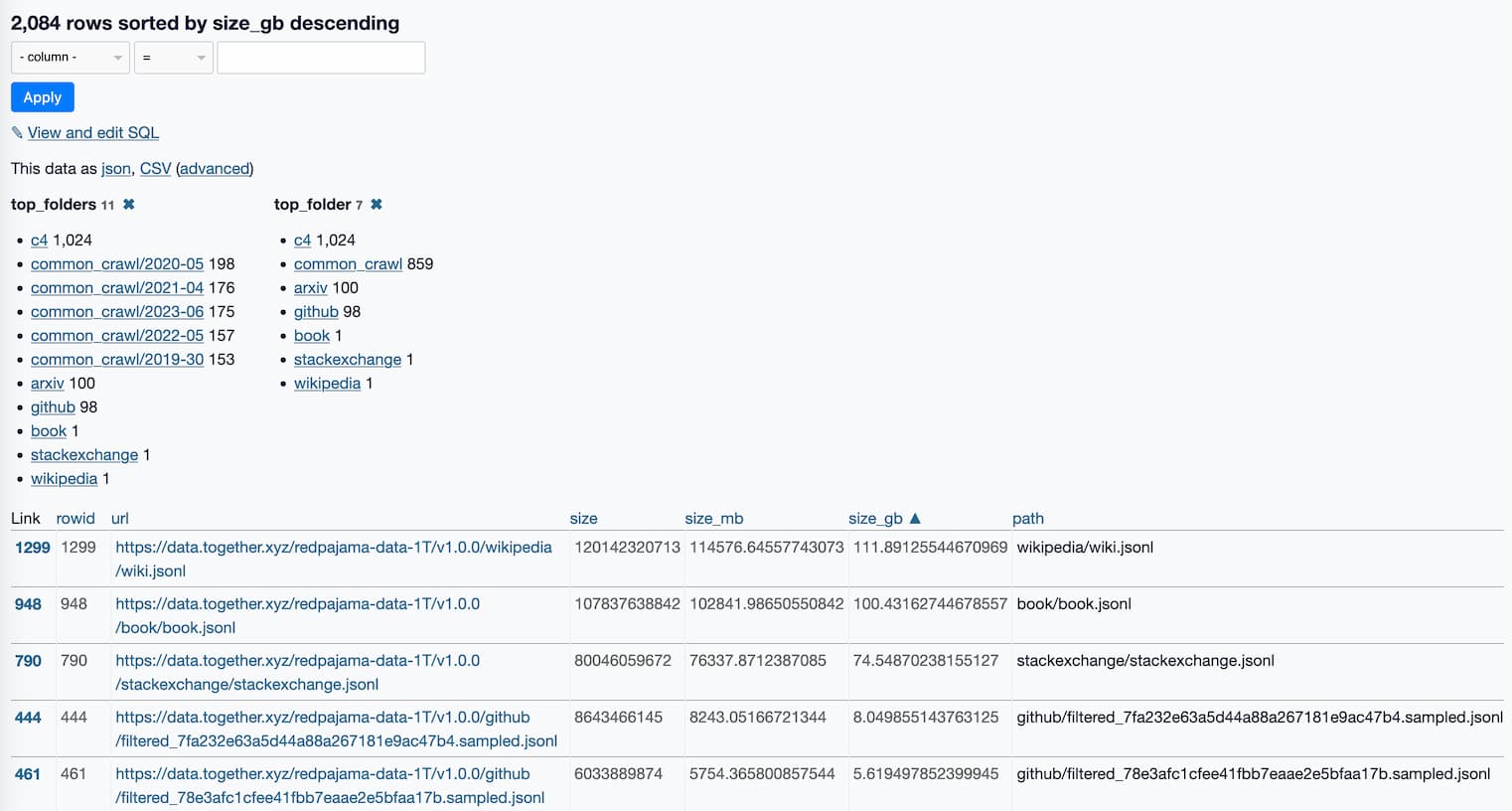
RedPajama is “a project to create leading open-source models, starts by reproducing LLaMA training dataset of over 1.2 trillion tokens”. It’s a collaboration between Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute.
[... 1,077 words]2022
Tracking Mastodon user numbers over time with a bucket of tricks
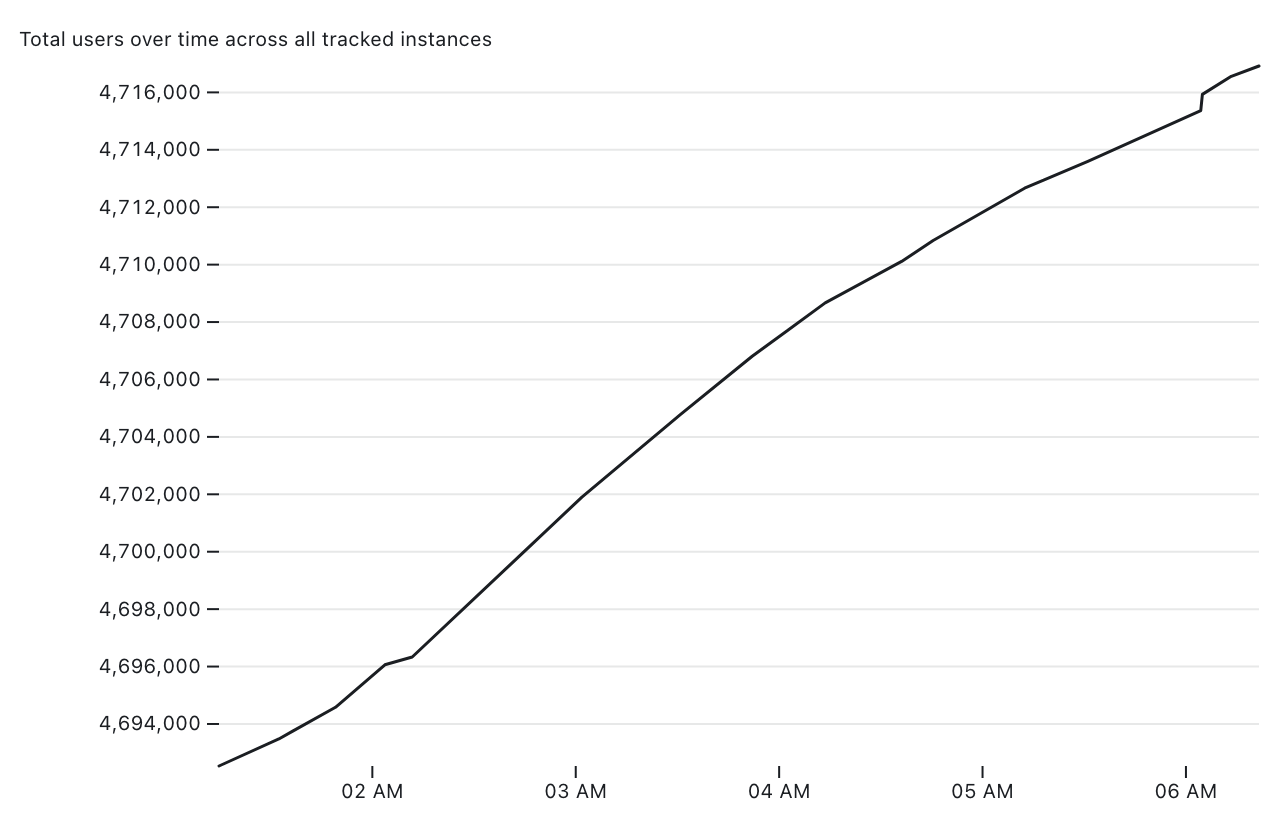
Mastodon is definitely having a moment. User growth is skyrocketing as more and more people migrate over from Twitter.
[... 1,534 words]Datasette Lite: Loading JSON data (via) I added a new feature to Datasette Lite: you can now pass it the URL to a JSON file (hosted on a CORS-compatible hosting provider such as GitHub or GitHub Gists) and it will load that file into a database table for you. It expects an array of objects, but if your file has an object as the root it will search through it looking for the first key that is an array of objects and load those instead.
Measuring traffic during the Half Moon Bay Pumpkin Festival
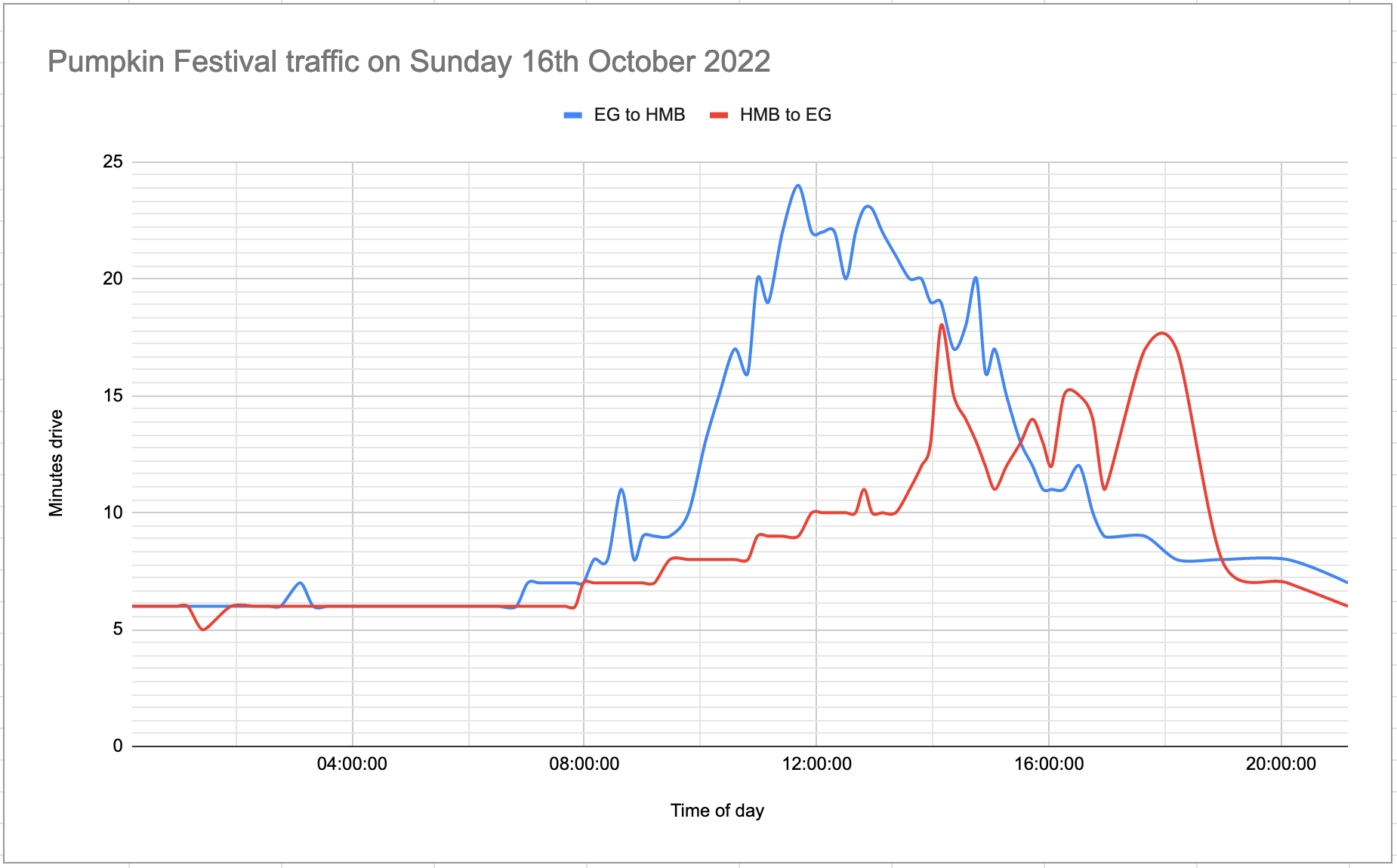
This weekend was the 50th annual Half Moon Bay Pumpkin Festival.
[... 2,693 words]Weeknotes: Datasette Lite, s3-credentials, shot-scraper, datasette-edit-templates and more
Despite distractions from AI I managed to make progress on a bunch of different projects this week, including new releases of s3-credentials and shot-scraper, a new datasette-edit-templates plugin and a small but neat improvement to Datasette Lite.
[... 1,562 words]Open every CSV file in a GitHub repository in Datasette Lite (via) I built an Observable notebook that accepts a GitHub repository as input, scans it for CSV files and generates a link to open all of those CSV files in Datasette Lite.
Analyzing ScotRail audio announcements with Datasette—from prototype to production
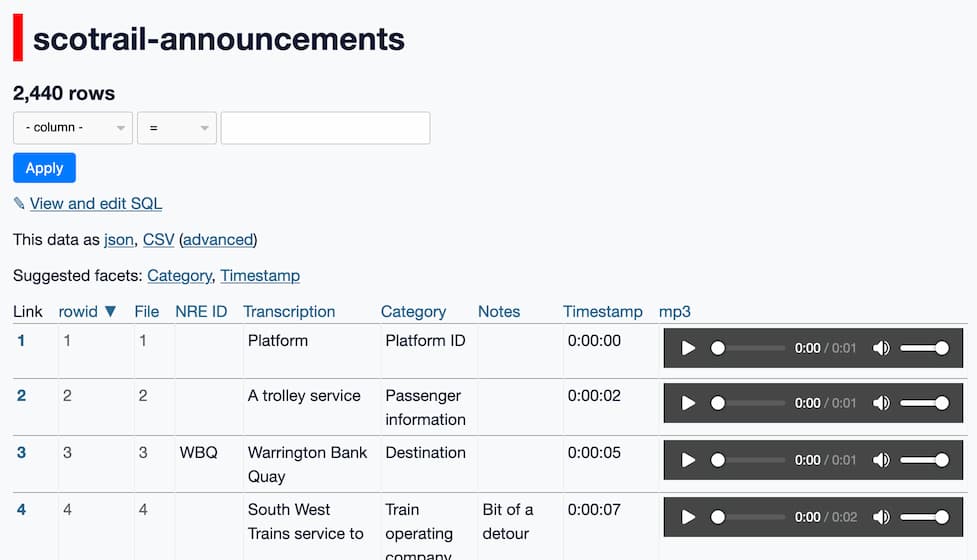
Scottish train operator ScotRail released a two-hour long MP3 file containing all of the components of its automated station announcements. Messing around with them is proving to be a huge amount of fun.
[... 4,428 words]Plugin support for Datasette Lite
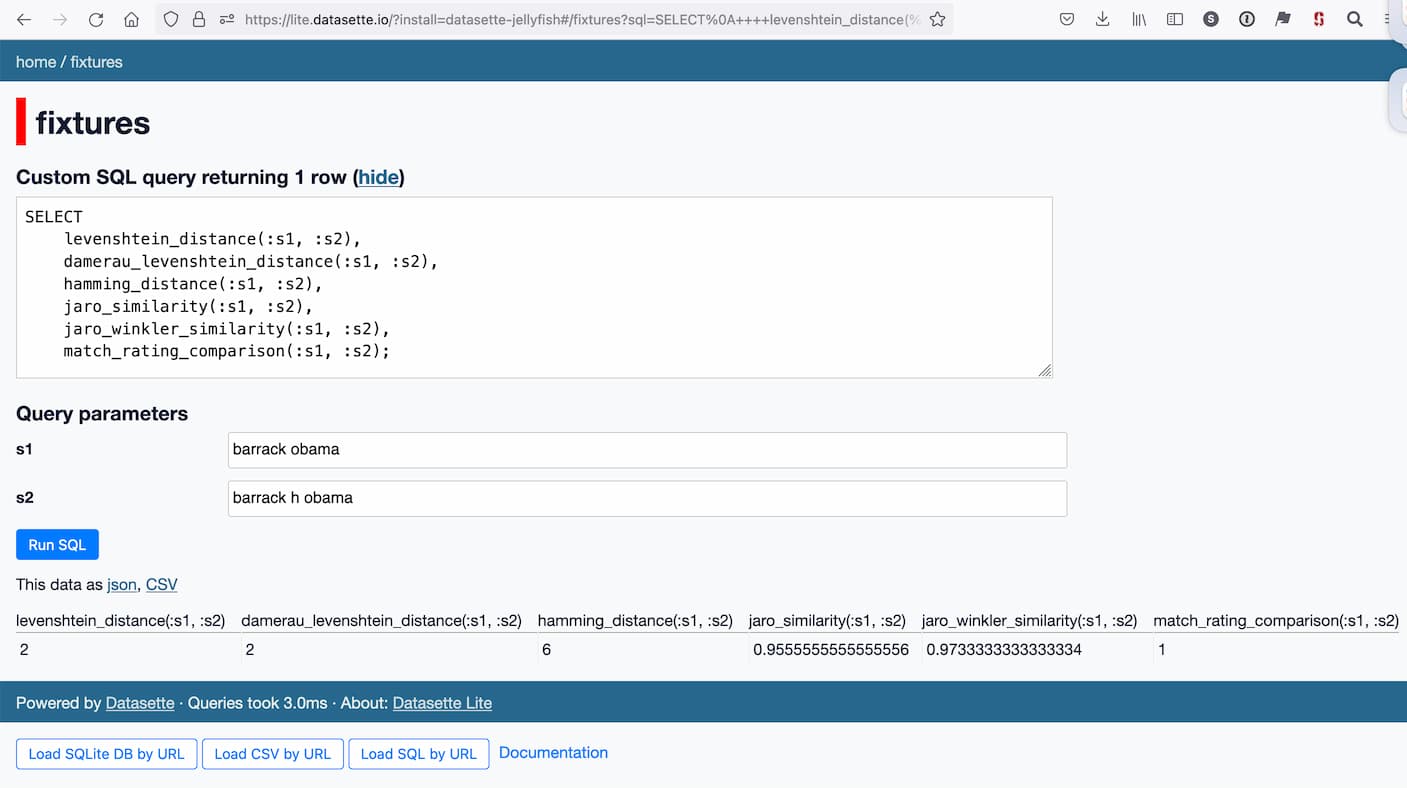
I’ve added a new feature to Datasette Lite, my distribution of Datasette that runs entirely in the browser using Python and SQLite compiled to WebAssembly. You can now install additional Datasette plugins by passing them in the URL.
[... 865 words]Weeknotes: Joining the board of the Python Software Foundation
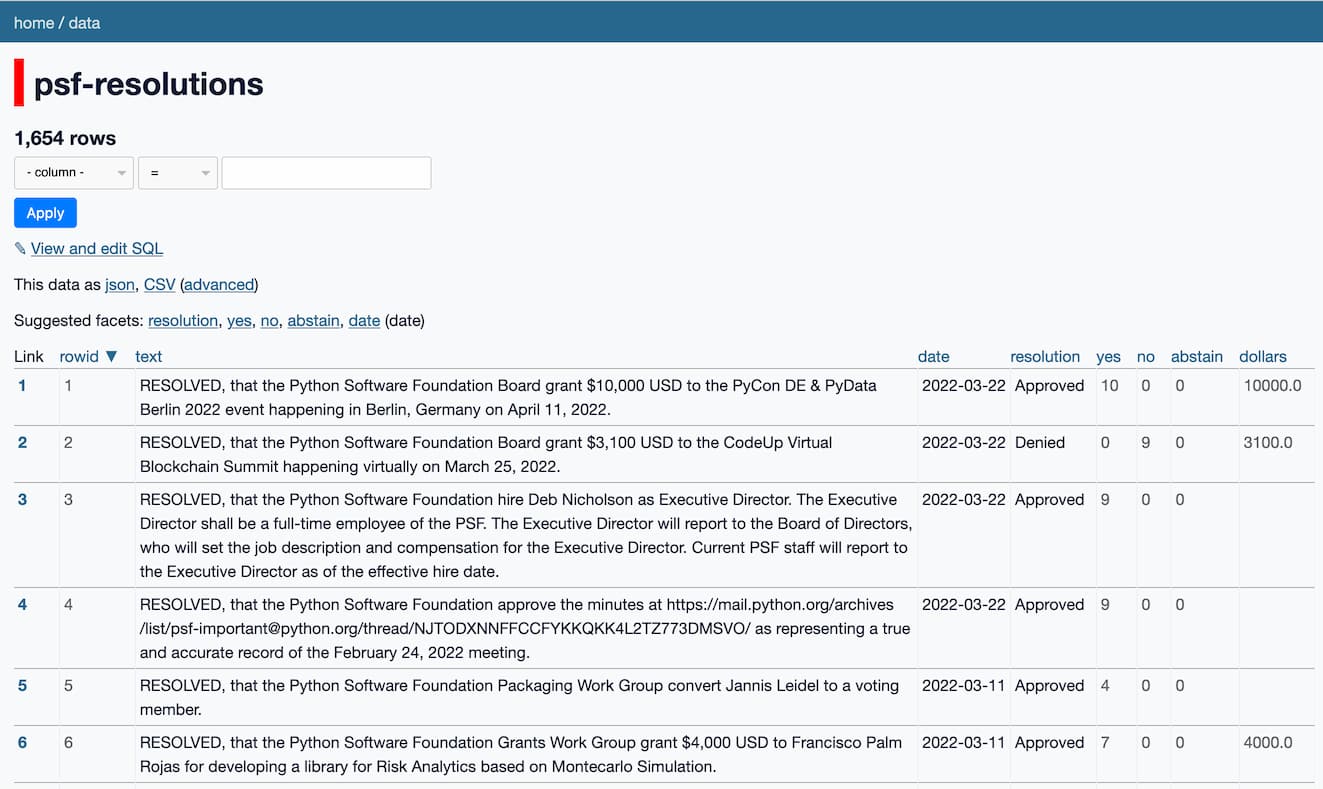
A few weeks ago I was elected to the board of directors for the Python Software Foundation.
[... 2,081 words]Joining CSV files in your browser using Datasette Lite
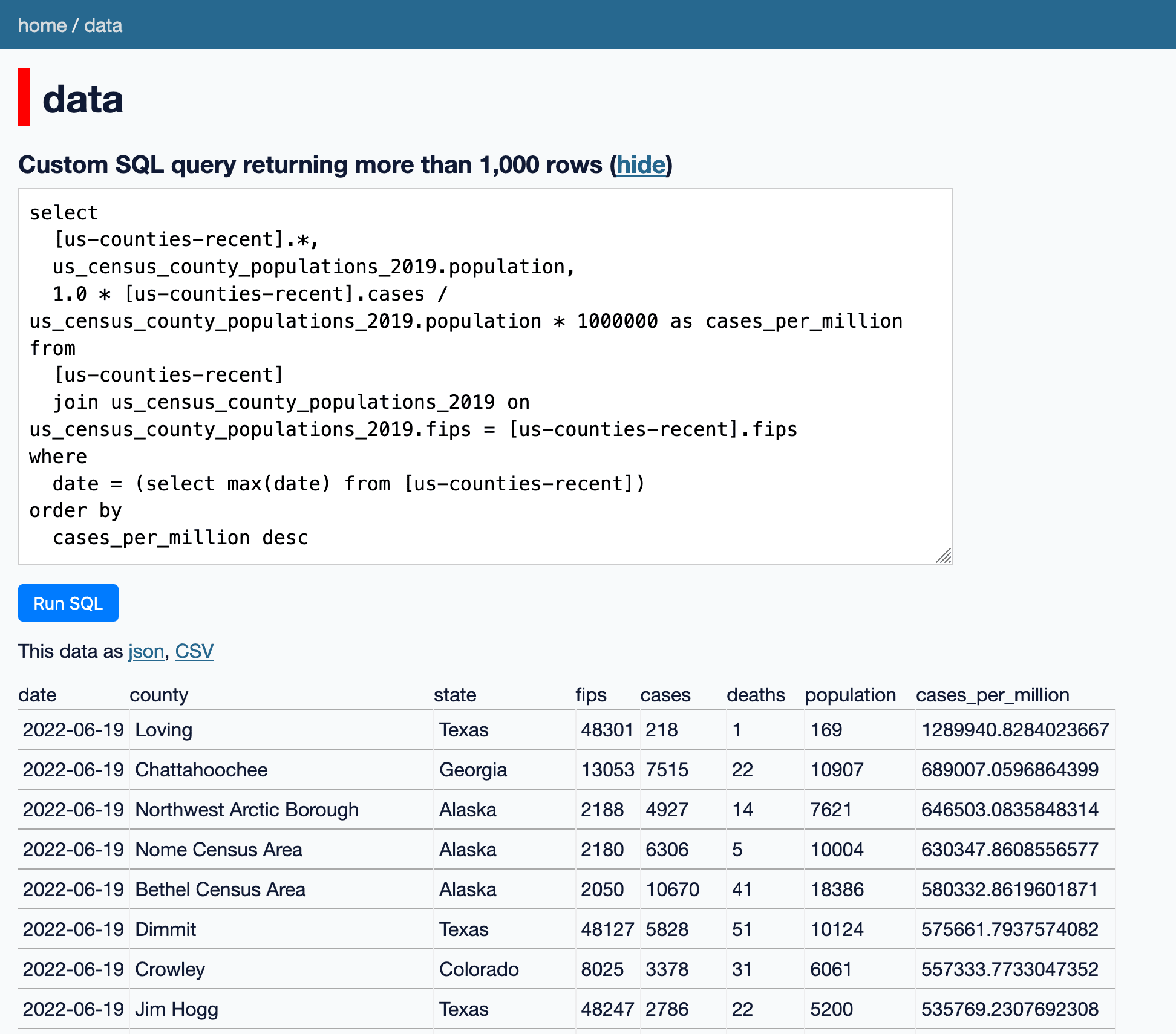
I added a new feature to Datasette Lite—my version of Datasette that runs entirely in your browser using WebAssembly (previously): you can now use it to load one or more CSV files by URL, and then run SQL queries against them—including joins across data from multiple files.
[... 546 words]Weeknotes: Datasette Lite, nogil Python, HYTRADBOI
My big project this week was Datasette Lite, a new way to run Datasette directly in a browser, powered by WebAssembly and Pyodide. I also continued my research into running SQL queries in parallel, described last week. Plus I spoke at HYTRADBOI.
[... 1,434 words]Datasette Lite: a server-side Python web application running in a browser
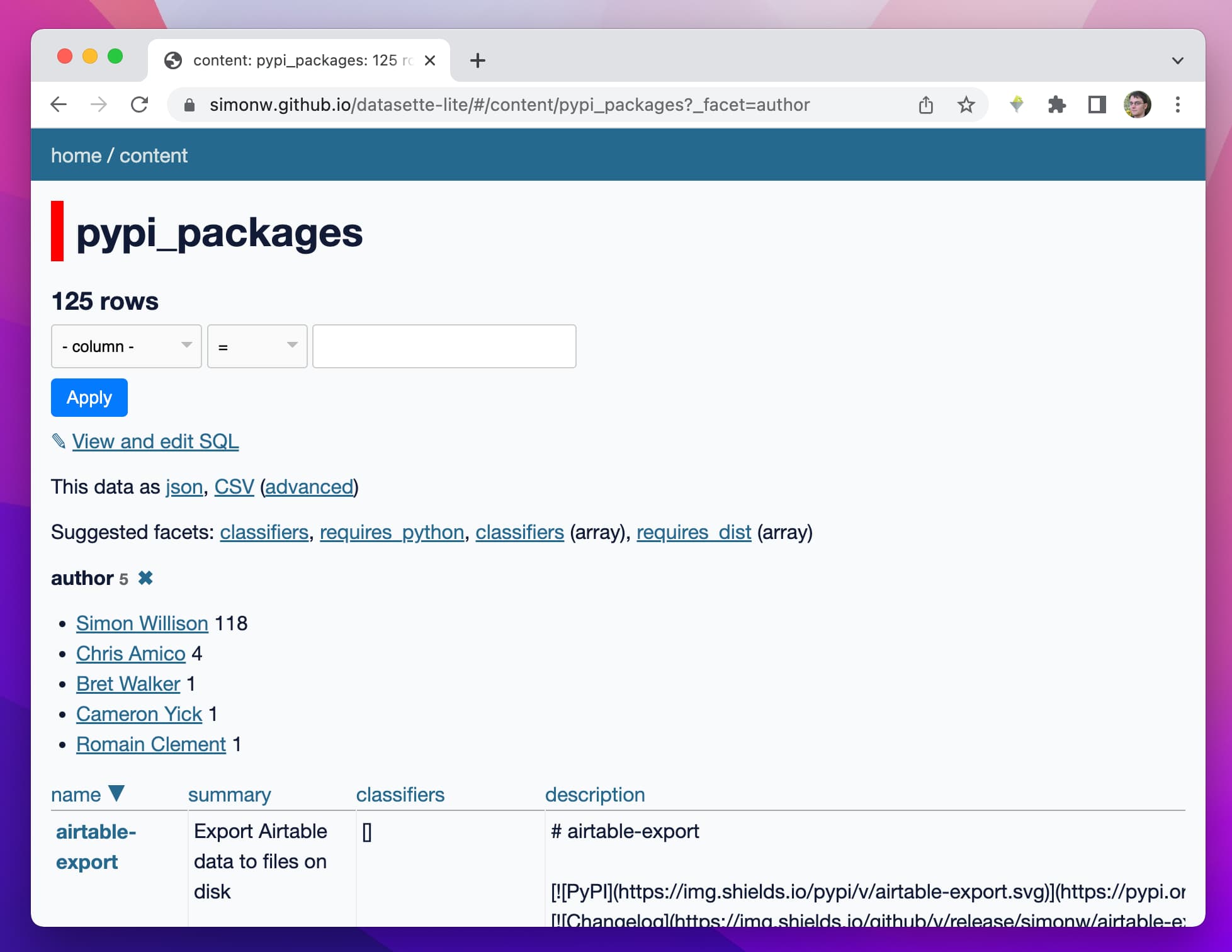
Datasette Lite is a new way to run Datasette: entirely in a browser, taking advantage of the incredible Pyodide project which provides Python compiled to WebAssembly plus a whole suite of useful extras.
[... 4,800 words]