8 posts tagged “georgi-gerganov”
2026
Note that the main issues that people currently unknowingly face with local models mostly revolve around the harness and some intricacies around model chat templates and prompt construction. Sometimes there are even pure inference bugs. From typing the task in the client to the actual result, there is a long chain of components that atm are not only fragile - are also developed by different parties. So it's difficult to consolidate the entire stack and you have to keep in mind that what you are currently observing is with very high probability still broken in some subtle way along that chain.
— Georgi Gerganov, explaining why it's hard to find local models that work well with coding agents
ggml.ai joins Hugging Face to ensure the long-term progress of Local AI (via) I don't normally cover acquisition news like this, but I have some thoughts.
It's hard to overstate the impact Georgi Gerganov has had on the local model space. Back in March 2023 his release of llama.cpp made it possible to run a local LLM on consumer hardware. The original README said:
The main goal is to run the model using 4-bit quantization on a MacBook. [...] This was hacked in an evening - I have no idea if it works correctly.
I wrote about trying llama.cpp out at the time in Large language models are having their Stable Diffusion moment:
I used it to run the 7B LLaMA model on my laptop last night, and then this morning upgraded to the 13B model—the one that Facebook claim is competitive with GPT-3.
Meta's original LLaMA release depended on PyTorch and their FairScale PyTorch extension for running on multiple GPUs, and required CUDA and NVIDIA hardware. Georgi's work opened that up to a much wider range of hardware and kicked off the local model movement that has continued to grow since then.
Hugging Face are already responsible for the incredibly influential Transformers library used by the majority of LLM releases today. They've proven themselves a good steward for that open source project, which makes me optimistic for the future of llama.cpp and related projects.
This section from the announcement looks particularly promising:
Going forward, our joint efforts will be geared towards the following objectives:
- Towards seamless "single-click" integration with the transformers library. The
transformersframework has established itself as the 'source of truth' for AI model definitions. Improving the compatibility between the transformers and the ggml ecosystems is essential for wider model support and quality control.- Better packaging and user experience of ggml-based software. As we enter the phase in which local inference becomes a meaningful and competitive alternative to cloud inference, it is crucial to improve and simplify the way in which casual users deploy and access local models. We will work towards making llama.cpp ubiquitous and readily available everywhere, and continue partnering with great downstream projects.
Given the influence of Transformers, this closer integration could lead to model releases that are compatible with the GGML ecosystem out of the box. That would be a big win for the local model ecosystem.
I'm also excited to see investment in "packaging and user experience of ggml-based software". This has mostly been left to tools like Ollama and LM Studio. ggml-org released LlamaBarn last year - "a macOS menu bar app for running local LLMs" - and I'm hopeful that further investment in this area will result in more high quality open source tools for running local models from the team best placed to deliver them.
2024
llamafile v0.8.13 (and whisperfile)
(via)
The latest release of llamafile (previously) adds support for Gemma 2B (pre-bundled llamafiles available here), significant performance improvements and new support for the Whisper speech-to-text model, based on whisper.cpp, Georgi Gerganov's C++ implementation of Whisper that pre-dates his work on llama.cpp.
I got whisperfile working locally by first downloading the cross-platform executable attached to the GitHub release and then grabbing a whisper-tiny.en-q5_1.bin model from Hugging Face:
wget -O whisper-tiny.en-q5_1.bin \
https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-tiny.en-q5_1.bin
Then I ran chmod 755 whisperfile-0.8.13 and then executed it against an example .wav file like this:
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f raven_poe_64kb.wav --no-prints
The --no-prints option suppresses the debug output, so you just get text that looks like this:
[00:00:00.000 --> 00:00:12.000] This is a LibraVox recording. All LibraVox recordings are in the public domain. For more information please visit LibraVox.org.
[00:00:12.000 --> 00:00:20.000] Today's reading The Raven by Edgar Allan Poe, read by Chris Scurringe.
[00:00:20.000 --> 00:00:40.000] Once upon a midnight dreary, while I pondered weak and weary, over many a quaint and curious volume of forgotten lore. While I nodded nearly napping, suddenly there came a tapping as of someone gently rapping, rapping at my chamber door.
There are quite a few undocumented options - to write out JSON to a file called transcript.json (example output):
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f /tmp/raven_poe_64kb.wav --no-prints --output-json --output-file transcript
I had to convert my own audio recordings to 16kHz .wav files in order to use them with whisperfile. I used ffmpeg to do this:
ffmpeg -i runthrough-26-oct-2023.wav -ar 16000 /tmp/out.wav
Then I could transcribe that like so:
./whisperfile-0.8.13 -m whisper-tiny.en-q5_1.bin -f /tmp/out.wav --no-prints
Update: Justine says:
I've just uploaded new whisperfiles to Hugging Face which use miniaudio.h to automatically resample and convert your mp3/ogg/flac/wav files to the appropriate format.
With that whisper-tiny model this took just 11s to transcribe a 10m41s audio file!
I also tried the much larger Whisper Medium model - I chose to use the 539MB ggml-medium-q5_0.bin quantized version of that from huggingface.co/ggerganov/whisper.cpp:
./whisperfile-0.8.13 -m ggml-medium-q5_0.bin -f out.wav --no-prints
This time it took 1m49s, using 761% of CPU according to Activity Monitor.
I tried adding --gpu auto to exercise the GPU on my M2 Max MacBook Pro:
./whisperfile-0.8.13 -m ggml-medium-q5_0.bin -f out.wav --no-prints --gpu auto
That used just 16.9% of CPU and 93% of GPU according to Activity Monitor, and finished in 1m08s.
I tried this with the tiny model too but the performance difference there was imperceptible.
2023
Downloading and converting the original models (Cerebras-GPT) (via) Georgi Gerganov added support for the Apache 2 licensed Cerebras-GPT language model to his ggml C++ inference library, as used by llama.cpp.
LLaMA voice chat, with Whisper and Siri TTS. llama.cpp author Georgi Gerganov has stitched together the LLaMA language model, the Whisper voice to text model (with his whisper.cpp library) and the macOS “say” command to create an entirely offline AI agent that he can talk to with his voice and that can speak replies straight back to him.
Large language models are having their Stable Diffusion moment
The open release of the Stable Diffusion image generation model back in August 2022 was a key moment. I wrote how Stable Diffusion is a really big deal at the time.
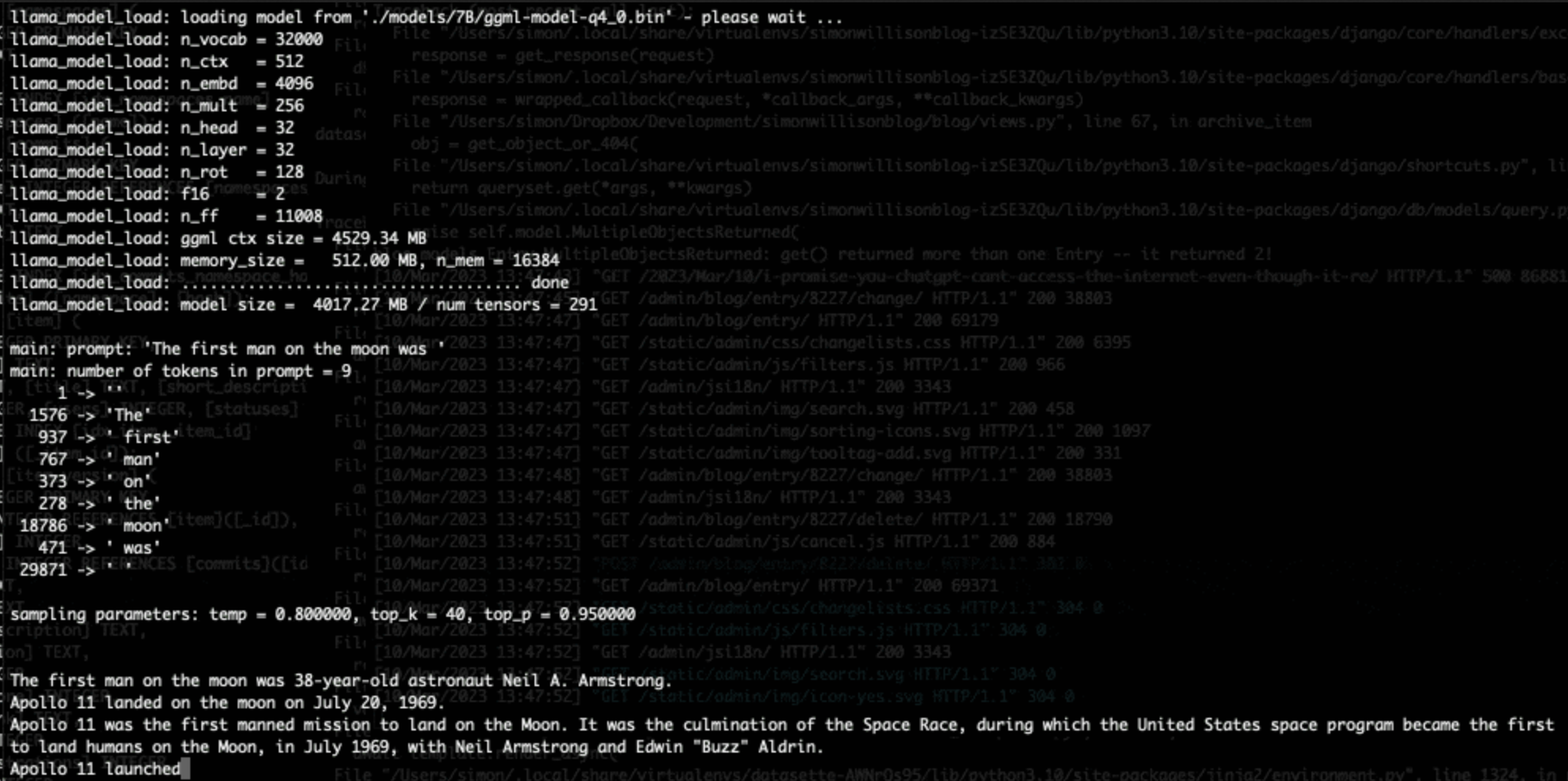
[... 1,815 words]Running LLaMA 7B on a 64GB M2 MacBook Pro with llama.cpp. I got Facebook’s LLaMA 7B to run on my MacBook Pro using llama.cpp (a “port of Facebook’s LLaMA model in C/C++”) by Georgi Gerganov. It works! I’ve been hoping to run a GPT-3 class language model on my own hardware for ages, and now it’s possible to do exactly that. The model itself ends up being just 4GB after applying Georgi’s script to “quantize the model to 4-bits”.