6 posts tagged “sorting”
2026
Sorting algorithms. Today in animated explanations built using Claude: I've always been a fan of animated demonstrations of sorting algorithms so I decided to spin some up on my phone using Claude Artifacts, then added Python's timsort algorithm, then a feature to run them all at once. Here's the full sequence of prompts:
Interactive animated demos of the most common sorting algorithms
This gave me bubble sort, selection sort, insertion sort, merge sort, quick sort, and heap sort.
Add timsort, look up details in a clone of python/cpython from GitHub
Let's add Python's Timsort! Regular Claude chat can clone repos from GitHub these days. In the transcript you can see it clone the repo and then consult Objects/listsort.txt and Objects/listobject.c. (I should note that when I asked GPT-5.4 Thinking to review Claude's implementation it picked holes in it and said the code "is a simplified, Timsort-inspired adaptive mergesort".)
I don't like the dark color scheme on the buttons, do better
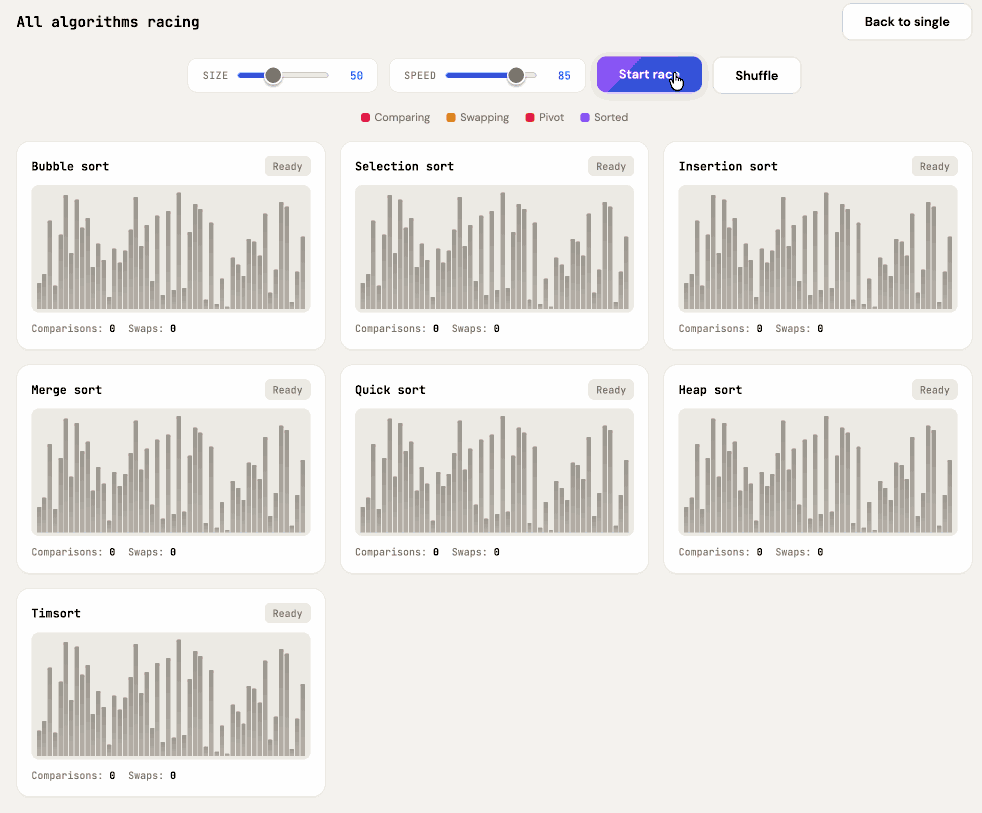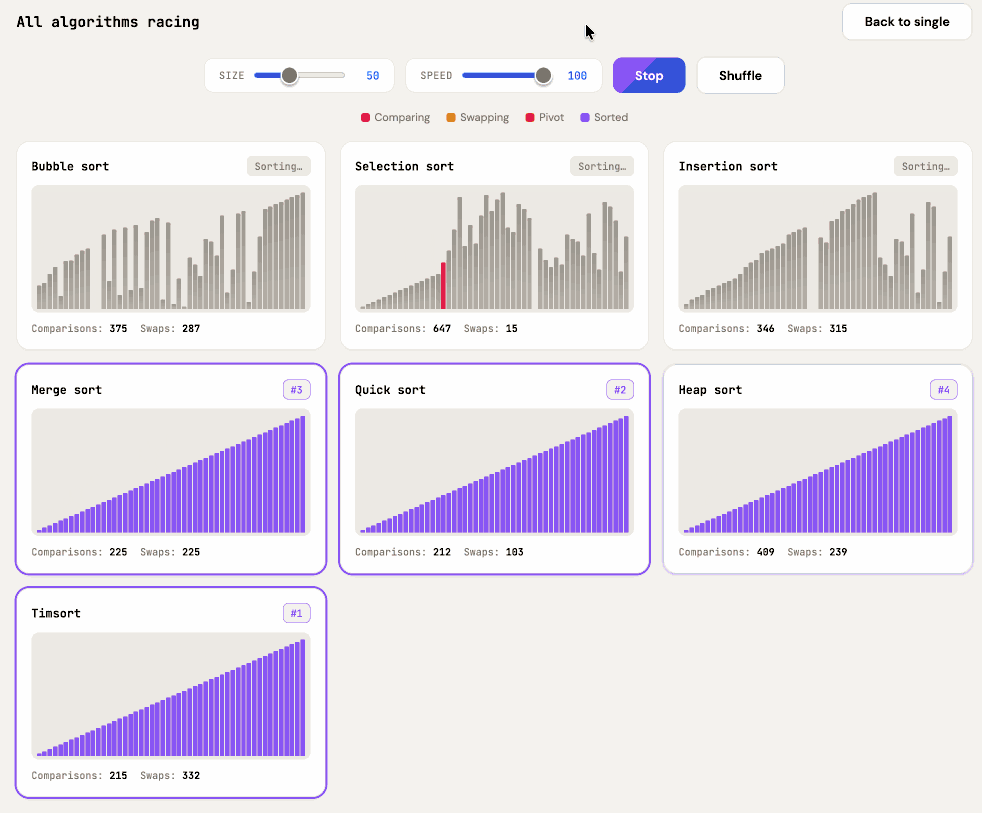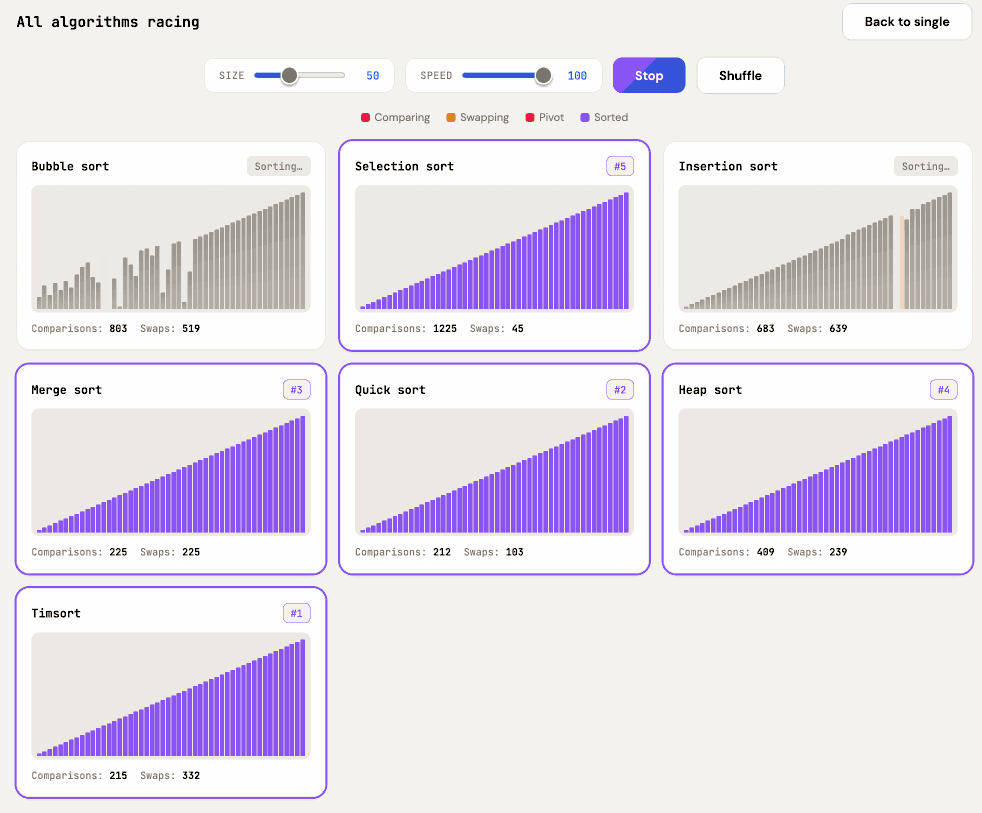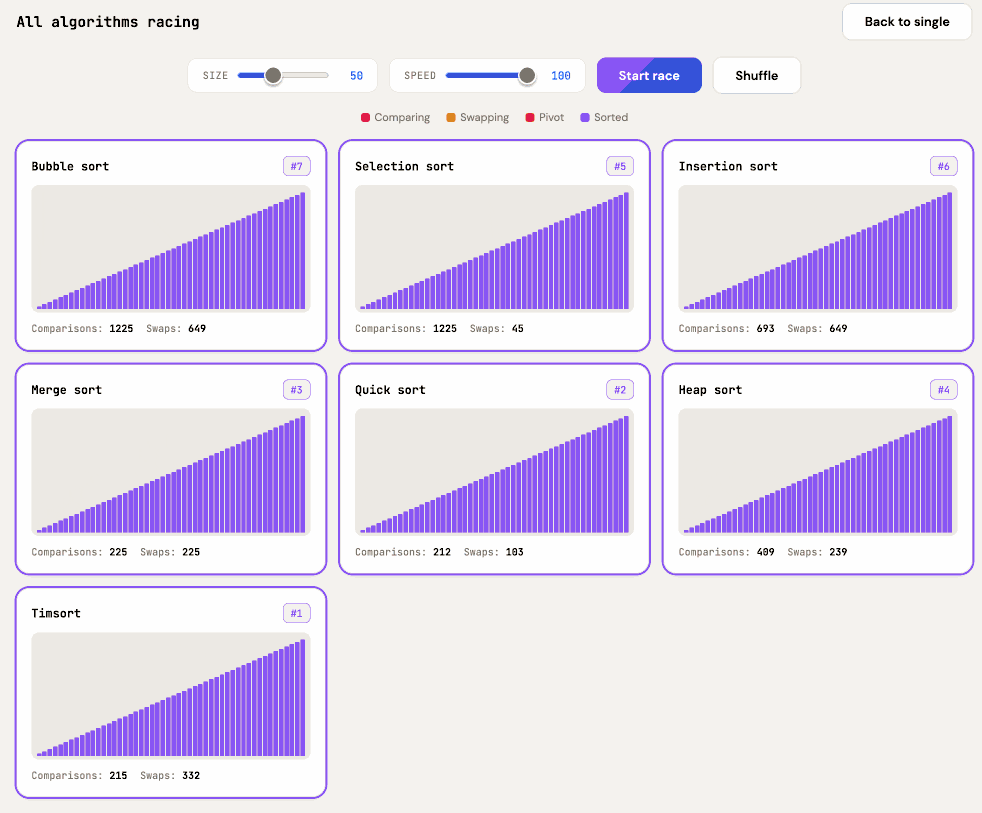
Also add a "run all" button which shows smaller animated charts for every algorithm at once in a grid and runs them all at the same time
It came up with a color scheme I liked better, "do better" is a fun prompt, and now the "Run all" button produces this effect:
2025
How uv got so fast.
Andrew Nesbitt provides an insightful teardown of why uv is so much faster than pip. It's not nearly as simple as just "they rewrote it in Rust" - uv gets to skip a huge amount of Python packaging history (which pip needs to implement for backwards compatibility) and benefits enormously from work over recent years that makes it possible to resolve dependencies across most packages without having to execute the code in setup.py using a Python interpreter.
Two notes that caught my eye that I hadn't understood before:
HTTP range requests for metadata. Wheel files are zip archives, and zip archives put their file listing at the end. uv tries PEP 658 metadata first, falls back to HTTP range requests for the zip central directory, then full wheel download, then building from source. Each step is slower and riskier. The design makes the fast path cover 99% of cases. None of this requires Rust.
[...]
Compact version representation. uv packs versions into u64 integers where possible, making comparison and hashing fast. Over 90% of versions fit in one u64. This is micro-optimization that compounds across millions of comparisons.
I wanted to learn more about these tricks, so I fired up an asynchronous research task and told it to checkout the astral-sh/uv repo, find the Rust code for both of those features and try porting it to Python to help me understand how it works.
Here's the report that it wrote for me, the prompts I used and the Claude Code transcript.
You can try the script it wrote for extracting metadata from a wheel using HTTP range requests like this:
uv run --with httpx https://raw.githubusercontent.com/simonw/research/refs/heads/main/http-range-wheel-metadata/wheel_metadata.py https://files.pythonhosted.org/packages/8b/04/ef95b67e1ff59c080b2effd1a9a96984d6953f667c91dfe9d77c838fc956/playwright-1.57.0-py3-none-macosx_11_0_arm64.whl -v
The Playwright wheel there is ~40MB. Adding -v at the end causes the script to spit out verbose details of how it fetched the data - which looks like this.
Key extract from that output:
[1] HEAD request to get file size...
File size: 40,775,575 bytes
[2] Fetching last 16,384 bytes (EOCD + central directory)...
Received 16,384 bytes
[3] Parsed EOCD:
Central directory offset: 40,731,572
Central directory size: 43,981
Total entries: 453
[4] Fetching complete central directory...
...
[6] Found METADATA: playwright-1.57.0.dist-info/METADATA
Offset: 40,706,744
Compressed size: 1,286
Compression method: 8
[7] Fetching METADATA content (2,376 bytes)...
[8] Decompressed METADATA: 3,453 bytes
Total bytes fetched: 18,760 / 40,775,575 (100.0% savings)
The section of the report on compact version representation is interesting too. Here's how it illustrates sorting version numbers correctly based on their custom u64 representation:
Sorted order (by integer comparison of packed u64):
1.0.0a1 (repr=0x0001000000200001)
1.0.0b1 (repr=0x0001000000300001)
1.0.0rc1 (repr=0x0001000000400001)
1.0.0 (repr=0x0001000000500000)
1.0.0.post1 (repr=0x0001000000700001)
1.0.1 (repr=0x0001000100500000)
2.0.0.dev1 (repr=0x0002000000100001)
2.0.0 (repr=0x0002000000500000)
2012
How can I sort a huge amount of numbers?
Sorting large amounts of data is one of the first exercises you’ll see described in any Hadoop or map/reduce tutorial—so I’d suggest taking a look at Hadoop.
[... 44 words]2009
Visualising Sorting Algorithms. Aldo Cortesi dislikes animations of sorting algorithms, so he designed a beautiful technique for statically visualising them instead (using Python and Cairo to generate the images).
2008
Animated Sorting Algorithms (via) JavaScript animations of various sorting algorithms, running against four different initial conditions (random, nearly ordered, reversed and few unique). I wish I’d had this during my computer science degree.