4 posts tagged “nathan-lambert”
2025
Olmo 3 is a fully open LLM
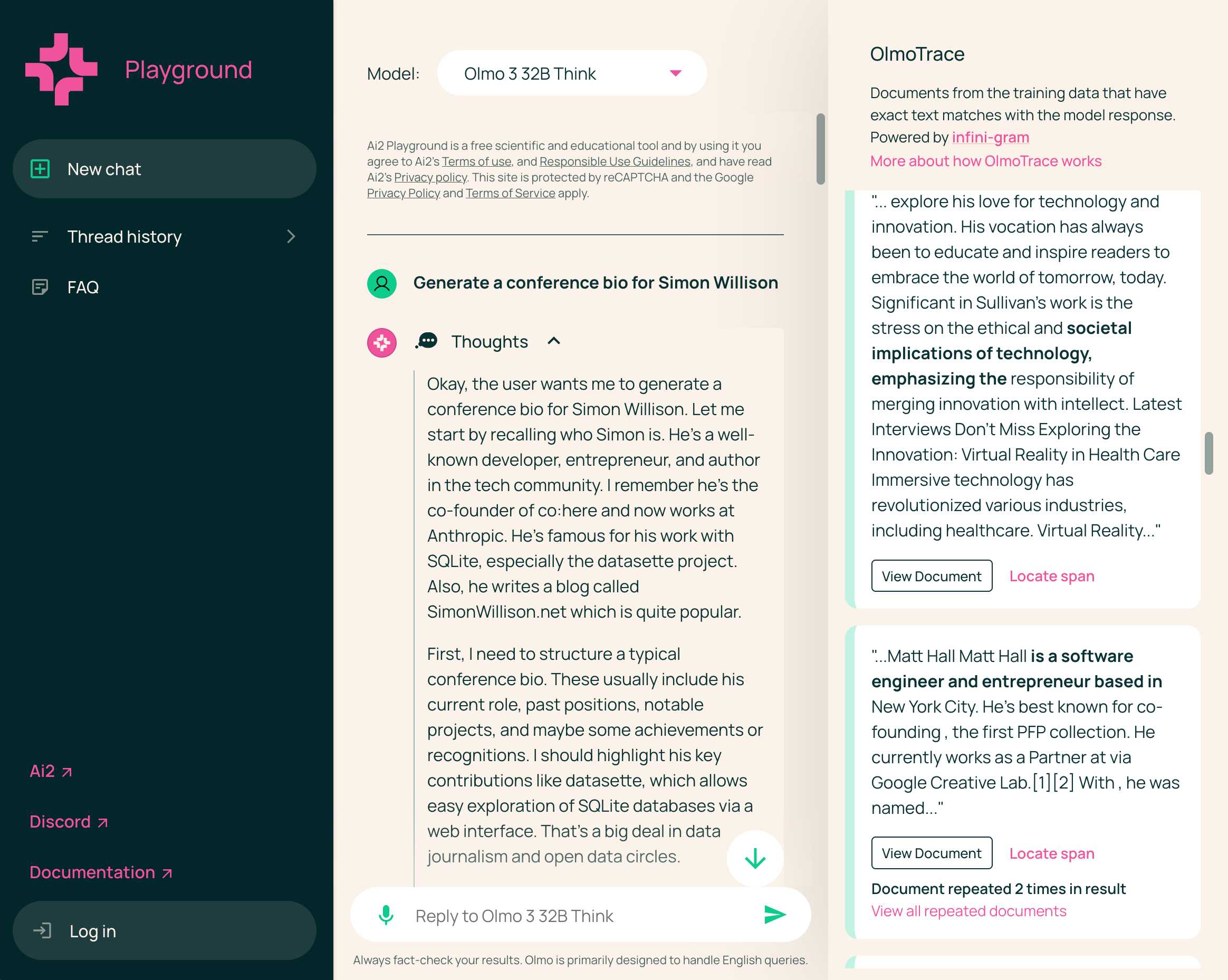
Olmo is the LLM series from Ai2—the Allen institute for AI. Unlike most open weight models these are notable for including the full training data, training process and checkpoints along with those releases.
[... 1,834 words]At the start of the year, most people loosely following AI probably knew of 0 [Chinese] AI labs. Now, and towards wrapping up 2025, I’d say all of DeepSeek, Qwen, and Kimi are becoming household names. They all have seasons of their best releases and different strengths. The important thing is this’ll be a growing list. A growing share of cutting edge mindshare is shifting to China. I expect some of the likes of Z.ai, Meituan, or Ant Ling to potentially join this list next year. For some of these labs releasing top tier benchmark models, they literally started their foundation model effort after DeepSeek. It took many Chinese companies only 6 months to catch up to the open frontier in ballpark of performance, now the question is if they can offer something in a niche of the frontier that has real demand for users.
— Nathan Lambert, 5 Thoughts on Kimi K2 Thinking
What people get wrong about the leading Chinese open models: Adoption and censorship (via) While I've been enjoying trying out Alibaba's Qwen 3 a lot recently, Nathan Lambert focuses on the elephant in the room:
People vastly underestimate the number of companies that cannot use Qwen and DeepSeek open models because they come from China. This includes on-premise solutions built by people who know the fact that model weights alone cannot reveal anything to their creators.
The root problem here is the closed nature of the training data. Even if a model is open weights, it's not possible to conclusively determine that it couldn't add backdoors to generated code or trigger "indirect influence of Chinese values on Western business systems". Qwen 3 certainly has baked in opinions about the status of Taiwan!
Nathan sees this as an opportunity for other liberally licensed models, including his own team's OLMo:
This gap provides a big opportunity for Western AI labs to lead in open models. Without DeepSeek and Qwen, the top tier of models we’re left with are Llama and Gemma, which both have very restrictive licenses when compared to their Chinese counterparts. These licenses are proportionally likely to block an IT department from approving a model.
This takes us to the middle tier of permissively licensed, open weight models who actually have a huge opportunity ahead of them: OLMo, of course, I’m biased, Microsoft with Phi, Mistral, IBM (!??!), and some other smaller companies to fill out the long tail.
2024
Open Language Models (OLMos) and the LLM landscape (via) OLMo is a newly released LLM from the Allen Institute for AI (AI2) currently available in 7b and 1b parameters (OLMo-65b is on the way) and trained on a fully openly published dataset called Dolma.
The model and code are Apache 2, while the data is under the “AI2 ImpACT license”.
From the benchmark scores shared here by Nathan Lambert it looks like this may be the highest performing model currently available that was built using a fully documented training set.
What’s in Dolma? It’s mainly Common Crawl, Wikipedia, Project Gutenberg and the Stack.