1,526 posts tagged “datasette”
Datasette is an open source tool for exploring and publishing data.
2025
Video + notes on upgrading a Datasette plugin for the latest 1.0 alpha, with help from uv and OpenAI Codex CLI
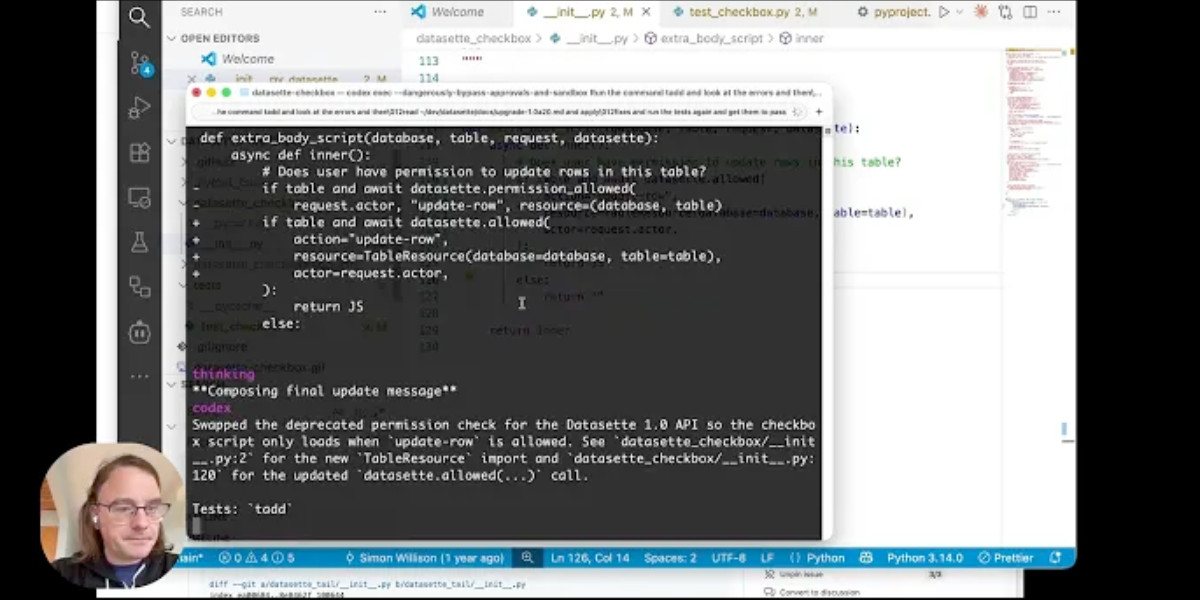
I’m upgrading various plugins for compatibility with the new Datasette 1.0a20 alpha release and I decided to record a video of the process. This post accompanies that video with detailed additional notes.
[... 1,094 words]Open redirect endpoint in Datasette prior to 0.65.2 and 1.0a21. This GitHub security advisory covers two new releases of Datasette that I shipped today, both addressing the same open redirect issue with a fix by James Jefferies.
Datasette 0.65.2 fixes the bug and also adds Python 3.14 support and a datasette publish cloudrun fix.
Datasette 1.0a21 also has that Cloud Run fix and two other small new features:
I decided to include the Cloud Run deployment fix so anyone with Datasette instances deployed to Cloud Run can update them with the new patched versions.
A new SQL-powered permissions system in Datasette 1.0a20
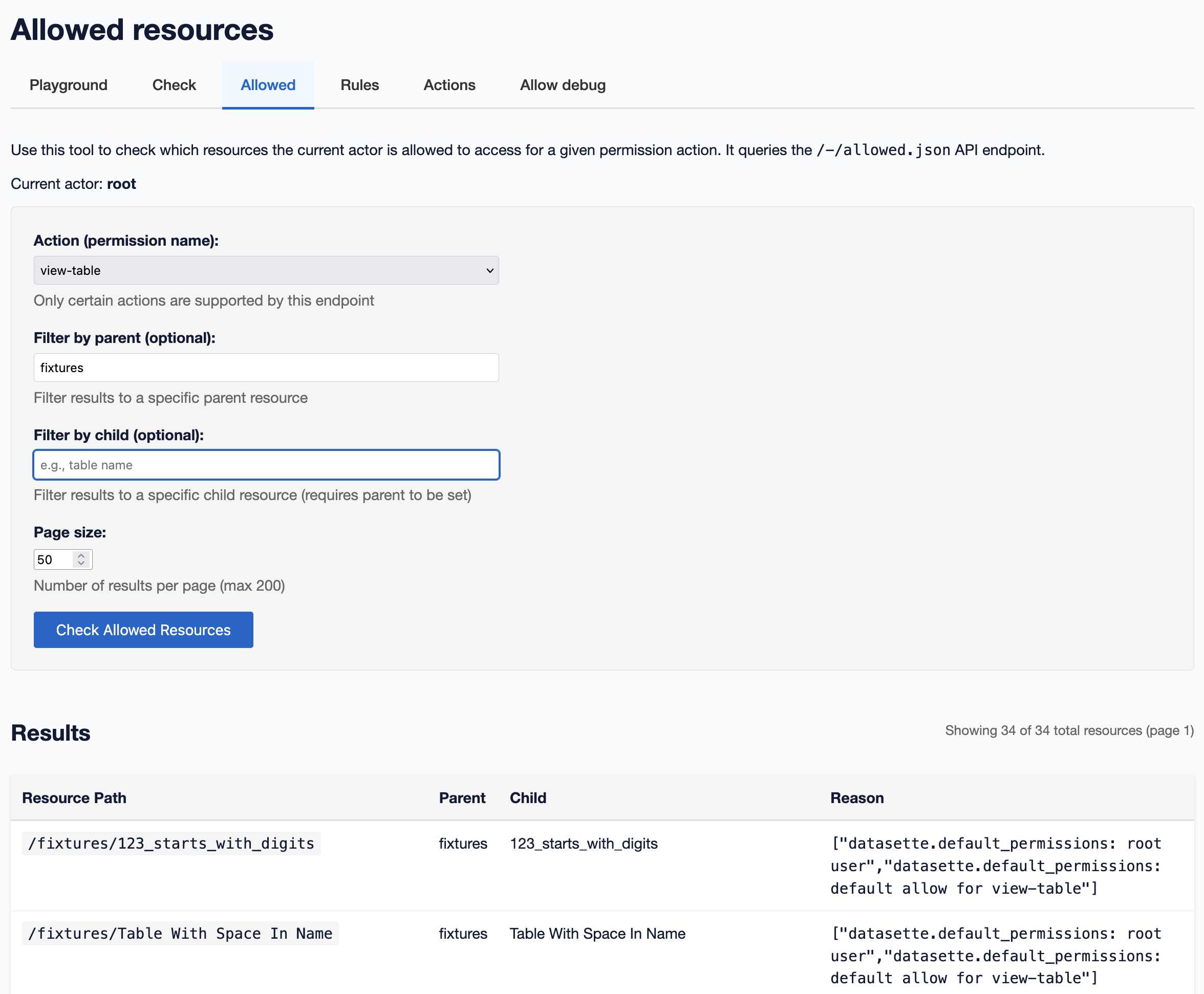
Datasette 1.0a20 is out with the biggest breaking API change on the road to 1.0, improving how Datasette’s permissions system works by migrating permission logic to SQL running in SQLite. This release involved 163 commits, with 10,660 additions and 1,825 deletions, most of which was written with the help of Claude Code.
[... 2,750 words]