48 posts tagged “guardian”
2019
The Guardian’s nifty old-article trick is a reminder of how news organizations can use metadata to limit misinformation (via) The Guardian displays prominent banners on news stories from more than a year ago warning that it is an older article to help prevent accidental or intentional spread of misinformation using their content as ammunition. Impressively they also display the year prominently on the card images they serve as social media previews fir older articles.
Want to see what one digital future for newspapers looks like? Look at The Guardian, which isn’t losing money anymore (via) After losing money every single year since 1998, the Guardian just managed to turn a profit! Detailed analysis of how they did it by Joshua Benton.
2010
Linked Data at the Guardian. The Guardian’s Open Platform API can now be queried by MusicBrainz ID and ISBN, opening up some extremely useful new types of query.
Today’s Guardian, by Phil Gyford. An alternative interface for reading today’s Guardian, built using the new Open Platform Content API and with extensive design notes from creator Phil Gyford.
What’s powering the Content API? The new Guardian Content API runs on Solr, scaled using EC2 and Solr replication and with a Scala web service layer sitting between Solr and the API’s end users.
OpenPlatform Content API Explorer. The new API explorer for the Guardian’s Content API.
The Guardian’s Open Platform is open for business. The Guardian’s Content API is now out of beta. Of particular interest: you can access basic article metadata (headline, URL and tags) without using an API key at all, and the API supports JSONP—just request format=json and include a callback=foo argument.
Live blogging the general election. The Guardian’s ongoing live blogs covering the UK election have been the best way of following events that I’ve seen (yes, better than Twitter). Live-blog author Andrew Sparrow explains his approach.
Breakfast Instapaper. Handy tool for selecting and bulk-submitting stories from today’s Guardian and NYTimes to your Instapaper account, by Daniel Vydra.
Comprehensive notes from my three hour Redis tutorial

Last week I presented two talks at the inaugural NoSQL Europe conference in London. The first was presented with Matthew Wall and covered the ways in which we have been exploring NoSQL at the Guardian. The second was a three hour workshop on Redis, my favourite piece of software to have the NoSQL label applied to it.
[... 263 words]Random Guardian (via) A random page from today’s Guardian, built by Daniel Vydra.
A day on Chatroulette, the web’s weirdest new outpost. By the Guardian’s Bobbie Johnson.
What’s hot? Introducing Zeitgeist. Dan Catt’s first project at the Guardian. “When something appears on the Zeitgeist page, it’s because it performed better (got more attention) than the norm for that content type/section/day”. The application itself is written in Python and runs on Google App Engine.
World Government Data. Launched last week, this is the Guardian’s meta-search engine for searching and browsing through data from four different government data sites (with more sites planned). Under the hood it’s Django, Solr, Haystack and the Scrapy crawling library. The application was built by Ben Firshman during an internship over Christmas.
Applications: the real stars of the data.gov.uk launch. A write-up of the data.gov.uk launch event at the Guardian. I demonstrated the Guardian’s World Government Data search engine and a small data.gov.uk inspired feature on WildlifeNearYou.
2009
Notes on designing the Guardian iPhone app. By John-Henry Barac, the principal designer of he iPhone application who also previously worked on the Guardian’s print transition to the Berliner format.
Crowdsourced document analysis and MP expenses
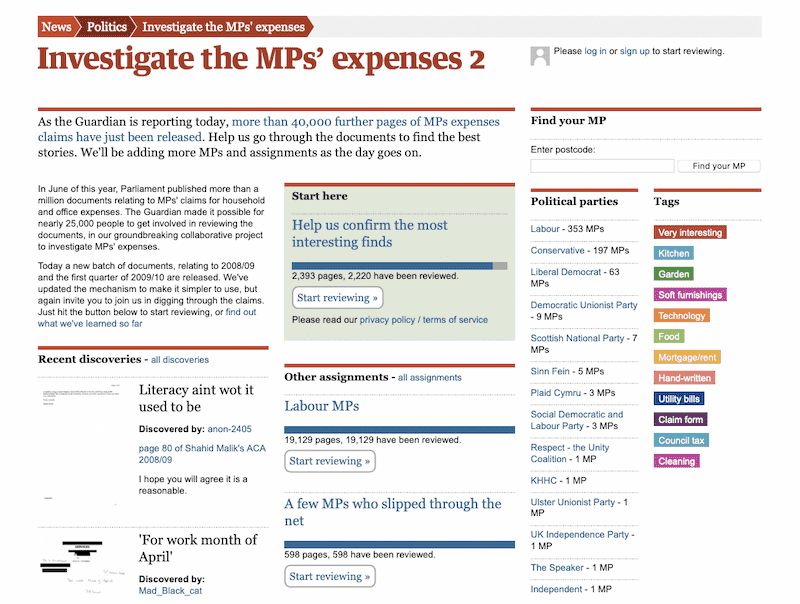
As you may have heard, the UK government released a fresh batch of MP expenses documents a week ago on Thursday. I spent that week working with a small team at Guardian HQ to prepare for the release. Here’s what we built:
[... 2,081 words]Guardian iPhone app. Released today, ad-free, £2.39 for the application, has an excellent offline mode. I helped build the backend web service, which is a Django app running on EC2.
UK Scale Camp. We’re hosting a one day web performance and scalability unconference at the Guardian on the 4th of December. If you’re involved in running a high-scale website in the UK (or abroad) we’d love you to come along. Spaces are going fast.
The Guardian 1000 Novels Everyone Must Read in FluidDB. Nicholas J. Radcliffe loaded the Guardian’s list of 1000 novels in to FluidDB, where the ability for users to add their own ratings style metadata makes it an ideal dataset for exploring the capabilities of the platform.
Hack Day tools for non-developers
We’re about to run our second internal hack day at the Guardian. The first was an enormous amount of fun and the second one looks set to be even more productive.
[... 920 words]Curating conversations. Chris Thorpe has open-sourced the Guardian’s moderated Twitter backchannel app, for displaying back channels at high profile (and hence high potential for abuse) events. It’s a Python application that runs on App Engine.
Four crowdsourcing lessons from the Guardian’s (spectacular) expenses-scandal experiment. Michael Andersen from the Nieman Journalism Lab interviewed me about the MP expenses crowdsourcing site.
The breakneck race to build an application to crowdsource MPs’ expenses. Charles Arthur wrote up a very nice piece on the development effort behind the Guardian’s crowdsourcing expenses app.
Investigate your MP’s expenses. Launched today, this is the project that has been keeping me ultra-busy for the past week—we’re crowdsourcing the analysis of the 700,000+ scanned MP expenses documents released this morning. It’s the Guardian’s first live Django-powered application, and also the first time we’ve hosted something on EC2.
Dealing with election results data. Alf Eaton loaded the Guardian’s European election results spreadsheet in to Google’s new Fusion Tables tool.
Exactly how well did the BNP do where you live? Guardian journalists spent a day and a half calling round different local authorities to get a proper breakdown of the European election results (which are only officially published in aggregate) and published the results as a spreadsheet on the Datablog.
You ask, they answer: Neal’s Yard Remedies. After reading the comments, something tells me Neal’s Yard Remedies may be regretting their decision to answer questions from Guardian readers.
Muck Rack: Links posted by Guardian Journalists on Twitter. I’m rather impressed by the Sawhorse Media collection of Twitter aggregation sites (Muck Rack aggregates journalists)—a simple idea very well executed. Here’s a nice example—this page shows links posted to Twitter by known Guardian journalists, but goes a step further and scrapes in the favicon, the real title of the page and resolves the domain from any shortened links.