13 posts tagged “playwright”
2026
Agentic manual testing
The defining characteristic of a coding agent is that it can execute the code that it writes. This is what makes coding agents so much more useful than LLMs that simply spit out code without any way to verify it.
Never assume that code generated by an LLM works until that code has been executed.
Coding agents have the ability to confirm that the code they have produced works as intended, or iterate further on that code until it does. [... 1,231 words]
2025
Vibe scraping and vibe coding a schedule app for Open Sauce 2025 entirely on my phone
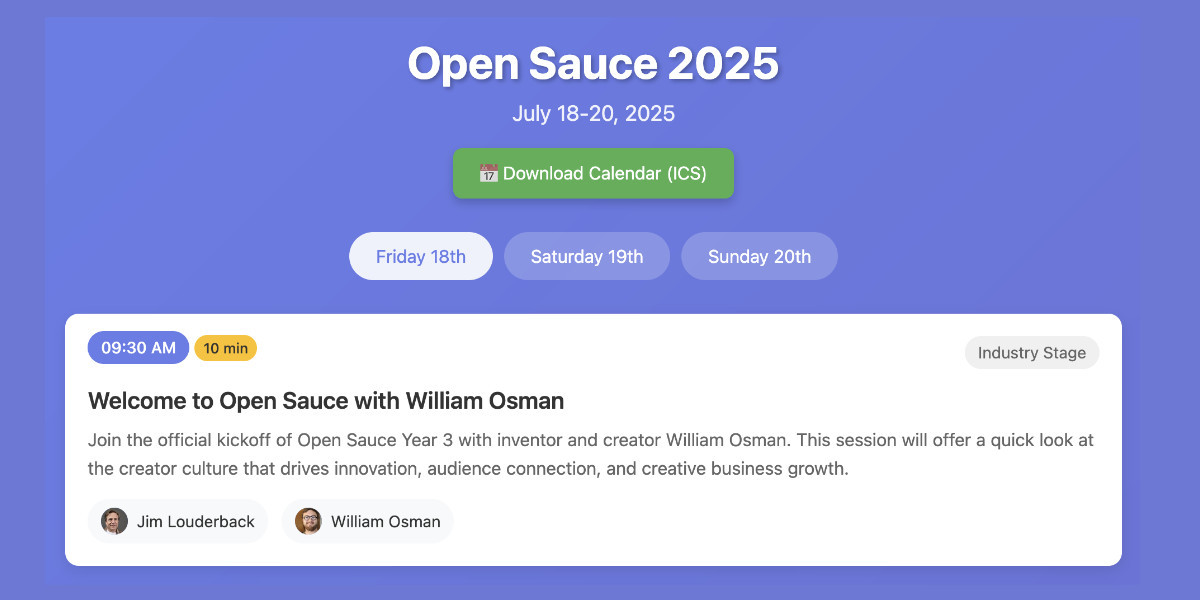
This morning, working entirely on my phone, I scraped a conference website and vibe coded up an alternative UI for interacting with the schedule using a combination of OpenAI Codex and Claude Artifacts.
[... 2,189 words]TIL: Using Playwright MCP with Claude Code. Inspired by Armin ("I personally use only one MCP - I only use Playwright") I decided to figure out how to use the official Playwright MCP server with Claude Code.
It turns out it's easy:
claude mcp add playwright npx '@playwright/mcp@latest'
claude
The claude mcp add command only affects the current directory by default - it gets persisted in the ~/.claude.json file.
Now Claude can use Playwright to automate a Chrome browser! Tell it to "Use playwright mcp to open a browser to example.com" and watch it go - it can navigate pages, submit forms, execute custom JavaScript and take screenshots to feed back into the LLM.
The browser window stays visible which means you can interact with it too, including signing into websites so Claude can act on your behalf.
shot-scraper 1.8. I've added a new feature to shot-scraper that makes it easier to share scripts for other people to use with the shot-scraper javascript command.
shot-scraper javascript lets you load up a web page in an invisible Chrome browser (via Playwright), execute some JavaScript against that page and output the results to your terminal. It's a fun way of running complex screen-scraping routines as part of a terminal session, or even chained together with other commands using pipes.
The -i/--input option lets you load that JavaScript from a file on disk - but now you can also use a gh: prefix to specify loading code from GitHub instead.
To quote the release notes:
shot-scraper javascriptcan now optionally load scripts hosted on GitHub via the newgh:prefix to theshot-scraper javascript -i/--inputoption. #173Scripts can be referenced as
gh:username/repo/path/to/script.jsor, if the GitHub user has created a dedicatedshot-scraper-scriptsrepository and placed scripts in the root of it, usinggh:username/name-of-script.For example, to run this readability.js script against any web page you can use the following:
shot-scraper javascript --input gh:simonw/readability \ https://simonwillison.net/2025/Mar/24/qwen25-vl-32b/
The output from that example starts like this:
{
"title": "Qwen2.5-VL-32B: Smarter and Lighter",
"byline": "Simon Willison",
"dir": null,
"lang": "en-gb",
"content": "<div id=\"readability-page-1\"...My simonw/shot-scraper-scripts repo only has that one file in it so far, but I'm looking forward to growing that collection and hopefully seeing other people create and share their own shot-scraper-scripts repos as well.
This feature is an imitation of a similar feature that's coming in the next release of LLM.
microsoft/playwright-mcp. The Playwright team at Microsoft have released an MCP (Model Context Protocol) server wrapping Playwright, and it's pretty fascinating.
They implemented it on top of the Chrome accessibility tree, so MCP clients (such as the Claude Desktop app) can use it to drive an automated browser and use the accessibility tree to read and navigate pages that they visit.
Trying it out is quite easy if you have Claude Desktop and Node.js installed already. Edit your claude_desktop_config.json file:
code ~/Library/Application\ Support/Claude/claude_desktop_config.json
And add this:
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}Now when you launch Claude Desktop various new browser automation tools will be available to it, and you can tell Claude to navigate to a website and interact with it.
I ran the following to get a list of the available tools:
cd /tmp
git clone https://github.com/microsoft/playwright-mcp
cd playwright-mcp/src/tools
files-to-prompt . | llm -m claude-3.7-sonnet \
'Output a detailed description of these tools'
The full output is here, but here's the truncated tool list:
Navigation Tools (
common.ts)
- browser_navigate: Navigate to a specific URL
- browser_go_back: Navigate back in browser history
- browser_go_forward: Navigate forward in browser history
- browser_wait: Wait for a specified time in seconds
- browser_press_key: Press a keyboard key
- browser_save_as_pdf: Save current page as PDF
- browser_close: Close the current page
Screenshot and Mouse Tools (
screenshot.ts)
- browser_screenshot: Take a screenshot of the current page
- browser_move_mouse: Move mouse to specific coordinates
- browser_click (coordinate-based): Click at specific x,y coordinates
- browser_drag (coordinate-based): Drag mouse from one position to another
- browser_type (keyboard): Type text and optionally submit
Accessibility Snapshot Tools (
snapshot.ts)
- browser_snapshot: Capture accessibility structure of the page
- browser_click (element-based): Click on a specific element using accessibility reference
- browser_drag (element-based): Drag between two elements
- browser_hover: Hover over an element
- browser_type (element-based): Type text into a specific element
shot-scraper 1.6 with support for HTTP Archives. New release of my shot-scraper CLI tool for taking screenshots and scraping web pages.
The big new feature is HTTP Archive (HAR) support. The new shot-scraper har command can now create an archive of a page and all of its dependents like this:
shot-scraper har https://datasette.io/
This produces a datasette-io.har file (currently 163KB) which is JSON representing the full set of requests used to render that page. Here's a copy of that file. You can visualize that here using ericduran.github.io/chromeHAR.
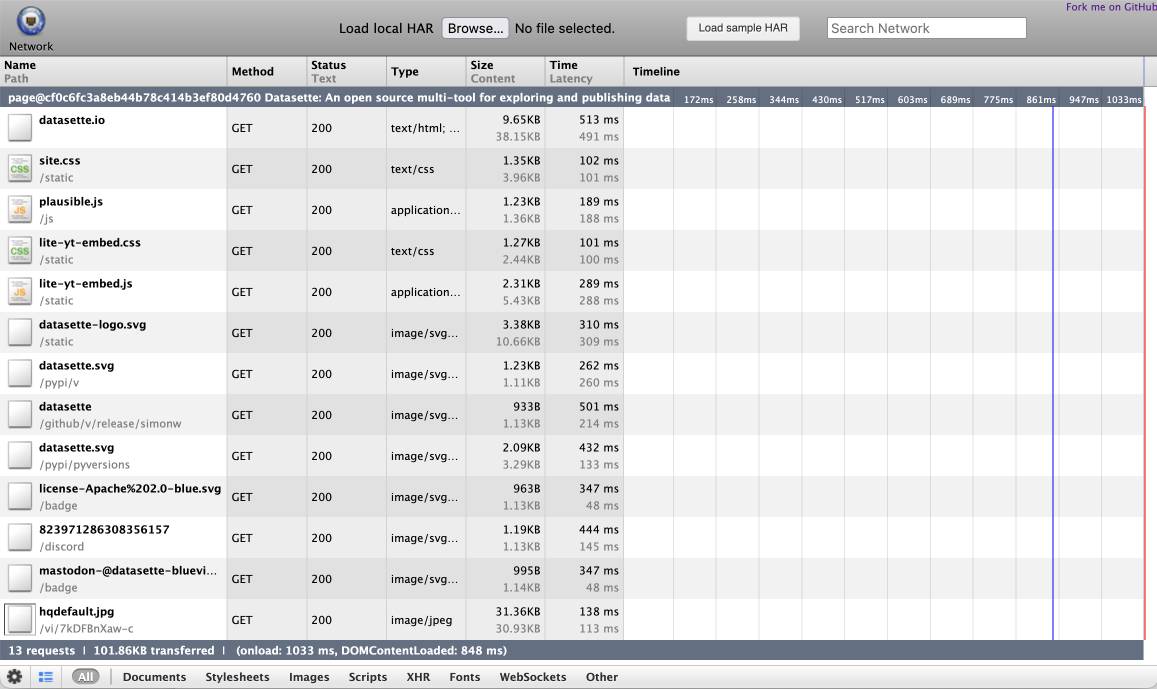
That JSON includes full copies of all of the responses, base64 encoded if they are binary files such as images.
You can add the --zip flag to instead get a datasette-io.har.zip file, containing JSON data in har.har but with the response bodies saved as separate files in that archive.
The shot-scraper multi command lets you run shot-scraper against multiple URLs in sequence, specified using a YAML file. That command now takes a --har option (or --har-zip or --har-file name-of-file), described in the documentation, which will produce a HAR at the same time as taking the screenshots.
Shots are usually defined in YAML that looks like this:
- output: example.com.png
url: http://www.example.com/
- output: w3c.org.png
url: https://www.w3.org/You can now omit the output: keys and generate a HAR file without taking any screenshots at all:
- url: http://www.example.com/
- url: https://www.w3.org/Run like this:
shot-scraper multi shots.yml --har
Which outputs:
Skipping screenshot of 'https://www.example.com/'
Skipping screenshot of 'https://www.w3.org/'
Wrote to HAR file: trace.har
shot-scraper is built on top of Playwright, and the new features use the browser.new_context(record_har_path=...) parameter.
2024
Guidepup. I’ve been hoping to find something like this for years. Guidepup is “a screen reader driver for test automation”—you can use it to automate both VoiceOver on macOS and NVDA on Windows, and it can both drive the screen reader for automated tests and even produce a video at the end of the test.
Also available: @guidepup/playwright, providing integration with the Playwright browser automation testing framework.
I’d love to see open source JavaScript libraries both use something like this for their testing and publish videos of the tests to demonstrate how they work in these common screen readers.
Weeknotes: datasette-test, datasette-build, PSF board retreat
I wrote about Page caching and custom templates in my last weeknotes. This week I wrapped up that work, modifying datasette-edit-templates to be compatible with the jinja2_environment_from_request() plugin hook. This means you can edit templates directly in Datasette itself and have those served either for the full instance or just for the instance when served from a specific domain (the Datasette Cloud case).
[... 757 words]2022
nat/natbot (via) Extremely devious hack by Nat Friedman: opens a browser using Playwright and then passes a DOM representation to GPT-3 in order to power a chat-style interface for driving the browser. Worth diving into the code to look at the prompt it uses, it’s fascinating.
Bundling binary tools in Python wheels
I spotted a new (to me) pattern which I think is pretty interesting: projects are bundling compiled binary applications as part of their Python packaging wheels. I think it’s really neat.
[... 903 words]@newshomepages (via) Ben Welsh used my shot-scraper tool and GitHub Actions to launch a Twitter bot which tweets screenshots of newspaper homepages on a scheduled basis. Ben says: “The tech is so easy, I was able to pull it off in a couple hours at zero cost. A decade ago I ran a similar project using the cloud resources of the day. [...] It costs thousands of dollars and the screenshots were of much lower quality. Incredible progress!”
Weeknotes: Distracted by Playwright
My goal for this week was to unblock progress on Datasette by finally finishing the dash encoding implementation I described last week. I was getting close, and then I got very distracted by Playwright.
[... 892 words]shot-scraper: automated screenshots for documentation, built on Playwright
shot-scraper is a new tool that I’ve built to help automate the process of keeping screenshots up-to-date in my documentation. It also doubles as a scraping tool—hence the name—which I picked as a complement to my git scraping and help scraping techniques.
[... 1,802 words]